способы и виды автоматизации сборки
Структурирование информации – разбираемся в термине
О том, что такое структурирование, знают многие. «Разложить по полочкам» – значит «структурировать». Структурирование информации – это разделение её по отдельным, схожим критериям на группы, а также выстраивание связей логических цепочек между полученными группами. Иными словами, структурировать информацию означает создать некий визуальный скелет, с помощью которого будет легко запомнить ту или иную информацию. Как нетрудно догадаться, нужно оно для того, чтобы проще, легче было её запомнить. Причём информация может являться абсолютно любого типа: текст, числа, учебный материал, развлекательный.
Любая информация нуждается в структурировании, если вы хотите быстро для себя её зафиксировать. Как это делать, читаем далее.
Принципы структурирования информации
В основе данного понятия – её упрощение. Иными словами, нам нужно данный сложный массив логических связей, цепочек разобрать на простые элементы. Важно знать два принципа – на них строится всё упрощение информации:
Важно знать два принципа – на них строится всё упрощение информации:
- Принцип первый: всю имеющуюся информацию необходимо разделить на группы, подгруппы в соответствии с отдельно взятыми критериями. Здесь всё просто: берём какой-либо критерий, признак, на котором построена информация – например, раздел «Числительные» в иностранных языках, после чего подгоняем всю имеющуюся информацию под написанный критерий – запоминаем только иностранные числительные.
- Принцип второй: группы и подгруппы должны быть тесно связаны логическими цепочками, ассоциативными рядами или же выстроены в соответствии с определёнными правилами: по степени важности, по времени, форме. Те же иностранные числительные можно «связать» похожим звучанием, правилами построения их форм.
Методы и виды структурирования информации
Отталкиваясь от указанных принципов, приведём самые популярные и зарекомендовавшие себя методы получения структурированной информации.
«Карта памяти» – метод Бьюзена
Метод довольно прост. Он заключается в построении блок-схемы – в ней будет наглядно изображена вся информация. В основе этого алгоритма лежит автоматизация сборки.
Он заключается в построении блок-схемы – в ней будет наглядно изображена вся информация. В основе этого алгоритма лежит автоматизация сборки.
Чтобы изобразить блок-схему, необходимо взять лист бумаги (ватман), ручку. При желании – для большей наглядности – стоит взять ещё цветные карандаши, фломастеры. В центре листа обозначьте название материала, который необходимо запомнить. Если это учебник «История Древнего Египта», так и пишите. «Принцип работы вариаторной коробки в автомобиле» или «Как работает программа 1С» – пишите. Советуется слова заменить символами или картинками, которые точно будут передавать суть темы. Ту же вариаторную коробку наглядно изобразите на бумаге, а 1С – просто обозначить символом программы. При желании можно вырезать, наклеить картинки – как угодно. Лишь бы вам было проще запомнить. Далее, нужно для выбранной темы построить ряд ассоциативных рядов. История Древнего мира – это цепочки «Периоды», «Народы», «Войны». В каждом блоке перечисляем ключевые моменты. И так далее по такому принципу. За счёт наглядности, разбивания материала на блоки запоминание информации произойдёт довольно быстро.
И так далее по такому принципу. За счёт наглядности, разбивания материала на блоки запоминание информации произойдёт довольно быстро.
«Римская комната» метод Цицерона
Данный метод существует ещё со времён римского философа Цицерона, поэтому в его эффективности сомневаться не стоит. Суть метода в том, что материал разбивается на отдельные блоки, а затем мысленно расставляется в знакомой вам комнате – скажем, в вашей кухне.
Важно! Все блоки надо расставляться в строго определённом порядке.
Как только вы «расставите» блоки по комнате, в вашей памяти зафиксируется простая цепочка информации, которую вы легко запомните. И теперь, чтобы обратиться к информации, вам достаточно будет вспомнить вашу кухню. Кстати, под кухней необязательно выбирать комнату: используйте улицу, парк, даже шкаф. Главное, чтобы вы чётко понимали, помнили структуру помещения, объекта.
«7плюс/минус2»: метод Миллера
Этот интересный метод основан на способности человека запоминать 9 двоичных чисел, 8 – десятичных, 7 букв, 5 слов, причём это кратковременная память.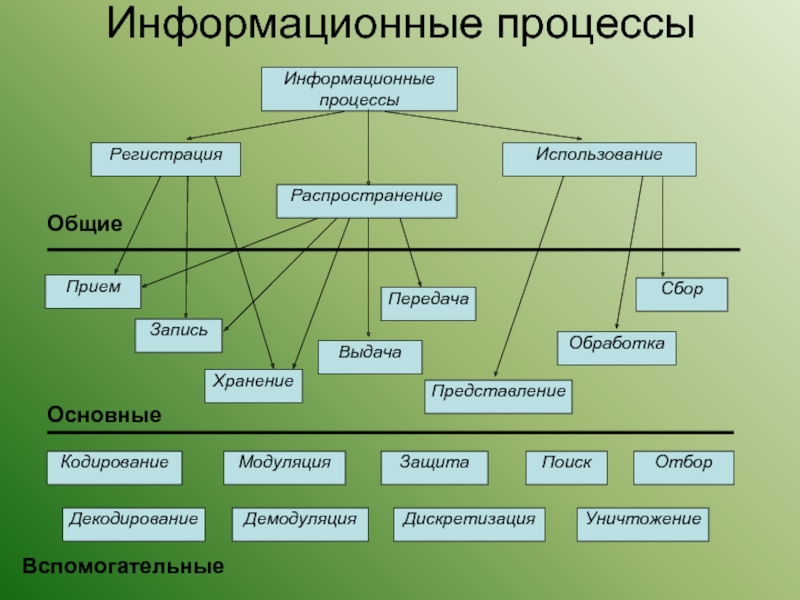 Таким образом, данными способом получается группу из семи плюс/минус два элементов – её мы можем использовать для создания групп и подгрупп. Однако данный метод чаще применяется для тренировки памяти, но в структурировании информации его тоже частенько используют.
Таким образом, данными способом получается группу из семи плюс/минус два элементов – её мы можем использовать для создания групп и подгрупп. Однако данный метод чаще применяется для тренировки памяти, но в структурировании информации его тоже частенько используют.
Отдельно стоит поговорить про эффекты запоминания информации, поскольку они тоже помогают её структурировать.
Эффект Ресторффа – эффект изоляции. В нашей памяти произвольно выделяется объект, отличающийся от остальных какими-то выдающимися признаками. Среди флагов всех стран самый запоминающийся – флаг Канады, потому что ни на одном флаге больше нет кленового листа. Флаг Японии – тот же принцип: алый круг посередине. Можно также выделить какой-либо отдельный признак – так запомнить объект намного легче.
Эффект края основан на автоматизированной сборке и на том, что мы привыкли запоминать ту информацию, которая находится в начале, а также в конце структурного ряда. Мы подсознательно лучше запоминаем то, что у нас было впервые: первая любовь, первая учительница, даже зарплата. То же самое касается того, что случилось в последний раз. Эффект края может использоваться в структурировании информации, если на первое, последнее место выносить наиболее яркие, значимые моменты – на них будет строиться каркас мысленных связей.
То же самое касается того, что случилось в последний раз. Эффект края может использоваться в структурировании информации, если на первое, последнее место выносить наиболее яркие, значимые моменты – на них будет строиться каркас мысленных связей.
Все приведённые методы, эффекты структурирования информации должны создаваться таким образом, чтобы вам, и только вам было удобнее запоминать информацию. Сочетать все перечисленные методы – вполне возможно.
В заключение отметим, что структурирование информации – вещь полезная, нужная, особенно если требуется запоминать большие объёмы информации. В этой статье мы постарались максимально подробно рассказать об этом понятии, надеемся, полученные знания пойдут вам на пользу.
Урок №3. Информационные процессы. Измерение информации (9 класс)
Информационные процессы.
Основные темы параграфа:
• основные информационные процессы;
• хранение информации;
• передача информации;
• обработка информации;
• поиск информации;
• информационные процессы в живой природе.
Основные информационные процессы
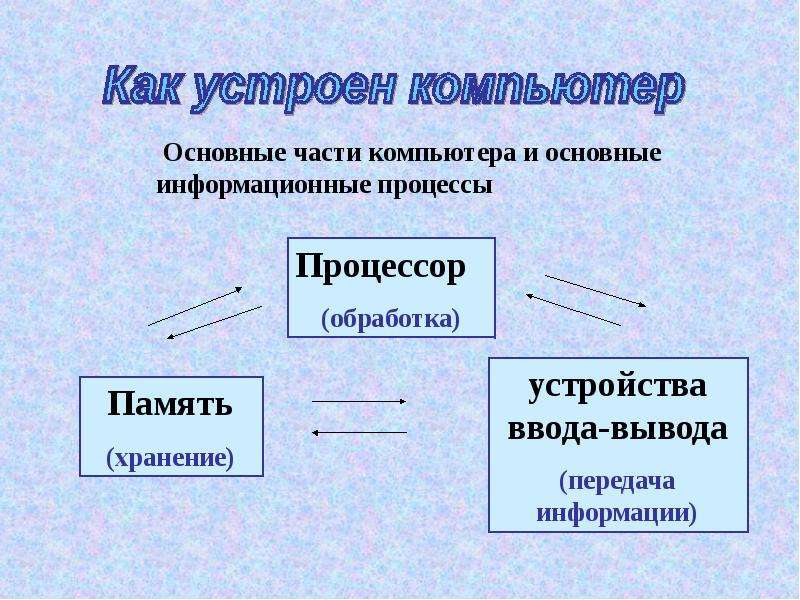
А теперь зададимся вопросом: что делает человек с полученной информацией? Во-первых, он ее стремится сохранить: запомнить или записать. Во-вторых, он передает ее другим людям. В-третьих, человек сам создает новые знания, новую информацию, выполняя обработку данной ему информации. Какой бы информационной деятельностью люди не занимались, вся она сводится к осуществлению трех процессов: хранению, передаче и обработке информации (рис. 1.3).
Хранение информации
Люди хранят информацию либо в собственной памяти (иногда говорят — «в уме»), либо на каких-то внешних носителях. Чаще всего — на бумаге.
Те сведения, которые мы помним, всегда нам доступны. Например, если вы запомнили таблицу умножения, то вам никуда не нужно заглядывать для того, чтобы ответить на вопрос: сколько будет пятью пять? Каждый человек помнит свой домашний адрес, номер телефона, а также адреса и телефоны близких людей.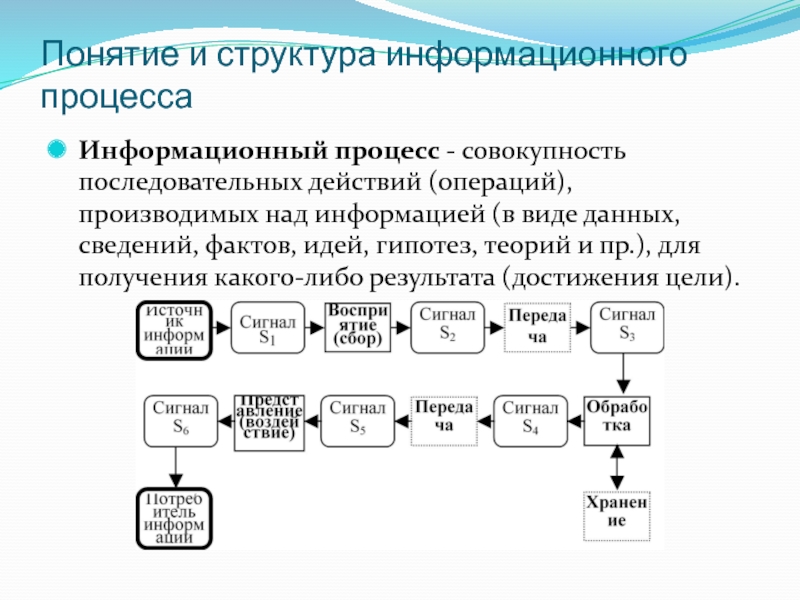 Если же понадобился адрес или телефон, которого мы не
Если же понадобился адрес или телефон, которого мы не
помним, то обращаемся к записной книжке или к телефонному справочнику.
Память человека можно условно назвать оперативной. Здесь слово «оперативный» является синонимом слову «быстрый». Человек быстро воспроизводит сохраненные в памяти знания. Свою память мы еще можем назвать внутренней памятью. Тогда информацию, сохраненную на внешних носителях (в записных книжках, справочниках, энциклопедиях, магнитных записях), можно назвать нашей внешней памятью.
Человек нередко что-то забывает. Информация на внешних носителях хранится дольше, надежнее. Именно с помощью внешних носителей люди передают свои знания из поколения в поколение.
Передача информации
Распространение информации между людьми происходит в процессе ее передачи. Передача может происходить при непосредственном разговоре между людьми, через переписку, с помощью технических средств связи: телефона, радио, телевидения, компьютерной сети.
В передаче информации всегда участвуют две стороны: есть источник и есть приемник информации. Источник передает (отправляет) информацию, а приемник ее получает (воспринимает). Читая книгу или слушая учителя, вы являетесь приемниками информации, работая над сочинением по литературе или отвечая на уроке, — источником информации. Каждому человеку
Передача информации от источника к приемнику всегда происходит через какой-то канал передачи. При непосредственном разговоре — это
звуковые волны; при переписке — это почтовая связь; при телефонном разговоре — это система телефонной связи. В процессе передачи информация может искажаться или теряться, если информационные каналы имеют плохое качество или на линии связи действуют помехи (шумы). Многие знают, как трудно бывает общаться при плохой телефонной связи.
Обработка информации
Обработка информации — третий вид информационных процессов. Вот хорошо вам знакомый пример — решение математической задачи: даны значения длин двух катетов прямоугольного треугольника, нужно определить его третью сторону — гипотенузу. Чтобы решить задачу, ученик кроме исходных данных должен знать математическое правило, с помощью которого
Вот хорошо вам знакомый пример — решение математической задачи: даны значения длин двух катетов прямоугольного треугольника, нужно определить его третью сторону — гипотенузу. Чтобы решить задачу, ученик кроме исходных данных должен знать математическое правило, с помощью которого
Вычисление — лишь один из вариантов обработки информации. Новую информацию можно вывести не только путем математических расчетов. Вспомните истории Шерлока Холмса, героя книг Конан Дойля. Имея в качестве исходной информации часто очень запутанные показания свидетелей и косвенные улики, Холмс с помощью логических рассуждений прояснял всю картину событий и разоблачал преступника. Логические рассуждения — это еще один способ обработки информации.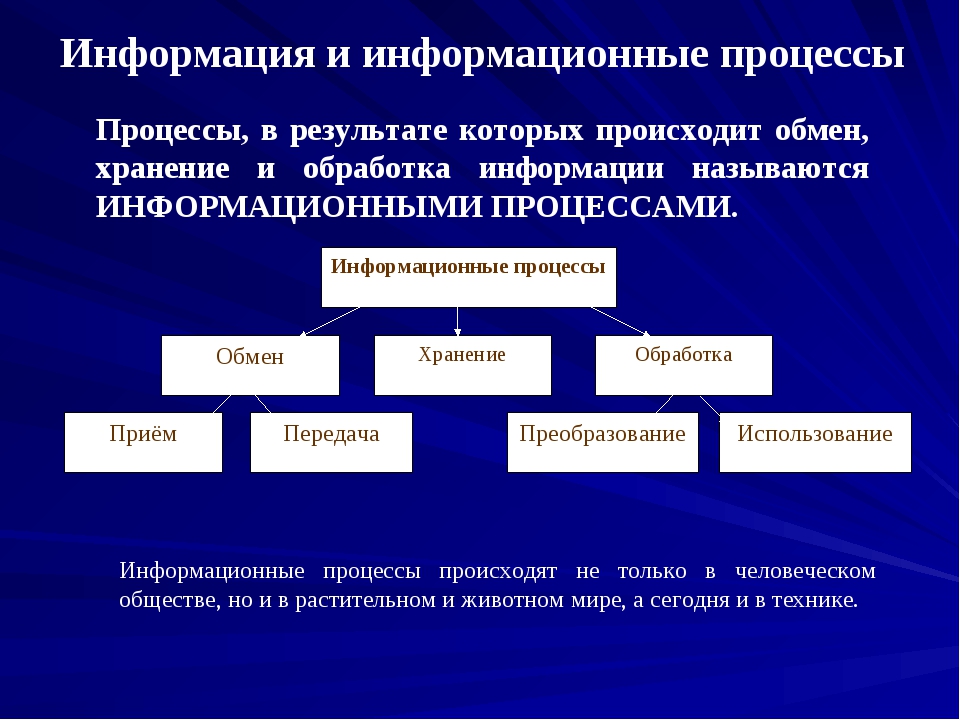
Процесс обработки информации не всегда связан с получением каких-то новых сведений. Например, при переводе текста с одного языка на другой происходит обработка информации, изменяющая ее форму, но не содержание.
К этому же виду обработки относится кодирование информации. Кодирование — это преобразование представления информации из одной символьной формы в другую, удобную для ее хранения, передачи или обработки.
Особенно широко понятие кодирования стало употребляться с развитием технических средств хранения, передачи и обработки информации (телеграф, радио, компьютеры). Например, в начале XX века телеграфные сообщения кодировались и передавались с помощью азбуки Морзе. Иногда кодирование производится в целях засекречивания содержания текста. В таком случае его называют шифрованием.
Еще одной разновидностью обработки информации является ее сортировка (иногда говорят — упорядочение). Например, вы решили записать адреса и телефоны всех своих одноклассников на отдельные карточки.
порядке по фамилиям. В информатике организация данных по какому-либо правилу, связывающему ее в единое целое, называется структурированием.
Поиск информации
Нам с вами очень часто приходится заниматься поиском информации: в словаре искать перевод иностранного слова, в телефонном справочнике — номер телефона, в железнодорожном расписании — время отправления поезда, в учебнике математики — нужную формулу, на схеме метро — маршрут движения, в библиотечном каталоге — сведения о нужной книге. Можно
привести еще много примеров. Все это — процессы поиска информации на внешних носителях: книгах, схемах, таблицах, картотеках.
Информационные процессы в живой природе
Можно ли утверждать, что с информацией и информационными процессами связана только жизнь человека? Конечно, нет! Науке известно множество фактов, подтверждаюaщих протекание информационных процессов в живой природе.
знакомых людей от незнакомых. Многие животные обладают обостренным обонянием, несущим им ценную информацию. Конечно, способности животных к обработке информации значительно ниже, чем у человека. Однако многие факты разумного поведения свидетельствуют об их способности к определенным умозаключениям.
Коротко о главном
Информационная деятельность человека связана с осуществлением трех видов информационных процессов: хранением, передачей и обработкой информации.
Человек хранит информацию в собственной памяти (внутренняя, оперативная информация) и на внешних носителях: бумаге, магнитной ленте и пр. (внешняя информация).
Процесс передачи информации протекает от источника к приемнику по информационным каналам связи.
Процесс обработки информации связан с получением новой информации, изменением формы или структуры имеющейся информации. Важным информационным процессом является поиск информации. Информационные процессы протекают и в живой природе.
Важным информационным процессом является поиск информации. Информационные процессы протекают и в живой природе.
Вопросы и задания
1. Приведите свои примеры профессий, в которых основным видом деятельности является работа с информацией.
2. Назовите три основных вида информационных процессов.
3. Почему информацию, которую мы «помним наизусть», можно назвать оперативной? Приведите примеры оперативной информации, которой вы владеете.
4. Приведите примеры ситуаций, в которых вы являетесь источником информации, приемником информации. Какую роль за сегодняшний день вам чаще приходилось выполнять?
5. Приведите различные примеры процесса обработки информации. Определите, по каким правилам она производится в каждом примере.
Измерение информации
Основные темы параграфа:
• алфавитный подход к измерению информации;
• алфавит, мощность алфавита;
• информационный вес символа;
• информационный объем текста и единицы информации.
А теперь обсудим вопрос о том, как можно измерять информацию. Существует несколько подходов к измерению информации. Здесь мы рассмотрим только один, который называется алфавитным подходом.
Алфавитный подход к измерению информации
Вам хорошо известно, что для измерения таких величин, как, например, расстояние, масса, время, существуют эталонные единицы. Для расстояния — это метр, для массы — килограмм, для времени — секунда. Измерение происходит путем сопоставления измеряемой величины с эталонной единицей. Сколько раз эталонная единица укладывается в измеряемой величине, таков и результат измерения. Следовательно, и для измерения
Алфавитный подход позволяет измерять информационный объем текста на некотором языке (естественном или формальном), не связанный с содержанием этого текста.
Алфавит. Мощность алфавита
Под алфавитом мы будем понимать набор букв, знаков препинания, цифр, скобок и др. символов, используемых в тексте. В алфавит также следует включить и пробел, т. е. пропуск между словами.
символов, используемых в тексте. В алфавит также следует включить и пробел, т. е. пропуск между словами.
Полное число символов в алфавите принято называть мощностью алфавита. Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54: 33 буквы + 10 цифр + 11 знаков препинания, скобки, пробел.
Информационный вес символа
При алфавитном подходе считается, что каждый символ текста имеет определенный информационный вес. Информационный вес символа зависит от мощности алфавита. А каким может быть наименьшее число символов в алфавите? Оно равно двум! Скоро вы узнаете, что такой алфавит используется в компьютере. Он содержит всего 2 символа, которые обозначаются цифрами «0» и «1». Его называют двоичным алфавитом. Изучая устройство и работу компьютера, вы узнаете, как с помощью всего двух символов можно представить любую информацию.
Информационный вес символа двоичного алфавита принят за единицу информации и называется 1 бит.
С увеличением мощности алфавита увеличивается информационный вес символов этого алфавита. Так один символ из четырехсимволъного алфавита (N = 4) «весит» 2 бита. Объяснение этому можно дать следующее: все символы такого алфавита можно закодировать всеми возможными комбинациями из двух цифр двоичного алфавита. Комбинацию из нескольких (двух, трех и т. д.) знаков двоичного алфавита назовем двоичным кодом.
Используя три двоичные цифры, можно составить 8 различных комбинаций.
Следовательно, если мощность алфавита равна 8, то информационный вес одного символа равен 3 битам.
Четырехзначным двоичным кодом может быть закодирован каждый символ из 16-символьного алфавита. И так далее.
Найдем зависимость между мощностью алфавита (N) и количеством знаков в коде (b) — разрядностью двоичного кода.
Заметим, что 2 = 21, 4 = 22, 8 = 23, 16 = 24.
В общем виде это записывается следующим образом:
N= 2b.Разрядность двоичного кода — это и есть информационный вес символа.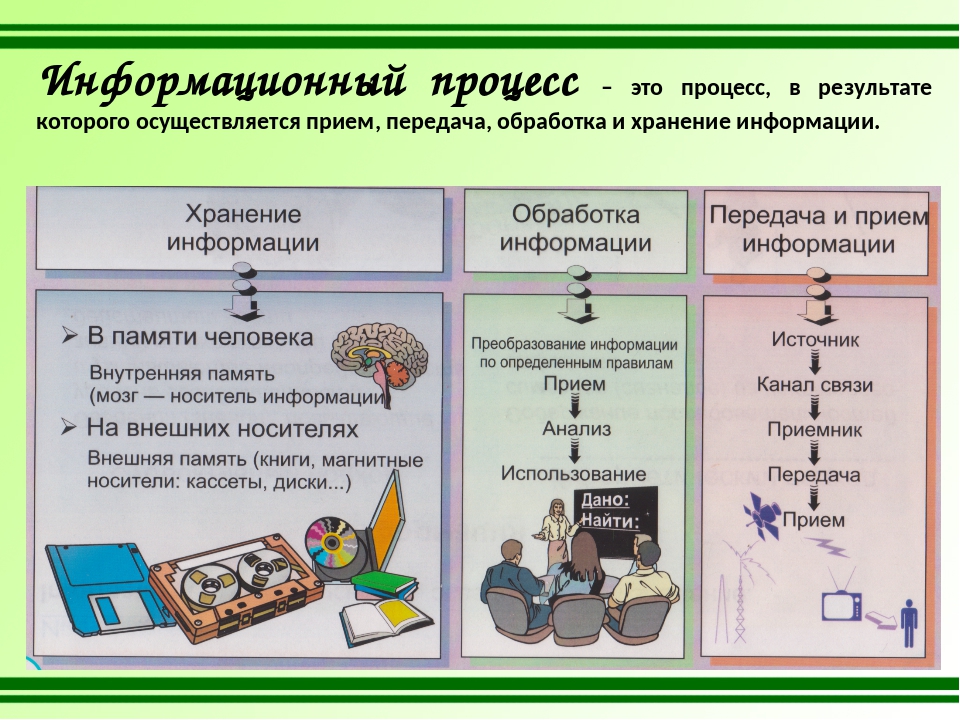
Информационный вес каждого символа, выраженный в битах (b), и мощность алфавита (N) связаны между собой формулой: N= 2b.
Информационный объем текста и единицы информации
Информационный объем текста складывается из информационных весов составляющих его символов, Например, следующий текст, записанный с помощью двоичного алфавита:
1101001011000101110010101101000111010010содержит 40 символов, следовательно, его информационный объем равен 40 битам.
Сегодня для подготовки текстовых документов чаще всего применяются компьютеры. Алфавит, из которого составляется такой «компьютерный текст», содержит 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: строчные и прописные латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания и пр.
Поскольку 256 = 28, то один символ компьютерного алфавита «весит» 8 битов. Причем 8 битов информации — это настолько характерная величина, что ей даже присвоили свое название — байт.
1 байт = 8 битов.
Легко подсчитать информационный объем текста, если известно, что информационный вес одного символа равен 1 байту. Надо просто сосчитать число символов в тексте. Полученное значение и будет информационным объемом текста, выраженным в байтах.
Например, небольшая книжка, подготовленная с помощью компьютера, содержит 150 страниц. На каждой странице — 40 строк, в каждой строке — 60 символов (включая пробелы между словами). Значит, страница содержит 40 х 60 = 2400 байтов информации. Для вычисления информационного объема всей книги нужно полученную величину умножить на число страниц:
2400 байтов · 150 = 360 000 байтов.
Уже на таком примере видно, что байт — «мелкая» единица. А представьте, если нужно, например, измерить информационный объем целой библиотеки? В байтах это окажется громадным числом!
Для измерения больших информационных объемов используются более крупные единицы:
1 килобайт = 1 Кб = 210 байтов = 1024 байта
1 мегабайт = 1 Мб = 210 Кб = 1024 Кб
1 гигабайт = 1 Гб = 210 Мб = 1024 Мб
Следовательно, информационный объем вышеупомянутой книги равен приблизительно 360 килобайтам. А если посчитать точнее, то получится:
А если посчитать точнее, то получится:
В заключение еще раз обратим внимание на важное свойство рассмотренного здесь алфавитного подхода. При его использовании содержательная сторона текста в учет не берется. Текст, состоящий из бессмысленного сочетания символов, будет иметь ненулевой информационный объем.
Коротко о главном
Алфавитный подход — это способ измерения информационного объема текста, не связанного с его содержанием.
Алфавит — это вся совокупность символов, используемых в некотором языке для представления информации. Мощность алфавита — это число символов в нем.
1 бит — информационный вес одного символа двухсимволъного алфавита (N= 2).
Информационный вес символа (разрядность двоичного кода) (b) и мощность алфавита (N) связаны формулой: N = 2b.
Информационный объем текста равен сумме информационных весов всех символов, составляющих текст.
1 байт — информационный вес символа из алфавита мощностью 28 = 256 символов.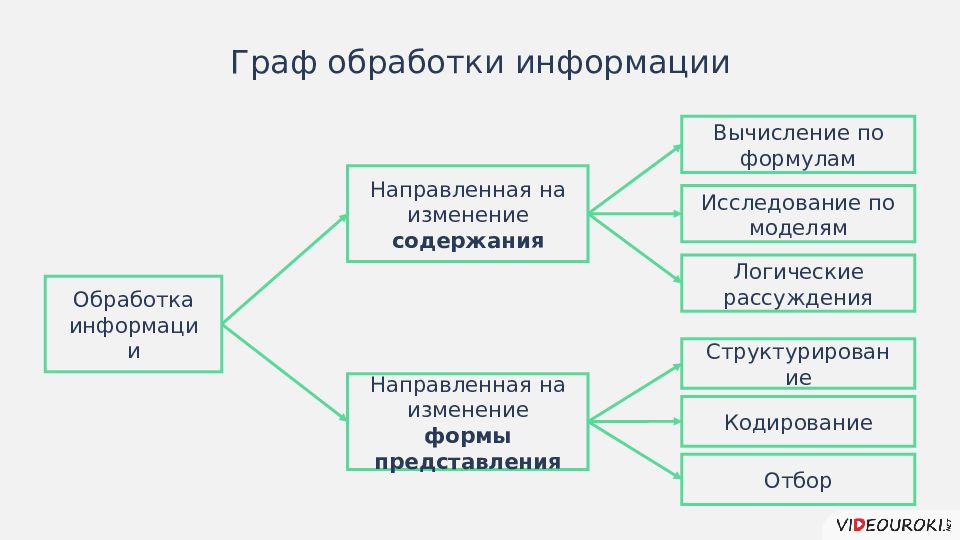 1 байт — 8 битов.
1 байт — 8 битов.
Байт, килобайт, мегабайт, гигабайт — единицы измерения информации. Каждая следующая единица больше предыдущей в 1024 (210) раза.
Вопросы и задания
1. Что такое алфавит?
2. Что такое мощность алфавита?
3. Как определяется информационный объем текста при использовании алфавитного подхода?
4. Текст составлен с использованием алфавита мощностью 64 символа и содержит 100 символов. Каков информационный объем текста?
5. Что такое байт, килобайт, мегабайт.
6. Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Кб. Сколько символов содержит этот текст?
7. Два текста содержат одинаковое количество символов. Первый текст составлен в алфавите мощностью 32 символа, второй — мощностью 64 символа, Во сколько раз отличаются информационные объемы этих текстов?
Домашнее задание №3 Информационные процессы
Домашнее задание №4 Измерение информации
Редактировалось Дата:Основные информационные процессы и их реализация с помощью компьютеров
Хранение информации.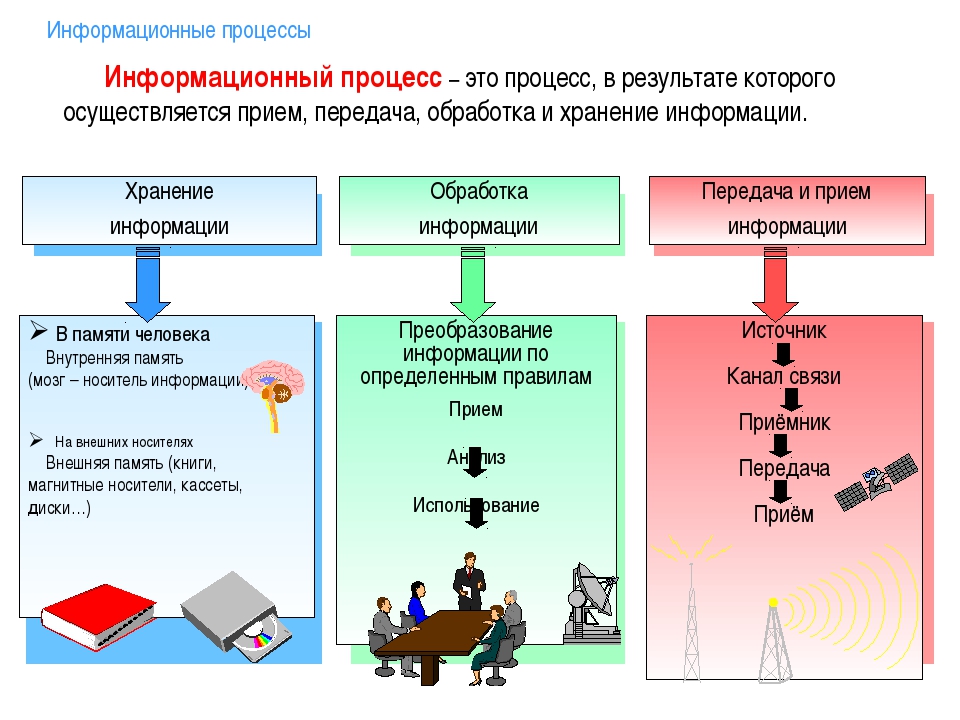 Люди хранят информацию либо в собственной памяти (иногда говорят — «в уме»), либо на каких-то внешних носителях. Чаще всего — на бумаге.
Люди хранят информацию либо в собственной памяти (иногда говорят — «в уме»), либо на каких-то внешних носителях. Чаще всего — на бумаге.
Те сведения, которые мы помним, всегда нам доступны. Например, если вы запомнили таблицу умножения, то вам никуда не нужно заглядывать для того, чтобы ответить на вопрос: сколько будет пятью пять? Каждый человек помнит свой домашний адрес, номер телефона, а также адреса и телефоны близких людей. Если же понадобился адрес или телефон, которого мы не помним, то обращаемся к записной книжке или к телефонному справочнику.
Память человека можно условно назвать оперативной. Здесь слово «оперативный» является синонимом слову «быстрый». Человек быстро воспроизводит сохраненные в памяти знания. Свою память мы еще можем назвать внутренней памятью. Тогда информацию, сохраненную на внешних носителях (в записных книжках, справочниках, энциклопедиях, магнитных записях), можно назвать нашей внешней памятью.
Человек нередко что-то забывает. Информация на внешних носителях хранится дольше, надежнее. Именно с помощью внешних носителей люди передают свои знания из поколения в поколение.
Именно с помощью внешних носителей люди передают свои знания из поколения в поколение.
Передача информации. Распространение информации между людьми происходит в процессе ее передачи. Передача может происходить при непосредственном разговоре между людьми, через переписку, с помощью технических средств связи: телефона, радио, телевидения, компьютерной сети.
В передаче информации всегда участвуют две стороны: есть источник и есть приемник информации. Источник передает (отправляет) информацию, а приемник ее получает (воспринимает). Читая книгу или слушая учителя, вы являетесь приемниками информации, работая над сочинением по литературе или отвечая на уроке, — источником информации. Каждому человеку постоянно приходится переходить от роли источника к роли приемника информации.
Передача информации от источника к приемнику всегда происходит через какой-то канал передачи. При непосредственном разговоре — это звуковые волны; при переписке — это почтовая связь; при телефонном разговоре — это система телефонной связи.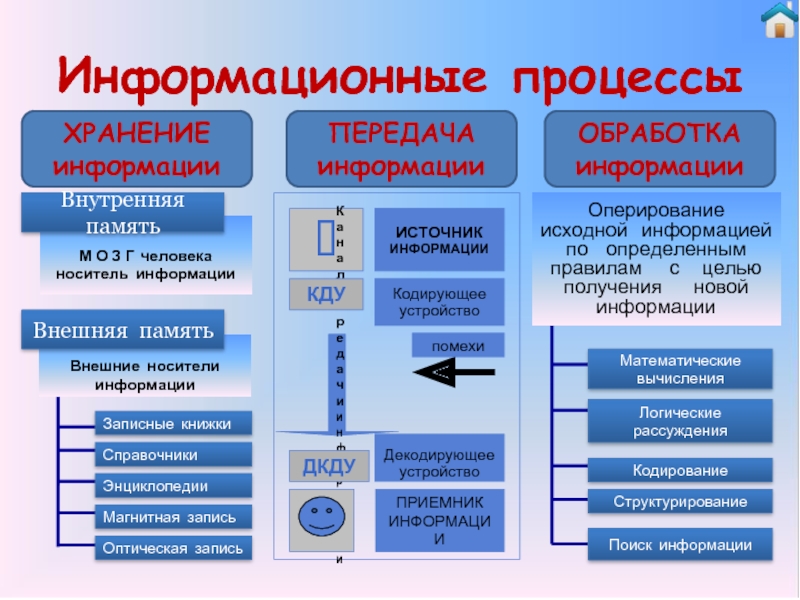 В процессе передачи информация может искажаться или теряться, если информационные каналы имеют плохое качество или на линии связи действуют помехи (шумы). Многие знают, как трудно бывает общаться при плохой телефонной связи.
В процессе передачи информация может искажаться или теряться, если информационные каналы имеют плохое качество или на линии связи действуют помехи (шумы). Многие знают, как трудно бывает общаться при плохой телефонной связи.
Обработка информации. Обработка информации — третий вид информационных процессов. Вот хорошо вам знакомый пример — решение математической задачи: даны значения длин двух катетов прямоугольного треугольника, нужно определить его третью сторону — гипотенузу. Чтобы решить задачу, ученик кроме исходных данных должен знать математическое правило, с помощью которого можно найти решение. В данном случае это теорема Пифагора: «квадрат гипотенузы равен сумме квадратов катетов». Применяя эту теорему, получаем искомую величину. Здесь обработка заключается в том, что новые данные получаются путем вычислений, выполненных над исходными данными.
Вычисление — лишь один из вариантов обработки информации. Новую информацию можно вывести не только путем математических расчетов. Вспомните истории Шерлока Холмса, героя книг Конан Дойля. Имея в качестве исходной информации часто очень запутанные показания свидетелей и косвенные улики, Холмс с помощью логических рассуждений прояснял всю картину событий и разоблачал преступника. Логические рассуждения — это еще один способ обработки информации.
Вспомните истории Шерлока Холмса, героя книг Конан Дойля. Имея в качестве исходной информации часто очень запутанные показания свидетелей и косвенные улики, Холмс с помощью логических рассуждений прояснял всю картину событий и разоблачал преступника. Логические рассуждения — это еще один способ обработки информации.
Процесс обработки информации не всегда связан с получением каких-то новых сведений. Например, при переводе текста с одного языка на другой происходит обработка информации, изменяющая ее форму, но не содержание.
К этому же виду обработки относится кодирование информации. Кодирование — это преобразование представления информации из одной символьной формы в другую, удобную для ее хранения, передачи или обработки.
Особенно широко понятие кодирования стало употребляться с развитием технических средств хранения, передачи и обработки информации (телеграф, радио, компьютеры). Например, в начале XX века телеграфные сообщения кодировались и передавались с помощью азбуки Морзе. Иногда кодирование производится в целях засекречивания содержания текста. В таком случае его называют шифрованием.
Иногда кодирование производится в целях засекречивания содержания текста. В таком случае его называют шифрованием.
Еще одной разновидностью обработки информации является ее сортировка (иногда говорят — упорядочение). Например, вы решили записать адреса и телефоны всех своих одноклассников на отдельные карточки. В каком порядке нужно сложить эти карточки, чтобы затем было удобно искать среди них нужные сведения? Скорее всего, вы сложите их в алфавитном порядке по фамилиям. В информатике организация данных по какому-либо правилу, связывающему ее в единое целое, называется структурированием.
Поиск информации. Нам с вами очень часто приходится заниматься поиском информации: в словаре искать перевод иностранного слова, в телефонном справочнике — номер телефона, в железнодорожном расписании — время отправления поезда, в учебнике математики — нужную формулу, на схеме метро — маршрут движения, в библиотечном каталоге — сведения о нужной книге. Можно привести еще много примеров. Все это — процессы поиска информации на внешних носителях: книгах, схемах, таблицах, картотеках.
Информационные процессы в живой природе. Можно ли утверждать, что с информацией и информационными процессами связана только жизнь человека? Конечно нет! Науке известно множество фактов, подтверждающих протекание информационных процессов в живой природе Животным свойственна память: они помнят дорогу к месту своего обитания, места добывания пищи; домашние животные отличают знакомых людей от незнакомых. Многие животные обладают обостренным обонянием, несущим им ценную информацию. Конечно, способности животных к обработке информации значительно ниже, чем у человека. Однако многие факты разумного поведения свидетельствуют Об их способности к определенным умозаключениям.
Информационные процессы
Существуют три вида информационных процессов: хранение, передача, обработка.
Хранение информации:
Носители информации.
Виды памяти.
Хранилища информации.
Основные свойства хранилищ информации.
С хранением информации связаны следующие понятия: носитель информации (память), внутренняя память, внешняя память, хранилище информации.
Носитель информации – это физическая среда, непосредственно хранящая информацию. Память человека можно назвать оперативной памятью. Заученные знания воспроизводятся человеком мгновенно. Собственную память мы еще можем назвать внутренней памятью, поскольку ее носитель – мозг – находится внутри нас.
Все прочие виды носителей информации можно назвать внешними (по отношению к человеку): дерево, папирус, бумага и т.д. Хранилище информации — это определенным образом организованная информация на внешних носителях, предназначенная для длительного хранения и постоянного использования (например, архивы документов, библиотеки, картотеки). Основной информационной единицей хранилища является определенный физический документ: анкета, книга и др. Под организацией хранилища понимается наличие определенной структуры, т.е. упорядоченность, классификация хранимых документов для удобства работы с ними.
Основные свойства хранилища информации: объем хранимой информации, надежность хранения, время доступа (т. е. время поиска нужных сведений), наличие защиты информации.
е. время поиска нужных сведений), наличие защиты информации.
Информацию, хранимую на устройствах компьютерной памяти, принято называть данными. Организованные хранилища данных на устройствах внешней памяти компьютера принято называть базами и банками данных.
Обработка информации:
Общая схема процесса обработки информации.
Постановка задачи обработки.
Исполнитель обработки.
Алгоритм обработки
Типовые задачи обработки информации.
Схема обработки информации:
Исходная информация – исполнитель обработки – итоговая информация.
В процессе обработки информации решается некоторая информационная задача, которая предварительно может быть поставлена в традиционной форме: дан некоторый набор исходных данных, требуется получить некоторые результаты. Сам процесс перехода от исходных данных к результату и есть процесс обработки. Объект или субъект, осуществляющий обработку, называют исполнителем обработки.
Для успешного выполнения обработки информации исполнителю (человеку или устройству) должен быть известен алгоритм обработки, т. е. последовательность действий, которую нужно выполнить, чтобы достичь нужного результата.
е. последовательность действий, которую нужно выполнить, чтобы достичь нужного результата.
Различают два типа обработки информации. Первый тип обработки: обработка, связанная с получением новой информации, нового содержания знаний (решение математических задач, анализ ситуации и др.). Второй тип обработки: обработка, связанная с изменением формы, но не изменяющая содержания (например, перевод текста с одного языка на другой).
Важным видом обработки информации является кодирование – преобразование информации в символьную форму, удобную для ее хранения, передачи, обработки. Кодирование активно используется в технических средствах работы с информацией (телеграф, радио, компьютеры). Другой вид обработки информации – структурирование данных (внесение определенного порядка в хранилище информации, классификация, каталогизация данных).
Ещё один вид обработки информации – поиск в некотором хранилище информации нужных данных, удовлетворяющих определенным условиям поиска (запросу).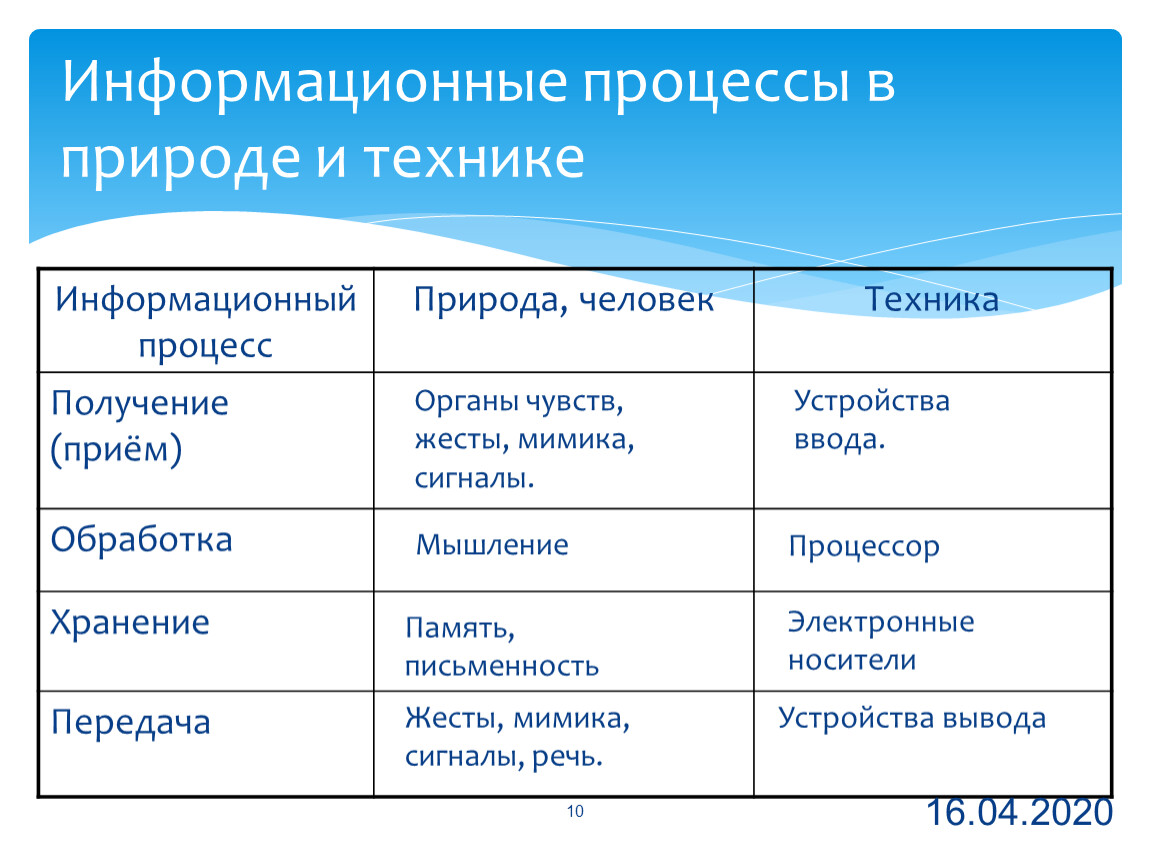 Алгоритм поиска зависит от способа организации информации.
Алгоритм поиска зависит от способа организации информации.
Передача информации:
· Источник и приемник информации.
· Информационные каналы.
· Роль органов чувств в процессе восприятия информации человеком.
· Структура технических систем связи.
· Что такое кодирование и декодирование.
· Понятие шума; приемы защиты от шума.
· Скорость передачи информации и пропускная способность канала.
Схема передачи информации:
Источник информации – информационный канал – приемник информации.
Информация представляется и передается в форме последовательности сигналов, символов. От источника к приёмнику сообщение передается через некоторую материальную среду. Если в процессе передачи используются технические средства связи, то их называют каналами передачи информации (информационными каналами). К ним относятся телефон, радио, ТВ. Органы чувств человека исполняют роль биологических информационных каналов.
Процесс передачи информации по техническим каналам связи проходит по следующей схеме (по Шеннону):
Термином «шум» называют разного рода помехи, искажающие передаваемый сигнал и приводящие к потере информации. Такие помехи, прежде всего, возникают по техническим причинам: плохое качество линий связи, незащищенность друг от друга различных потоков информации, передаваемой по одним и тем же каналам. Для защиты от шума применяются разные способы, например, применение разного рода фильтров, отделяющих полезный сигнал от шума.
Такие помехи, прежде всего, возникают по техническим причинам: плохое качество линий связи, незащищенность друг от друга различных потоков информации, передаваемой по одним и тем же каналам. Для защиты от шума применяются разные способы, например, применение разного рода фильтров, отделяющих полезный сигнал от шума.
Клодом Шенноном была разработана специальная теория кодирования, дающая методы борьбы с шумом. Одна из важных идей этой теории состоит в том, что передаваемый по линии связи код должен быть избыточным. За счет этого потеря какой-то части информации при передаче может быть компенсирована. Однако нельзя делать избыточность слишком большой. Это приведёт к задержкам и подорожанию связи.
При обсуждении темы об измерении скорости передачи информации можно привлечь прием аналогии. Аналог – процесс перекачки воды по водопроводным трубам. Здесь каналом передачи воды являются трубы. Интенсивность (скорость) этого процесса характеризуется расходом воды, т.е. количеством литров, перекачиваемых за единицу времени. В процессе передачи информации каналами являются технические линии связи. По аналогии с водопроводом можно говорить об информационном потоке, передаваемом по каналам. Скорость передачи информации – это информационный объем сообщения, передаваемого в единицу времени. Поэтому единицы измерения скорости информационного потока: бит/с, байт/с и др.
В процессе передачи информации каналами являются технические линии связи. По аналогии с водопроводом можно говорить об информационном потоке, передаваемом по каналам. Скорость передачи информации – это информационный объем сообщения, передаваемого в единицу времени. Поэтому единицы измерения скорости информационного потока: бит/с, байт/с и др.
Еще одно понятие – пропускная способность информационных каналов – тоже может быть объяснено с помощью «водопроводной» аналогии. Увеличить расход воды через трубы можно путем увеличения давления. Но этот путь не бесконечен. При слишком большом давлении трубу может разорвать. Поэтому предельный расход воды, который можно назвать пропускной способностью водопровода. Аналогичный предел скорости передачи данных имеют и технические линии информационной связи. Причины этому также носят физический характер.
Информационные процессы: обработка и передача информации.
- Передача информации.
- Передача информации — физический процесс, посредством которого осуществляется перемещение информации в пространстве.

Распространение информации между людьми происходит в процессе ее передачи. Передача может происходить при непосредственном разговоре между людьми, через переписку, с помощью технических средств связи: телефона, радио, телевидения, компьютерной сети.
В передаче информации всегда участвуют две стороны: есть источник и есть приемник информации. Источник передает (отправляет) информацию, а приемник ее получает (воспринимает). Читая книгу или слушая учителя, вы являетесь приемниками информации, работая над сочинением по литературе или отвечая на уроке, — источником информации. Каждому человеку постоянно приходится переходить от роли источника к роли приемника информации.
Передача информации от источника к приемнику всегда происходит через какой-то канал передачи. При непосредственном разговоре — это звуковые волны; при переписке — это почтовая связь; при телефонном разговоре — это система телефонной связи. В процессе передачи информация может искажаться или теряться, если информационные каналы имеют плохое качество или на линии связи действуют помехи (шумы).
- Обработка информации.
Вот хорошо вам знакомый пример — решение математической задачи: даны значения длин двух катетов прямоугольного треугольника, нужно определить его третью сторону — гипотенузу. Чтобы решить задачу, ученик кроме исходных данных должен знать математическое правило, с помощью которого можно найти решение.
 Здесь обработка заключается в том, что новые данные получаются путем вычислений, выполненных над исходными данными. Вычисление — лишь один из вариантов обработки информации. Новую информацию можно вывести не только путем математических расчетов.
Здесь обработка заключается в том, что новые данные получаются путем вычислений, выполненных над исходными данными. Вычисление — лишь один из вариантов обработки информации. Новую информацию можно вывести не только путем математических расчетов. Процесс обработки информации не всегда связан с получением каких-то новых сведений. Например, при переводе текста с одного языка на другой происходит обработка информации, изменяющая ее форму, но не содержание.
К этому же виду обработки относится кодирование информации. Кодирование — это преобразование представления информации из одной символьной формы в другую, удобную для ее хранения, передачи или обработки.
Особенно широко понятие кодирования стало употребляться с развитием технических средств хранения, передачи и обработки информации (телеграф, радио, компьютеры). Например, в начале XX века телеграфные сообщения кодировались и передавались с помощью азбуки Морзе. Иногда кодирование производится в целях засекречивания содержания текста. В таком случае его называют шифрованием.
В таком случае его называют шифрованием.
Еще одной разновидностью обработки информации является ее сортировка (иногда говорят — упорядочение). Например, вы решили записать адреса и телефоны всех своих одноклассников на отдельные карточки. В каком порядке нужно сложить эти карточки, чтобы затем было удобно искать среди них нужные сведения? Скорее всего, вы сложите их в алфавитном порядке по фамилиям. В информатике организация данных по какому-либо правилу, связывающему ее в единое целое, называется структурированием.
Тест «Информация. Информационная грамотность и информационная культура
Тест «Информация. Информационная грамотность и информационная культура»
Тест к УМК Босовой Л. Л. Информатика. 10 класс (базовый уровень). Бумажный вариант может быть использован для контроля знаний, а онлайн-вариант для самоконтроля
Тест для 10 класса к §1 УМК Босовой Л.Л.
DOCX / 115.11 Кб
1. (1 балл) Одно из фундаментальных понятий современной науки, не объясняемых через другие понятия. _____________________________
_____________________________
2. (2 балла) Принципиальное отличие информации от вещества и энергии
- информация не расходуется при её использовании
- информация расходуется при её использовании
- к информации неприменим закон сохранения
- ценность суммы информации не может превосходить сумму ценностей её частей
- количество информации не уменьшается при передаче её от человека к человеку
3. (3 балла) Различные концепции информации
Установите соответствие между понятием и определением
- функциональная информация
- атрибутивная информация
- антропоцентрическая информация,
A. информация, связанная с функционированием сложных самоорганизующихся систем, к которым относятся живые организмы
B. существует только в человеческом сознании
C. свойство всего сущего, проявляется в изменениях, к которым приводит воздействие одних объектов на другие
4. (1 балл) Укажите источник определения информации
- как «сведений (сообщения, данные) независимо от формы их представления»
- как содержание сигналов (сообщения) расширяющее знания человека об окружающем мире
- как «универсальной субстанции, пронизывающей все сферы человеческой деятельности
- Закон Российской Федерации «Об информации, информационных технологиях и о защите информации»
- в материалах ЮНЕСКО
- курс информатики основной школы
5. (2 балла) Установите соответствие между свойством и его определением
(2 балла) Установите соответствие между свойством и его определением
- релевантность
- актуальность
- достоверность
- понятность
- полнота
- объективность
A. существенна реальному моменту времени
B. выражена на языке, доступном для получателя
C. не зависит от свойств источника информации
D. достаточность для понимания ситуации и принятия решения
E. соответствие запросам потребителя
F. отражение реального положения дел
6. (1 балл) Способность человека идентифицировать потребность в информации, умение её эффективно искать, оценивать и использовать
- Информационная грамотность
- Информационная культура
- Информационное мировоззрение
7. (1 балл) Готовность человека к жизни и деятельности в современном высокотехнологичном информационном обществе, умение эффективно использовать возможности этого общества и защищаться от его негативных воздействий.
- Информационная грамотность
- Информационная культура
- Информационное мировоззрение
8. (1 балл) К какой категории относятся виды информации
(1 балл) К какой категории относятся виды информации
- секретная
- числовая
- звуковая
- графическая
- визуальная
- тактильная
- вкусовая
- специальная
- личная
A. по форме представления
B. по способу восприятия
C. по назначению
Впишите категорию вида информации
9. (2 балла) Под информационной грамотностью, предложенной в 2006 году Международной ассоциацией школьных библиотек, понимается наличие знаний и умений для
- правильной идентификации информации, необходимой для выполнения задания или решения проблемы
- выработка стратегии эффективного поиска информации
- организации и реорганизации информации
- соблюдения этических норм и правил пользования полученной информацией
- оценки объективности, достоверности, полноты, актуальности, полезности полученной информации
- понимания закономерностей протекания информационных процессов
- представления информации в разных формах
10. (1 балл) Установите соответствие. Этапы работы с информацией
(1 балл) Установите соответствие. Этапы работы с информацией
- стартовый этап
- поиск информации
- осмысление полученной информации
- рефлексия
A. Поиск источников информации и их проверка на актуальность, достоверность, полезность и т. д.
B. Постановка цели и осознание информационной потребности
C. Оценка эффективности проделанной работы и осознание влияния этой информации на личные взгляды и поведение
D. Создание собственного смысла: восприятие информации, структурирование информации, формирование гипотезы, обобщение, выводы
11. (3 балла) Свертывание текстовой информации в текст
- резюме
- конспект
- аннотация
- реферат
- тезисы
A. краткий вывод из сказанного, написанного
B. кратко сформулированные основные положения доклада, лекции, сообщения и т.п.
C. краткое точное изложение содержания документа
D. краткая запись содержания услышанного или прочитанного, выраженная своими словами
E. краткая характеристика книги, статьи, их содержания, назначения, ценности и т.д.
краткая характеристика книги, статьи, их содержания, назначения, ценности и т.д.
12. (3 балла) Установите соответствие между типами вопросов и их видами.
- Уточняющие вопросы
- Простые вопросы
- Практические вопросы
- Оценочные вопросы
- Творческие вопросы
- Вопросы-интерпретации
A. Когда произошло…? Кто совершил…?
B. Верно ли я понял, что… ?
C. Почему…?
D. Что будет, если…? Можно ли сделать так, чтобы…?
E. Как использовать…? Где может пригодиться…?
F. Вопросы, помогающие определить значимость информации, дать точную оценку связанным с проблемой предметам, событиям, фактам
13. (1 балл) Укажите графические формы свёртывания информации
- кластер
- интеллект-карта
- плакат
- денотатный граф
- планарный граф
14. (2 балла) Впишите недостающие названия
Графические формы свёртывания текстовой информации | ||
графическая схема, используемая для представления в структурированном виде ключевых слов и словосочетаний, относящихся к рассматриваемому вопросу | графическая форма свёртывания информации, позволяющая вычленить из текста существенные признаки ключевого понятия | особый вид записи, используемый для обобщения и систематизации крупных блоков информации, исходящей от центра к краям, постепенно разветвляющейся на более мелкие части |
15. (1 балл) Подпишите названия графических форм свертывания информации, представленных на рисунке
(1 балл) Подпишите названия графических форм свертывания информации, представленных на рисунке
Ответы
- информация;
- информация не расходуется при её использовании; к информации неприменим закон сохранения; количество информации не уменьшается при передаче её от человека к человеку;
- 1-1; 2-3; 3-2;
- 1-1; 2-3; 3-2:
- 1-5; 2-1; 3-6; 4-2; 5-4; 6-3;
- Информационная грамотность;
- Информационная культура;
- 1, 2, 3, 4, 5;
- 1-2; 2-1; 3-4; 4-3;
- 1-1; 2-4; 3-5; 4-3; 5-2;
- 1, 2, 4;
- Кластер; денотатный граф; интеллект-карта
- Денотатный граф; интеллект-карта; кластер.
Критерии оценивания бумажного варианта
№ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
баллы | 1 | 2 | 3 | 1 | 2 | 1 | 1 | 1 | 2 | 1 | 3 | 3 | 1 | 2 | 1 |
Отметка | Баллы |
«5» | |
«4» | |
«3» | |
«2» |
онлайн-вариант теста
Критерии оценивания онлайн варианта
№ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
баллы | 1 | 2 | 3 | 3 | 6 | 1 | 1 | 3 | 2 | 4 | 9 | 5 | 1 | 3 | 1 |
Отметка | Баллы |
«5» | |
«4» | |
«3» | |
«2» |
Информационная структура — Лингвистика — Оксфордские библиографии
Существует ряд основополагающих работ, которые предоставляют ценную справочную информацию об информационной структуре с различных теоретических точек зрения. Наиболее широко цитируемым источником по информационной структуре и наиболее известным в исследованиях с различных теоретических точек зрения является Lambrecht 1994, который вводит важное различие между ментальными репрезентативными аспектами информационных единиц, с одной стороны, и реляционным характером информационной структуры. категории в передаче информации, с другой.Основополагающие статьи Chafe 1976 и Krifka 2008, а также статьи из руководств Büring 2007 и Gundel and Fretheim 2006 также являются хорошей отправной точкой для начинающих. Все они дают краткие обзоры информационной структуры, когнитивной функции и основных категорий информационной структуры, а также влияния информационной структуры на структуру языковых высказываний. Исторический интерес представляет работа Halliday 1967, которая ввела в лингвистику термин информационная структура . Еще одна важная монография, в которой обсуждается лингвистическая структура предложений в связи с информационной структурой, контекстом и состоянием знания собеседников, — это Erteschik-Shir 2007, тогда как Dik 1997 представляет собой классический обзор с коммуникативно-функционалистской точки зрения.
Наиболее широко цитируемым источником по информационной структуре и наиболее известным в исследованиях с различных теоретических точек зрения является Lambrecht 1994, который вводит важное различие между ментальными репрезентативными аспектами информационных единиц, с одной стороны, и реляционным характером информационной структуры. категории в передаче информации, с другой.Основополагающие статьи Chafe 1976 и Krifka 2008, а также статьи из руководств Büring 2007 и Gundel and Fretheim 2006 также являются хорошей отправной точкой для начинающих. Все они дают краткие обзоры информационной структуры, когнитивной функции и основных категорий информационной структуры, а также влияния информационной структуры на структуру языковых высказываний. Исторический интерес представляет работа Halliday 1967, которая ввела в лингвистику термин информационная структура . Еще одна важная монография, в которой обсуждается лингвистическая структура предложений в связи с информационной структурой, контекстом и состоянием знания собеседников, — это Erteschik-Shir 2007, тогда как Dik 1997 представляет собой классический обзор с коммуникативно-функционалистской точки зрения. Оксфордский онлайн-справочник по информационной структуре (Фери и Исихара, 2014 г.) предоставляет наиболее полный обзор информационной структуры на сегодняшний день.
Оксфордский онлайн-справочник по информационной структуре (Фери и Исихара, 2014 г.) предоставляет наиболее полный обзор информационной структуры на сегодняшний день.
Бюринг, Даниэль. 2007. Интонация, семантика и информационная структура. В Оксфордский справочник лингвистических интерфейсов . Под редакцией Джиллиан Рамчанд и Чарльза Рейсса, 445–474. Оксфорд: Оксфордский ун-т. Нажмите.
Справочная статья. Отличная отправная точка для ученых, заинтересованных в просодии и дискурсивно-семантических эффектах информационной структуры.Обсуждаются две центральные структурные категории информации: фокус-фон и тема-комментарий. Особое внимание уделяется тому, как эти категории интерпретируются соответственно на просодическом и семантическом интерфейсах.
Чейф, Уоллес Л. 1976. Данность, контрастность, определенность, предметы, темы и точка зрения. В теме и теме . Под редакцией Чарльза Н. Ли, 25–55. Нью-Йорк: Академическая пресса.
Основополагающая статья, знакомящая с понятием упаковки информации.Уточняет информационный структурный статус номинальных выражений, рассматривая когнитивную функцию и лингвистическую маркировку.
Дик, Саймон С. 1997. Теория функциональной грамматики . Том. 1, Структура статьи . Под редакцией Киса Хенгевельда. Берлин: Мутон де Грюйтер.
DOI: 10.1515/9783110218374
Глава 13 этого общего введения в функциональную грамматику, впервые опубликованного в 1989 г., дает подробное описание различных прагматических функций темы и фокуса и представляет популярную описательную классификацию прагматических подтипов топика и фокуса.Обновлено в Hengeveld and Mackenzie 2008, цитируется в разделе «Лингвистическая реализация».
Эртещик-Шир, Номи. 2007. Информационная структура . Оксфорд: Оксфордский ун-т. Нажмите.
В монографии представлен анализ темы и направленности как базовых когнитивных категорий, лежащих в основе актуализации информации в картотечной системе. Особый интерес представляет сравнение различных теоретических подходов (§2.4) и обсуждение того, как информационные структурные и грамматические ограничения взаимодействуют при лингвистическом кодировании темы и фокуса.
Особый интерес представляет сравнение различных теоретических подходов (§2.4) и обсуждение того, как информационные структурные и грамматические ограничения взаимодействуют при лингвистическом кодировании темы и фокуса.
Фери, Кэролайн и Шиничиро Исихара, ред. 2014. Оксфордский справочник по информационной структуре . Оксфорд: Оксфордский ун-т. Нажмите.
Всеобъемлющий сборник современных статей ведущих ученых по всем аспектам информационной структуры, включая теоретический анализ, семантику, диахроническое развитие, овладение языком, обработку и компьютерную лингвистику. Содержит подробные описания информационной структуры в основных языковых семьях мира.Отличная отправная точка для начинающих. Доступен онлайн по подписке.
Гундель, Жанетт К. и Торстейн Фретейм. 2006. Информационная структура. В Справочник по прагматике . Под редакцией Яна-Ола Остмана и Джефа Вершерена, 1–17. Амстердам: Джон Бенджаминс.
Краткая справочная статья. Дает краткий обзор феномена информационной структуры, ее структурного кодирования в языковых высказываниях и ее положения на стыке грамматики и обработки информации.Хорошо подходит для студентов и ученых, плохо знакомых с этой темой.
Дает краткий обзор феномена информационной структуры, ее структурного кодирования в языковых высказываниях и ее положения на стыке грамматики и обработки информации.Хорошо подходит для студентов и ученых, плохо знакомых с этой темой.
Холлидей, Майкл А. К. 1967. Заметки о переходности и теме на английском языке: Часть 2. Journal of Linguistics 3.2: 199–244.
DOI: 10.1017/S0022226700016613
Основополагающая статья. Вводит понятие информационной структуры в систематической обработке контекстуальных факторов и просодии. Различные ударные модели английских предложений являются производными от сложного взаимодействия двух информационных структурных уровней: данный-новый (= информационная направленность) и тема-рема.
Крифка, Манфред. 2008. Основные понятия информационной структуры. Acta Linguistica Hungarica 55:243–276.
DOI: 10.1556/ALing.55.2008.3-4.2
Очень влиятельная статья. Дает отличный обзор информационной структуры и соответствующей литературы по теме. Выдвигает убедительную характеристику информационной структуры с точки зрения нескольких независимых измерений, которые взаимодействуют, направляя и облегчая управление контентом участников дискурса.
Выдвигает убедительную характеристику информационной структуры с точки зрения нескольких независимых измерений, которые взаимодействуют, направляя и облегчая управление контентом участников дискурса.
Ламбрехт, Кнуд. 1994. Информационная структура и форма предложения: тема, фокус и мысленные представления референтов дискурса . Кембридж, Великобритания: Кембриджский унив. Нажмите.
DOI: 10.1017/CBO9780511620607
Знающая и очень влиятельная монография. Сочетает формальный и функциональный подходы к грамматическому анализу. Подробное обсуждение темы и фокуса, ментальное представление референтов дискурса и их влияние на структуру языковых высказываний.Различает референциальные и ментальные свойства и присущую реляционную природу темы и фокуса.
Сравнительный подход к изучению обработки биологической информации: изучение структуры и функций жестких дисков компьютера и ДНК | Теоретическая биология и медицинское моделирование
Описав четыре свойства CHD, которые необходимы для ее функции в качестве системы хранения и обработки информации, мы теперь опишем те аспекты DHD, которые также соответствуют этим четырем свойствам. Акцент в этом разделе делается не на попытке провести однозначное сопоставление между каждым компонентом CHD и DHD, а скорее на описании структуры и механизмов, касающихся роли ДНК, с точки зрения четырех функциональных свойств централизованной системы. информационно-обрабатывающего комплекса, отмечая при этом конкретные случаи, когда реализация DHD расходится с CHD.
Акцент в этом разделе делается не на попытке провести однозначное сопоставление между каждым компонентом CHD и DHD, а скорее на описании структуры и механизмов, касающихся роли ДНК, с точки зрения четырех функциональных свойств централизованной системы. информационно-обрабатывающего комплекса, отмечая при этом конкретные случаи, когда реализация DHD расходится с CHD.
Корреляция 1: ортогональность генетической информации ДНК
Биологические системы также полагаются на свойство ортогональности информации, чтобы свести к минимуму вероятность неправильной интерпретации генетического языка.Управляющие области, такие как последовательности промоторов, инсуляторов и энхансеров, а также кодоны, содержащиеся в каждом гене, должны быть представлены нетривиальным и недвусмысленным образом. Нуклеотиды ДНК сами по себе имеют однозначные атрибуты, способствующие целостности языка программирования ДНК. Для генетического материала граничные условия, необходимые для ортогональности информации, возникают из-за избирательного связывания в нуклеиновых кислотах, где аденин (А) соединяется с тимином (Т), а цитозин (С) соединяется с гуанином (G). Замена РНК урацила на тимин участвует в ортогонализации молекулы ДНК [7–9]. Нуклеотиды ДНК A, C, T и G можно рассматривать как единицы биологических данных (кубиты), представляющие систему с основанием 4; в контексте молекулы ДНК эти нуклеотиды взаимодействуют с различными структурными и функциональными молекулами в их роли формирования «языка» генетической информации. Существует функциональная эквивалентность между ортогональностью магнитного представления данных на ВГД и ортогональным представлением информации в виде кубитов на ДГД.
Замена РНК урацила на тимин участвует в ортогонализации молекулы ДНК [7–9]. Нуклеотиды ДНК A, C, T и G можно рассматривать как единицы биологических данных (кубиты), представляющие систему с основанием 4; в контексте молекулы ДНК эти нуклеотиды взаимодействуют с различными структурными и функциональными молекулами в их роли формирования «языка» генетической информации. Существует функциональная эквивалентность между ортогональностью магнитного представления данных на ВГД и ортогональным представлением информации в виде кубитов на ДГД.
Генерация различных типов РНК из кода ДНК преобразует закодированную информацию в полифункциональный формат для использования во всей клетке. Граничные условия кода ДНК и РНК возникают из интегральных биохимических свойств нуклеиновых кислот, ограничивающих их возможные комбинации. Интерпретация мРНК в рибосоме представляет собой «классическую» роль РНК как средства производства белков; однако другие функциональные РНК, такие как микроРНК (miRNA), большие межгенные некодирующие РНК (lincRNAs) и малые интерферирующие РНК (siRNA), служат в качестве критических контрольных элементов при обработке клеточной информации. Многочисленные роли РНК предполагают, что РНК может служить слоем интерпретации информации, который подобен переносу кодирования магнитного потока CHD в логические уровни электрического напряжения, которые затем повсеместно используются в компьютерных логических схемах.
Многочисленные роли РНК предполагают, что РНК может служить слоем интерпретации информации, который подобен переносу кодирования магнитного потока CHD в логические уровни электрического напряжения, которые затем повсеместно используются в компьютерных логических схемах.
Корреляция 2: Низкоуровневое форматирование ДНК в эукариотических клетках
Как обсуждалось выше, форматирование носителя данных представляет собой наложенные на носитель организационные свойства, которые облегчают эффективное использование хранимой информации.Поскольку человеческая ДНК содержит около 3 миллиардов нуклеотидов, составляющих гены, регуляторные последовательности и другие некодирующие области, все они находятся в одномерной последовательности, организованной в трехмерном пространстве, форматирование структуры данных ДНК обязательно является гораздо более сложной задачей, чем что видно на ИБС. Это особенно верно, потому что «список частей», с помощью которых клетка может осуществлять управление своими данными, чрезвычайно ограничен: нуклеиновые кислоты, белки и их модификации. Следовательно, необходимо понимать, что границы между «низкоуровневым» и «высокоуровневым» форматированием и функциями перевода/доступа могут быть размыты, поскольку молекулярные акторы, участвующие в реализации организационных свойств, могут быть одними и теми же.О полифункциональной природе РНК уже упоминалось; точно так же ДНК, в том, что ранее называлось ее «мусорной» формой, признается в качестве важнейшего участника в организации и обработке клеточной информации [10, 11]. Этот тип некодирующей ДНК, составляющий примерно 94-96 процентов эукариотической ДНК, по-видимому, не участвует в «классической» роли ДНК Уотсона и Крика в качестве хранилища информации для синтеза белка; поэтому большая часть человеческой ДНК, по-видимому, работает вне традиционной парадигмы Центральной догмы [12].Однако именно из-за контекстной специфичности ролей этих молекулярных типов мы считаем важным разбить структуру комплекса DHD на группы, которые могут помочь в определении классов контекста и привести к улучшенной категоризации различные функции нуклеиновых кислот.
Следовательно, необходимо понимать, что границы между «низкоуровневым» и «высокоуровневым» форматированием и функциями перевода/доступа могут быть размыты, поскольку молекулярные акторы, участвующие в реализации организационных свойств, могут быть одними и теми же.О полифункциональной природе РНК уже упоминалось; точно так же ДНК, в том, что ранее называлось ее «мусорной» формой, признается в качестве важнейшего участника в организации и обработке клеточной информации [10, 11]. Этот тип некодирующей ДНК, составляющий примерно 94-96 процентов эукариотической ДНК, по-видимому, не участвует в «классической» роли ДНК Уотсона и Крика в качестве хранилища информации для синтеза белка; поэтому большая часть человеческой ДНК, по-видимому, работает вне традиционной парадигмы Центральной догмы [12].Однако именно из-за контекстной специфичности ролей этих молекулярных типов мы считаем важным разбить структуру комплекса DHD на группы, которые могут помочь в определении классов контекста и привести к улучшенной категоризации различные функции нуклеиновых кислот. Поэтому сначала мы обращаем наше внимание на физические структуры, которые соотносятся с тем, что мы считаем низкоуровневым форматированием или физической организацией структур данных DHD.
Поэтому сначала мы обращаем наше внимание на физические структуры, которые соотносятся с тем, что мы считаем низкоуровневым форматированием или физической организацией структур данных DHD.
ДНК пространственно организована внутри ядра [13].Нити ДНК уплотняются в хроматин, а затем организуются в дискретные хроматиновые территории (СТ) (см. рис. 3). Ядерные CT организованы в области доменов эухроматина и гетерохроматина. Изучение субъядерной структуры показало, что гены коллективно организуются внутри обозначенных для них СТ. Эти области прикреплены к субъядерной структуре с помощью последовательности областей прикрепления к матриксу (MAR’s) и областей прикрепления каркаса (SAR’s) [14-16]. Сегменты повторяющейся ДНК были связаны с локализацией этих областей связывания [17].Более тщательное изучение привело к идентификации промежуточных компартментов, распределенных по всему ядру в пространстве между КТ. Эти компартменты были предложены как средство создания межхромосомного домена, содержащего ядерные тельца, необходимые для транскрипционного сплайсинга [18]. Эти пери-ДНК структуры демонстрируют уровень пространственной организации, направленный на выделение транскрибируемых доменов активных и неактивных генов внутри ядра.
Эти пери-ДНК структуры демонстрируют уровень пространственной организации, направленный на выделение транскрибируемых доменов активных и неактивных генов внутри ядра.
Организация ДНК .(перерисовано из Kosak and Groudine, 2004). Архитектура организации ДНК внутри ядра. Текущий взгляд на то, как активные гены расположены в ядре, а молчащие гены разделены.
В интерфазных клетках признаки ядерного матрикса, состоящего из ядерной оболочки и матриксообразного нуклеоскелета, показывают как петли, так и прикрепления MAR/SAR, соединяющие ДНК с ядерной структурой [14, 15]. Ядерный матрикс состоит из рибонуклеопротеинов, таких как ламины, повсеместно встречающиеся в ядре.Ламины присутствуют в ядрах всех эукариотических клеток и образуют ободкообразную структуру на внутреннем слое ядерной мембраны, а также глубокие внутриядерные канальцы, образующие вуалеподобную сеть. Ядерный ламин напрямую взаимодействует с ДНК в хроматине [19]. Эта трехмерная сеть образует субстрат прикрепления ядер (NAS), который представляет собой физическую структуру, аналогичную схеме диска и дорожек CHD. ДНК, организованная внутри CT, структурно закреплена и может быть пространственно организована внутри ядра с точки зрения разделов и объемов (обсуждается в разделе форматирования высокого уровня).Недавние наблюдения показали, что транскрипционно непермиссивные области CT организованы вблизи периферии ядерной мембраны, в то время как транскрипционно пермиссивные гены расположены глубоко в ядре [20]. Инсуляторные тельца могут совместно локализоваться в больших очагах в субъядерной структуре, образуя кластеры генов. Неясно, какой механизм определяет расположение сайтов MARS/SAR/инсуляторов, однако ясно, что функциональная характеристика субстрата прикрепления ядер аналогична пространственному расположению дорожек, прикрепленных к диску CHD.В этом случае молекула полинуклеотида ДНК считается супертреком. «Дорожка» ДНК состоит из чередующихся молекул сахарной рибозы и фосфата, образующих структуру для хранения данных, т.
Эта трехмерная сеть образует субстрат прикрепления ядер (NAS), который представляет собой физическую структуру, аналогичную схеме диска и дорожек CHD. ДНК, организованная внутри CT, структурно закреплена и может быть пространственно организована внутри ядра с точки зрения разделов и объемов (обсуждается в разделе форматирования высокого уровня).Недавние наблюдения показали, что транскрипционно непермиссивные области CT организованы вблизи периферии ядерной мембраны, в то время как транскрипционно пермиссивные гены расположены глубоко в ядре [20]. Инсуляторные тельца могут совместно локализоваться в больших очагах в субъядерной структуре, образуя кластеры генов. Неясно, какой механизм определяет расположение сайтов MARS/SAR/инсуляторов, однако ясно, что функциональная характеристика субстрата прикрепления ядер аналогична пространственному расположению дорожек, прикрепленных к диску CHD.В этом случае молекула полинуклеотида ДНК считается супертреком. «Дорожка» ДНК состоит из чередующихся молекул сахарной рибозы и фосфата, образующих структуру для хранения данных, т. е. оснований кубитов. Это прямо аналогично дорожкам на CHD, которые обеспечивают границу, ограничивающую магнитные биты для непрерывного и линейного выравнивания, поскольку фрагмент сахарного рибозофосфата действует как граница, которая выравнивает кубиты в структуре молекулы, образующей нуклеотиды.Тем не менее, следует отметить, что это не означает, что данные (кубиты) будут использоваться линейно-непрерывным образом, как будет видно из-за фрагментации и альтернативного сплайсинга. Это описание согласуется с нашим определением низкоуровневого форматирования.
е. оснований кубитов. Это прямо аналогично дорожкам на CHD, которые обеспечивают границу, ограничивающую магнитные биты для непрерывного и линейного выравнивания, поскольку фрагмент сахарного рибозофосфата действует как граница, которая выравнивает кубиты в структуре молекулы, образующей нуклеотиды.Тем не менее, следует отметить, что это не означает, что данные (кубиты) будут использоваться линейно-непрерывным образом, как будет видно из-за фрагментации и альтернативного сплайсинга. Это описание согласуется с нашим определением низкоуровневого форматирования.
Основной функцией низкоуровневого форматирования является когерентная организация пространства для хранения на ДНК/субъядерном жестком диске с помощью его субъядерной структуры. Это позволяет ядерному аппарату воздействовать на CT в эухроматине для таких задач, как копирование, сплайсинг и другие регуляторные функции.Однако присутствует структурная организация более высокого уровня, которая облегчает способность клеточного аппарата выполнять эти задачи и проявляется в доменах хроматина более высокого порядка. Парадигму жесткого диска ДНК теперь можно собрать, используя два принципа: физическую структуру (низкоуровневый формат) и программную абстракцию (организационное управление). Второй принцип включает в себя разделение генома на логические части, называемые разделами, и дальнейшую организацию данных в тома и кластеры с использованием процесса, называемого форматированием высокого уровня.Таблица 1 обобщает сравнение между CHD и DHD относительно процесса форматирования низкого уровня
Парадигму жесткого диска ДНК теперь можно собрать, используя два принципа: физическую структуру (низкоуровневый формат) и программную абстракцию (организационное управление). Второй принцип включает в себя разделение генома на логические части, называемые разделами, и дальнейшую организацию данных в тома и кластеры с использованием процесса, называемого форматированием высокого уровня.Таблица 1 обобщает сравнение между CHD и DHD относительно процесса форматирования низкого уровня
Корреляция 3: форматирование высокого уровня ДНК: публикация таблицы размещения биологических файлов
В CHD, высокий Форматирование уровня начинается с разбиения жесткого диска на дискретные изолированные области. Разделение в CHD преследует следующие цели: 1) Это позволяет группировать связанные и похожие данные и операции вместе для повышения эффективности использования.Эта эффективность является как механической, уменьшая расстояние, которое должна пройти считывающая головка CHD для считывания соответствующих данных/инструкций, так и функциональной, поскольку меньшие размеры кластера уменьшают «пробел» (потенциальное неиспользуемое пространство внутри кластера), тем самым повышая производительность и эффективное использование дискового пространства; 2) Изоляция регионов облегчает ограничение и восстановление поврежденных файлов и данных.
 -кодирующая ДНК, которая будет обсуждаться ниже). Однако изоляция областей, возникающая в результате «разделения» ДГД, не является жесткой, как при ВГД. Регуляторным путям и метаболическим модулям может потребоваться информация, которая пересекает хромосомы, поскольку информация для процесса, инициированного на одной хромосоме, может быть доступна и получена с другой.Таким образом, функциональная/логическая организация DHD требует дальнейшего уточнения за пределами организации CHD.
-кодирующая ДНК, которая будет обсуждаться ниже). Однако изоляция областей, возникающая в результате «разделения» ДГД, не является жесткой, как при ВГД. Регуляторным путям и метаболическим модулям может потребоваться информация, которая пересекает хромосомы, поскольку информация для процесса, инициированного на одной хромосоме, может быть доступна и получена с другой.Таким образом, функциональная/логическая организация DHD требует дальнейшего уточнения за пределами организации CHD.
В CHD тома — это логические структуры, представляющие верхний уровень (т. е. наиболее полный) файловой организации. В аналогии с DHD объемы данных могут быть охарактеризованы содержанием гетерохроматиновых и эухроматиновых областей, частично определяемых точками присоединения MAR/SAR и гистоновым кодом. Имеются убедительные доказательства того, что архитектура ядра тесно связана с функцией генома и экспрессией генов [21].Последствия такой пространственной организации очевидны во время клеточной дифференцировки, когда изменение субъядерной структуры делает возможным экспрессию одних генов и подавляет другие. По мере того, как гены молчат, степень конденсации хроматина увеличивается. Недавние исследования предполагают, что молчащий хроматин может влиять на организацию ядра [22, 23]. Также отмечается, что распределение и количество конденсированного хроматина сходны в дифференцированных клетках одной линии, но различаются в ядрах разных клеток [24].Расширенное разделение ЦТ проявляется их компартментализацией внутри ядра. Дополнительная степень функциональности присутствует в расширенных разделах внутри CT, что позволяет транскрипционное состояние активных или неактивных доменов хроматина. В этом смысле домены хроматина представляют собой динамические логические структуры по отношению к экспрессии генов. Действие гистонового кода и схемы клеточного контроля динамически изменяет компартментализацию активных и неактивных доменов вдоль ДНК в зависимости от эпигенетической экспрессии.Структурная организация внутри ядра демонстрирует динамическое квазистационарное состояние (в отличие от чисто стационарной конфигурации).
По мере того, как гены молчат, степень конденсации хроматина увеличивается. Недавние исследования предполагают, что молчащий хроматин может влиять на организацию ядра [22, 23]. Также отмечается, что распределение и количество конденсированного хроматина сходны в дифференцированных клетках одной линии, но различаются в ядрах разных клеток [24].Расширенное разделение ЦТ проявляется их компартментализацией внутри ядра. Дополнительная степень функциональности присутствует в расширенных разделах внутри CT, что позволяет транскрипционное состояние активных или неактивных доменов хроматина. В этом смысле домены хроматина представляют собой динамические логические структуры по отношению к экспрессии генов. Действие гистонового кода и схемы клеточного контроля динамически изменяет компартментализацию активных и неактивных доменов вдоль ДНК в зависимости от эпигенетической экспрессии.Структурная организация внутри ядра демонстрирует динамическое квазистационарное состояние (в отличие от чисто стационарной конфигурации). Эта организация меняется во времени и представляет собой динамическую топологическую организацию генов и их управляющих кодов в рамках организационной структуры ядра. Гистоновый код и его механизмы управления считаются частью процесса форматирования высокого уровня, ответственного за создание как расширенных разделов, так и их логического транскрипционного состояния (включено/выключено).
Эта организация меняется во времени и представляет собой динамическую топологическую организацию генов и их управляющих кодов в рамках организационной структуры ядра. Гистоновый код и его механизмы управления считаются частью процесса форматирования высокого уровня, ответственного за создание как расширенных разделов, так и их логического транскрипционного состояния (включено/выключено).
Дальнейшая организация CHD осуществляется за счет создания единиц организации данных, физически размещенных на одном или нескольких дисках, называемых кластерами. Напомним, что кластеры CHD — это наименьшая организационная единица хранения данных, перенесенная на диск; точно так же кластеры биологических данных являются наименьшими рабочими единицами транскрибируемых генов. Если гены определены как отдельные файлы данных, эти кластеры генов можно рассматривать как кластеры файлов, расположенных в разделе и томах, определяемых CT.Размер кластера определяется размещением консенсусных последовательностей инсулятора в геноме и, следовательно, размещается на DHD путем прикрепления точек прикрепления инсулятора к соответствующим узловым соединениям на ядерной пластинке. Геном в нашей модели можно рассматривать как полифункциональную совокупность нуклеотидов, организованных в слои консенсусных последовательностей инсуляторов, регуляторных областей и кодонов (буква А на рис. 4). Неслучайное линейное расположение кластеров генов [19, 25] и размещение консенсусных последовательностей инсуляторов в ДНК приводят к высокоупорядоченной структуре и расширенному разделению субъядерной пластинки.Это предполагает иерархическую организацию информации, ведущую к транскрипции и клеточной дифференцировке. Один тип кластера может состоять из расположения генов, которые совместно локализуются в общем узле на субнуклеарном субстрате за счет узлового прикрепления участков инсулятора, иногда образуя розетку петель хроматина (буква B на рис. 4). Эталонной системой для идентификации и описания изоляционного эффекта этих доменов хроматина более высокого уровня является геном дрозофилы. Данные по дрозофиле предполагают, что статические домены образуются в результате дополнительной компартментализации хроматина, которые могут функционировать как инсуляторы, что может оказывать дальнейшее влияние на экспрессию генов [25-27].
Геном в нашей модели можно рассматривать как полифункциональную совокупность нуклеотидов, организованных в слои консенсусных последовательностей инсуляторов, регуляторных областей и кодонов (буква А на рис. 4). Неслучайное линейное расположение кластеров генов [19, 25] и размещение консенсусных последовательностей инсуляторов в ДНК приводят к высокоупорядоченной структуре и расширенному разделению субъядерной пластинки.Это предполагает иерархическую организацию информации, ведущую к транскрипции и клеточной дифференцировке. Один тип кластера может состоять из расположения генов, которые совместно локализуются в общем узле на субнуклеарном субстрате за счет узлового прикрепления участков инсулятора, иногда образуя розетку петель хроматина (буква B на рис. 4). Эталонной системой для идентификации и описания изоляционного эффекта этих доменов хроматина более высокого уровня является геном дрозофилы. Данные по дрозофиле предполагают, что статические домены образуются в результате дополнительной компартментализации хроматина, которые могут функционировать как инсуляторы, что может оказывать дальнейшее влияние на экспрессию генов [25-27]. Для образования петель необходим неповрежденный ядерный матрикс [28]. Взаимодействие между множественными сайтами инсуляторов, сближающимися в специфических ядерных местоположениях (буква С на рис. 4), частично связано с распределением консенсусных последовательностей инсуляторов, что приводит к образованию структур хроматиновых розеток [16, 19]. Эти данные подтверждают аргумент о том, что инсуляторные тельца действуют как узлы прикрепления данных (кластеров генов или активных транскрипционных доменов) к определенным местам внутри ядра, что аналогично функции размещения двоичных данных в кластеры на отформатированном жестком диске компьютера.Модель процесса форматирования высокого уровня показана на рисунке 5.
Для образования петель необходим неповрежденный ядерный матрикс [28]. Взаимодействие между множественными сайтами инсуляторов, сближающимися в специфических ядерных местоположениях (буква С на рис. 4), частично связано с распределением консенсусных последовательностей инсуляторов, что приводит к образованию структур хроматиновых розеток [16, 19]. Эти данные подтверждают аргумент о том, что инсуляторные тельца действуют как узлы прикрепления данных (кластеров генов или активных транскрипционных доменов) к определенным местам внутри ядра, что аналогично функции размещения двоичных данных в кластеры на отформатированном жестком диске компьютера.Модель процесса форматирования высокого уровня показана на рисунке 5.
Организованное кластерное картирование ДНК в ядро . Отображение цепи ДНК на жестком диске ДНК: A) показывает цепь ДНК, разложенную на ее информационную структуру. Верхний слой (серый) содержит стратегическое размещение изоляторов, средний слой содержит регионы регуляторного контроля (красный), которые контролируют процесс копирования генов, а нижний слой содержит гены, организованные в форму, обеспечивающую коэкспрессию. B) Показывает сопоставление инсуляторов с субстратом ядерного ламина с образованием кластеров инсуляторов. Эти кластеры расположены таким образом, что они структурно делят гены на организованные кластеры. Области регуляторного контроля (красные) теперь становятся специфическими для рисунка розетки, сформированного из кластеров изоляторов. Это приводит к розетке генов и их контрольных областей. C) Показывает расположение узоров розеток на субстрате ядерного ламина внутри ядра, таким образом создавая жесткий диск ДНК.Красные линии обозначают ламин. Фотографии B и C от Майи, Корсеса, Капельсона и Виктора, «Биология клетки» с разрешения. Доступно в Интернете 9 сентября 2004 г.
B) Показывает сопоставление инсуляторов с субстратом ядерного ламина с образованием кластеров инсуляторов. Эти кластеры расположены таким образом, что они структурно делят гены на организованные кластеры. Области регуляторного контроля (красные) теперь становятся специфическими для рисунка розетки, сформированного из кластеров изоляторов. Это приводит к розетке генов и их контрольных областей. C) Показывает расположение узоров розеток на субстрате ядерного ламина внутри ядра, таким образом создавая жесткий диск ДНК.Красные линии обозначают ламин. Фотографии B и C от Майи, Корсеса, Капельсона и Виктора, «Биология клетки» с разрешения. Доступно в Интернете 9 сентября 2004 г.
Сравнение блок-схем высокоуровневого форматирования ДНК и CHD . Модели форматирования жесткого диска ДНК и жесткого диска компьютера. На рисунке А показан путь высокоуровневого форматирования молекулы ДНК. Начиная с физической организации хромосом на определенные территории, что затем приводит к высокоуровневому форматированию самой молекулы ДНК и, наконец, внедряется в субъядерный ламин в виде розеточных паттернов генных кластеров. Рисунок B состоит из жесткого диска компьютера, иллюстрирующего процессы форматирования высокого уровня. Обратите внимание на сходство между двумя моделями, которые показывают степень функциональной эквивалентности.
Рисунок B состоит из жесткого диска компьютера, иллюстрирующего процессы форматирования высокого уровня. Обратите внимание на сходство между двумя моделями, которые показывают степень функциональной эквивалентности.
В качестве альтернативы, кластеры также могут быть образованы физически разделенными последовательностями, которые совместно экспрессируются и объединяются с помощью механизмов управления более высокого порядка (будет обсуждаться в следующем разделе, посвященном трансляции информации и доступу). Обратите внимание, что этот последний случай подобен тому, что происходит с течением времени на CHD, когда новые данные циклически проходят через систему, поскольку ранее непрерывные кластеры распределяются по CHD в процессе, называемом фрагментацией.Фрагментация ДНК происходит, когда несвязанные экзоны данного гена распределяются по всему геному аналогично кластерам данного файла в CHD, расположенным в несмежных секторах. Для того чтобы система продолжала функционировать с течением времени, должен присутствовать механизм, позволяющий получать и изменять порядок этих распределенных объектов данных. В CHD кластеры для данного файла сопоставляются FAT, который направляет считывающую головку на соответствующую дорожку и сектор, где он считывается, и последовательно помещается в буфер чтения до тех пор, пока все его кластеры не будут в правильном порядке, восстанавливая исходный файл. .Распространение этой аналогии на клетки подразумевало бы биологическую карту, аналогичную FAT, которая определяет, где расположены эти гены, то, что мы называем таблицей размещения биологических файлов (BFAT). Что представляет собой БФАТ? В CHD FAT накладывается при установке операционной системы и сохраняется на диске; в DHD нет внешнего навязывания эквивалентной организационной схемы. Скорее, эта информация частично встроена где-то в генетический код клеток, что приводит к рекурсивным отношениям управления данными.Хотя мы не знаем, существует ли такой эквивалент BFAT, модели, которые мы создаем, убедительно предполагают это. Работа генома, в частности кластеризация узлов-изоляторов, по-видимому, поддерживает реализацию BFAT.
В CHD кластеры для данного файла сопоставляются FAT, который направляет считывающую головку на соответствующую дорожку и сектор, где он считывается, и последовательно помещается в буфер чтения до тех пор, пока все его кластеры не будут в правильном порядке, восстанавливая исходный файл. .Распространение этой аналогии на клетки подразумевало бы биологическую карту, аналогичную FAT, которая определяет, где расположены эти гены, то, что мы называем таблицей размещения биологических файлов (BFAT). Что представляет собой БФАТ? В CHD FAT накладывается при установке операционной системы и сохраняется на диске; в DHD нет внешнего навязывания эквивалентной организационной схемы. Скорее, эта информация частично встроена где-то в генетический код клеток, что приводит к рекурсивным отношениям управления данными.Хотя мы не знаем, существует ли такой эквивалент BFAT, модели, которые мы создаем, убедительно предполагают это. Работа генома, в частности кластеризация узлов-изоляторов, по-видимому, поддерживает реализацию BFAT. Мы предполагаем, что чтение фрагментированных генов в DHD происходит посредством процесса транс-сплайсинга и действия РНК-индуцированного комплекса молчания (RISC). Наша модель предсказывает, что фрагментированные экзоны данного гена должны быть картированы BFAT, на который затем воздействует регуляторная схема клетки для копирования биологических секторов, каждый в свой собственный буфер пре-мРНК.Затем BFAT опосредует сплайсосому для сбора соответствующих экзонов из нескольких пре-мРНК, последовательно мультиплексируя их для реконструкции требуемого транскрипта гена.
Мы предполагаем, что чтение фрагментированных генов в DHD происходит посредством процесса транс-сплайсинга и действия РНК-индуцированного комплекса молчания (RISC). Наша модель предсказывает, что фрагментированные экзоны данного гена должны быть картированы BFAT, на который затем воздействует регуляторная схема клетки для копирования биологических секторов, каждый в свой собственный буфер пре-мРНК.Затем BFAT опосредует сплайсосому для сбора соответствующих экзонов из нескольких пре-мРНК, последовательно мультиплексируя их для реконструкции требуемого транскрипта гена.
Недавно появились свидетельства еще более высокого уровня организации кластеров DHD. Было обнаружено, что в пределах одного гена непрерывные образования экзонов и интронов генерируют более одного белкового продукта посредством экспрессии изоформ альтернативного сплайсинга мРНК [29, 30]. Эти селективные комбинации экзонов предполагают существование множественных временных отображений.Множественные временные сопоставления означают, что для данного гена, состоящего из x интронов и y экзонов, существует множество комбинаций данных экзонов и интронов, которые при объединении в один непрерывный порядок представляют собой альтернативную форму первичного гена (изоформу). Эти сопоставления контролируются путями передачи сигнала и действующими ядерными факторами транскрипции. Поскольку внешние и/или внутренние условия различаются, клетки могут запрашивать одно из этих отображений в разное время своего жизненного цикла, отсюда и термин «временной».Поскольку для этого потребуется несколько сопоставлений, предполагается, что BFAT может хранить эти сопоставления, чтобы спликосома могла соответствующим образом перестроить экзоны. Такие отображения подходят под определение распределенного BFAT. Эти сопоставления потенциально могут быть частью локализованной операционной системы для определенного типа дифференцированных клеток и выполняются аппаратным обеспечением редактирования клетки (то есть сплайсосомным комплексом). Способность сплайсосомы повторно секвенировать экзоны для данной мРНК требует тесной координации Bio-BIOS и контроллера DHD (обсуждается позже) вместе с BFAT для правильной конструкции изоформы.Комбинированная последовательность экзонов в одном секторе гена потенциально содержит большую информационную емкость, чем одна отдельная непрерывная последовательность экзонов, номинально определенная внутри гена.
Эти сопоставления контролируются путями передачи сигнала и действующими ядерными факторами транскрипции. Поскольку внешние и/или внутренние условия различаются, клетки могут запрашивать одно из этих отображений в разное время своего жизненного цикла, отсюда и термин «временной».Поскольку для этого потребуется несколько сопоставлений, предполагается, что BFAT может хранить эти сопоставления, чтобы спликосома могла соответствующим образом перестроить экзоны. Такие отображения подходят под определение распределенного BFAT. Эти сопоставления потенциально могут быть частью локализованной операционной системы для определенного типа дифференцированных клеток и выполняются аппаратным обеспечением редактирования клетки (то есть сплайсосомным комплексом). Способность сплайсосомы повторно секвенировать экзоны для данной мРНК требует тесной координации Bio-BIOS и контроллера DHD (обсуждается позже) вместе с BFAT для правильной конструкции изоформы.Комбинированная последовательность экзонов в одном секторе гена потенциально содержит большую информационную емкость, чем одна отдельная непрерывная последовательность экзонов, номинально определенная внутри гена. Контроллер DHD управляет действиями сплайсосомы посредством координации регуляторных факторов РНК и факторов сплайсинга, эффективно мультиплексируя соответствующие экзоны в зрелую мРНК, где она упаковывается и последовательно отправляется на рибосомы. Это представляет собой более высокий уровень организации, чем обычное удаление интронов из типичной пре-мРНК.Отображения изоформ хорошо вписываются в определение BFAT.
Контроллер DHD управляет действиями сплайсосомы посредством координации регуляторных факторов РНК и факторов сплайсинга, эффективно мультиплексируя соответствующие экзоны в зрелую мРНК, где она упаковывается и последовательно отправляется на рибосомы. Это представляет собой более высокий уровень организации, чем обычное удаление интронов из типичной пре-мРНК.Отображения изоформ хорошо вписываются в определение BFAT.
Стоит отметить, что с точки зрения клеточного поведения определение момента возникновения «точки старта» становится крайне расплывчатым. Однако, проводя аналогию с эквивалентными стадиями управления данными ИБС, разумно сосредоточиться на дифференцировке стволовых клеток, поскольку она аналогична стадии формирования и разделения для ИБС при подготовке к загрузке его операционной системы. В этом случае различие между низкоуровневым и высокоуровневым форматированием стирается.По мере того, как стволовые клетки дифференцируются и созревают, их ДНК может динамически изменять свою организационную конфигурацию в ядре, реструктурируя свои эухроматиновые и гетерохроматиновые компартменты посредством модификаций гистонов и реконфигурации субнуклеарной пластинки. В определенной степени дифференцировку стволовых клеток можно рассматривать как динамическое низкоуровневое форматирование, поскольку в результате этого процесса образуются области, которые могут определять архитектуру активных и неактивных областей генов в зависимости от траектории клеточной дифференцировки.Эта степень контроля и адаптивности намного сложнее, чем технология, используемая в жестких дисках, где сектора вместе с их состоянием активации остаются неизменными после низкоуровневого форматирования. Ключевые процессы, участвующие в регуляции компартментов эухроматина и гетерохроматина, все чаще связаны с некодирующими сегментами РНК. В дополнение к роли РНК-интерференции (РНКи) в подавлении сегментов генетического материала некодирующие РНК вовлечены в формирование гетерохроматина и развитие ген-ориентированных структур более высокого уровня, таких как центромеры и теломеры [31].Кроме того, было показано, что lincRNAs, которые, по-видимому, являются продуктами повторяющейся ДНК, играют роль в управлении хроматин-модифицирующими комплексами [32].
В определенной степени дифференцировку стволовых клеток можно рассматривать как динамическое низкоуровневое форматирование, поскольку в результате этого процесса образуются области, которые могут определять архитектуру активных и неактивных областей генов в зависимости от траектории клеточной дифференцировки.Эта степень контроля и адаптивности намного сложнее, чем технология, используемая в жестких дисках, где сектора вместе с их состоянием активации остаются неизменными после низкоуровневого форматирования. Ключевые процессы, участвующие в регуляции компартментов эухроматина и гетерохроматина, все чаще связаны с некодирующими сегментами РНК. В дополнение к роли РНК-интерференции (РНКи) в подавлении сегментов генетического материала некодирующие РНК вовлечены в формирование гетерохроматина и развитие ген-ориентированных структур более высокого уровня, таких как центромеры и теломеры [31].Кроме того, было показано, что lincRNAs, которые, по-видимому, являются продуктами повторяющейся ДНК, играют роль в управлении хроматин-модифицирующими комплексами [32]. Становится все более очевидным, что некодирующие РНК играют жизненно важную роль в эпигенетической регуляции обработки клеточной информации, особенно в построении и конфигурации структур генетических данных на надтранскриптовом уровне. Когда клетки начинают дифференцироваться, логично предположить, что множественные гены, выполняющие функции, относящиеся к типу клеток, должны быть секвестрированы в области ядерной пластинки, что будет способствовать их транскрипции.Это может быть достигнуто путем перегруппировки инсуляторных узлов в субъядерную структуру вместе с MAR и SAR и реализации уникальных программ гистоновой логики. Это представляет собой отправную точку от аналогии с CHD и будет эквивалентно перенастройке дорожек и секторов его подключения к диску. Сходным образом, мультигенная компартментализация в гетерохроматине может нуждаться в организации так, чтобы их можно было заглушить. Лежащий в основе линейный порядок генов, расположенных вдоль хромосомы, обеспечивает скоординированную регуляцию транскриптомов.
Становится все более очевидным, что некодирующие РНК играют жизненно важную роль в эпигенетической регуляции обработки клеточной информации, особенно в построении и конфигурации структур генетических данных на надтранскриптовом уровне. Когда клетки начинают дифференцироваться, логично предположить, что множественные гены, выполняющие функции, относящиеся к типу клеток, должны быть секвестрированы в области ядерной пластинки, что будет способствовать их транскрипции.Это может быть достигнуто путем перегруппировки инсуляторных узлов в субъядерную структуру вместе с MAR и SAR и реализации уникальных программ гистоновой логики. Это представляет собой отправную точку от аналогии с CHD и будет эквивалентно перенастройке дорожек и секторов его подключения к диску. Сходным образом, мультигенная компартментализация в гетерохроматине может нуждаться в организации так, чтобы их можно было заглушить. Лежащий в основе линейный порядок генов, расположенных вдоль хромосомы, обеспечивает скоординированную регуляцию транскриптомов. Например, локусы IgH и B-globin имеют общие геномные позиции, которые регулируются в конкретных типах клеток [25]. Эти линейные расположения генов совпадают с паттернами ядерной локализации, которые способствуют их состоянию активности. Несмотря на то, что эти два массива генов являются результатом событий дупликации, совместно регулируемая гомология все же может быть организована в виде линейных кластеров по всему геному [25]. Это может отражать согласованность между совместно регулируемым линейным расположением генов в ДНК и их физическим расположением в ядре.Предполагается, что линейное расположение кластеров генов в трансгеномы соответствует определенным критериям высокоуровневого форматирования, требуемого для централизованных систем обработки информации. Таблица 2 суммирует сравнение высокоуровневого форматирования CHD и DHD.
Например, локусы IgH и B-globin имеют общие геномные позиции, которые регулируются в конкретных типах клеток [25]. Эти линейные расположения генов совпадают с паттернами ядерной локализации, которые способствуют их состоянию активности. Несмотря на то, что эти два массива генов являются результатом событий дупликации, совместно регулируемая гомология все же может быть организована в виде линейных кластеров по всему геному [25]. Это может отражать согласованность между совместно регулируемым линейным расположением генов в ДНК и их физическим расположением в ядре.Предполагается, что линейное расположение кластеров генов в трансгеномы соответствует определенным критериям высокоуровневого форматирования, требуемого для централизованных систем обработки информации. Таблица 2 суммирует сравнение высокоуровневого форматирования CHD и DHD.
Корреляция 4: трансляция и доступ к биологической информации с помощью механизма транскрипции ДНК фон Неймана), состоит в том, что абстрактное представление предполагает линейный процесс: одна последовательность ДНК ведет к одной мРНК, ведет к одному белку.
 Ясно, что с точки зрения клетки это не так. Ячейка управляет несколькими процессами одновременно, а не в виде одной поточной последовательности. Однако, несмотря на свою многопоточную вычислительную мощность, клетка сохраняет единый набор хромосом, находящихся в централизованном положении как в пространственном, так и в организационном плане. Таким образом, чтобы провести нашу аналогию более полно, ячейка рассматривается как полноценная вычислительная машина с точки зрения, похожей на многоядерный компьютерный кластер, где есть централизованная память и набор команд, но вычислительные задачи распределены между отдельными процессорными элементами. .Мы вернемся к концепции клетки как многоядерного вычислительного устройства в следующем разделе, но для того, чтобы завершить определение эквивалентности между CHD и DHD, мы попытаемся описать биологический аналог одного потока информации. обработка.
Ясно, что с точки зрения клетки это не так. Ячейка управляет несколькими процессами одновременно, а не в виде одной поточной последовательности. Однако, несмотря на свою многопоточную вычислительную мощность, клетка сохраняет единый набор хромосом, находящихся в централизованном положении как в пространственном, так и в организационном плане. Таким образом, чтобы провести нашу аналогию более полно, ячейка рассматривается как полноценная вычислительная машина с точки зрения, похожей на многоядерный компьютерный кластер, где есть централизованная память и набор команд, но вычислительные задачи распределены между отдельными процессорными элементами. .Мы вернемся к концепции клетки как многоядерного вычислительного устройства в следующем разделе, но для того, чтобы завершить определение эквивалентности между CHD и DHD, мы попытаемся описать биологический аналог одного потока информации. обработка. Чтобы клетка могла использовать информацию, содержащуюся в ее хромосоме, необходимо, чтобы внутриядерная информация, закодированная в ДНК, была преобразована в форму для использования во всей клетке.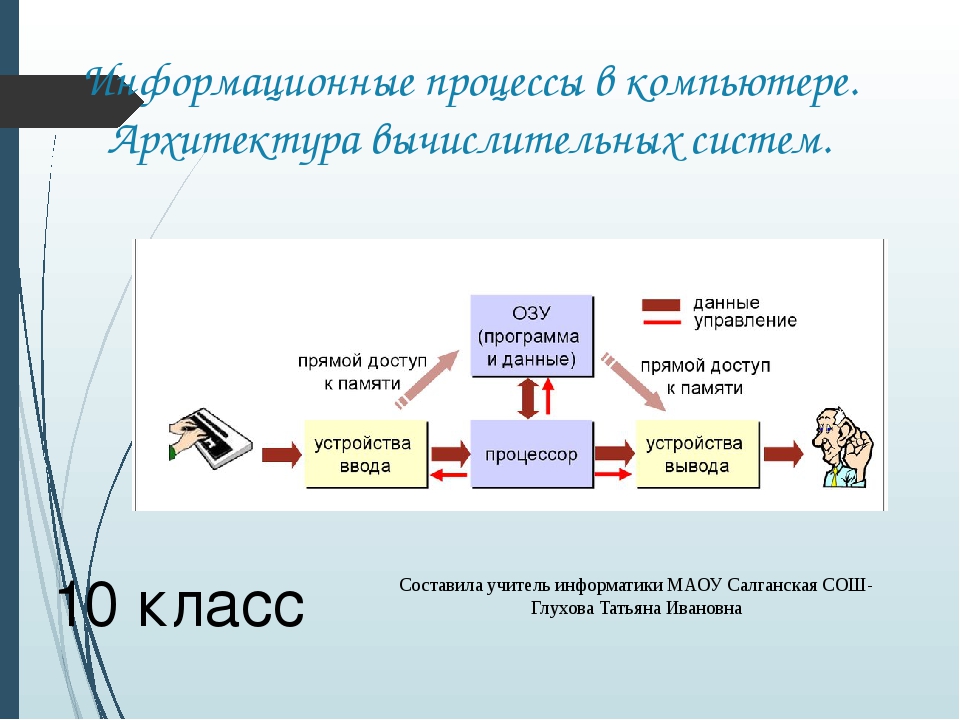 Как упоминалось выше, различные типы РНК служат посредниками в трансляции, доступе и контроле информации, закодированной в ДНК.мРНК является промежуточным форматом данных для синтеза белка, и в целях сравнения с головкой чтения CHD будет в центре внимания обсуждения в этом разделе. В то время как некодирующие РНК играют критическую роль в обработке генетической информации, их посттранскрипционная роль в модуляции того, как реализуется набор генетических инструкций, более точно соответствует функциям набора инструкций и операционной системы CHD; предполагаемая роль и аналогия в этом контексте будут представлены в следующем разделе.Это еще один пример сложной задачи характеристики клеточной обработки информации, возникающей из-за того, что биология использует полифункциональные компоненты во имя «экономики».
Как упоминалось выше, различные типы РНК служат посредниками в трансляции, доступе и контроле информации, закодированной в ДНК.мРНК является промежуточным форматом данных для синтеза белка, и в целях сравнения с головкой чтения CHD будет в центре внимания обсуждения в этом разделе. В то время как некодирующие РНК играют критическую роль в обработке генетической информации, их посттранскрипционная роль в модуляции того, как реализуется набор генетических инструкций, более точно соответствует функциям набора инструкций и операционной системы CHD; предполагаемая роль и аналогия в этом контексте будут представлены в следующем разделе.Это еще один пример сложной задачи характеристики клеточной обработки информации, возникающей из-за того, что биология использует полифункциональные компоненты во имя «экономики».
Для преобразования информации о ДНК в информацию о мРНК необходимо найти соответствующую рамку считывания, определить место начала инициации и надежное копирование файла данных. Каждый ген связан с кодовой последовательностью, называемой промоторной областью, которая содержит информацию, которая инициализирует биологический эквивалент «считывающей головки» в соответствующем сайте инициации транскрипции каждого гена.В эукариотической парадигме DHD мы рассматриваем комплекс РНК-полимеразы II (RNA Pol II) как выполняющий функции, аналогичные головке чтения CHD. Промоторная область выступает в качестве фундамента для сборки необходимых молекулярных компонентов (факторов транскрипции и цис-регуляторных элементов) в базальный комплекс транскрипции (BTC), который в конечном итоге выравнивает РНК Pol II с сайтом инициации транскрипции. BTC выравнивается и присоединяется к правильной последовательности ТАТА, образуя эталонную базу, которая будет участвовать в правильном выравнивании биологической считывающей головки.Расстояние между нуклеотидами между ТАТА-боксом и сайтом начала транскрипции имеет решающее значение для определения надлежащей открытой рамки считывания для начала транскрипции [33].
Каждый ген связан с кодовой последовательностью, называемой промоторной областью, которая содержит информацию, которая инициализирует биологический эквивалент «считывающей головки» в соответствующем сайте инициации транскрипции каждого гена.В эукариотической парадигме DHD мы рассматриваем комплекс РНК-полимеразы II (RNA Pol II) как выполняющий функции, аналогичные головке чтения CHD. Промоторная область выступает в качестве фундамента для сборки необходимых молекулярных компонентов (факторов транскрипции и цис-регуляторных элементов) в базальный комплекс транскрипции (BTC), который в конечном итоге выравнивает РНК Pol II с сайтом инициации транскрипции. BTC выравнивается и присоединяется к правильной последовательности ТАТА, образуя эталонную базу, которая будет участвовать в правильном выравнивании биологической считывающей головки.Расстояние между нуклеотидами между ТАТА-боксом и сайтом начала транскрипции имеет решающее значение для определения надлежащей открытой рамки считывания для начала транскрипции [33]. Смещение РНК Pol II может вызвать ошибку рамки считывания. Присоединение РНК Pol II к соответствующему сайту инициации транскрипции облегчается за счет правильного выравнивания фактора транскрипции II B (TFIIB). TFIIB представляет собой многофункциональный молекулярный комплекс, сигнальный рецептор, реагирующий на молекулы активации генов.RNA Pol II присоединяется к комплексу TFIIB, что приводит к конформационным изменениям, которые позволяют RNA Pol II точно нацеливаться на стартовый сайт инициации [33]. В этом смысле комплекс базальной транскрипции функционально эквивалентен сервоголовке, клиновидному коду Грея и части синхронизации разделов управления заголовком CHD.
Смещение РНК Pol II может вызвать ошибку рамки считывания. Присоединение РНК Pol II к соответствующему сайту инициации транскрипции облегчается за счет правильного выравнивания фактора транскрипции II B (TFIIB). TFIIB представляет собой многофункциональный молекулярный комплекс, сигнальный рецептор, реагирующий на молекулы активации генов.RNA Pol II присоединяется к комплексу TFIIB, что приводит к конформационным изменениям, которые позволяют RNA Pol II точно нацеливаться на стартовый сайт инициации [33]. В этом смысле комплекс базальной транскрипции функционально эквивалентен сервоголовке, клиновидному коду Грея и части синхронизации разделов управления заголовком CHD.
Взаимодействия активаторов с соответствующими кор-промоторами принимают форму динамических изменений как в хроматине, так и в сборке общих факторов транскрипции, таких как конформационные изменения комплекса РНК Pol II [33].Это сильно отличается от схемы управления CHD. В CHD подпрограммы поиска и извлечения данных с использованием процесса чтения механически определяются и контролируются предопределенной логикой. Комбинация основных промоторов и активаторов обеспечивает регуляторную активность генов, которая намного превышает уровень контроля в схеме контроллера CHD. В то время как DHD может адаптироваться к изменениям в окружающей среде клетки, CHD гораздо более ограничен. Части заголовков генетических файлов предлагают более высокую степень свободы с точки зрения активного управления, чем предустановленные заголовки CHD.Способ, которым РНК Pol II перемещается по мере считывания транскрибируемого гена, также совершенно другой. В CHD диск, содержащий намагниченные биты данных, вращается с высокой скоростью под сервоголовкой. Когда диск вращается, новый бит (граница потока) проходит через принимающую граничную область сервоголовки, и данные считываются. В DHD можно считать, что ДНК остается относительно неподвижной, в то время как РНК Pol II находится в движении. Кроме того, происходит ведущее раскручивание нуклеосом, что позволяет РНК Pol II эффективно считывать каждый нуклеотид.Механизм, называемый комплексом ремоделирования хроматина RSC, белковой машиной, раскручивает намотанные нити ДНК.
Комбинация основных промоторов и активаторов обеспечивает регуляторную активность генов, которая намного превышает уровень контроля в схеме контроллера CHD. В то время как DHD может адаптироваться к изменениям в окружающей среде клетки, CHD гораздо более ограничен. Части заголовков генетических файлов предлагают более высокую степень свободы с точки зрения активного управления, чем предустановленные заголовки CHD.Способ, которым РНК Pol II перемещается по мере считывания транскрибируемого гена, также совершенно другой. В CHD диск, содержащий намагниченные биты данных, вращается с высокой скоростью под сервоголовкой. Когда диск вращается, новый бит (граница потока) проходит через принимающую граничную область сервоголовки, и данные считываются. В DHD можно считать, что ДНК остается относительно неподвижной, в то время как РНК Pol II находится в движении. Кроме того, происходит ведущее раскручивание нуклеосом, что позволяет РНК Pol II эффективно считывать каждый нуклеотид.Механизм, называемый комплексом ремоделирования хроматина RSC, белковой машиной, раскручивает намотанные нити ДНК. RSC эффективно удерживает индивидуальную нуклеосому и создает распространяющуюся выпуклость в гистонах, которая обнажает цепь ДНК для транскрипции [34]. Все это делается по отношению к секторам и кластерам, воплощенным внутри субъядерной структуры. После того, как РНК Pol II копирует нуклеотид, комплекс продвигается вперед, а другой механизм собирает гистоны и переупаковывает ДНК. Этот процесс намного сложнее, чем CHD, но согласуется с CHD в том, что должно быть относительное движение между носителем данных и механизмом, который его считывает.В таблице 3 показано соответствие между соответствующими функциями считывающей головки функций контроллера CHD и DHD. Интересно отметить, что контрольный сигнал для выполнения действия транскрипции обычно основан на взаимодействии с дистальными промоторами и энхансерами. Энхансеры могут находиться на расстоянии тысяч пар оснований от связанных с ними основных промоторов. Связанные с энхансером факторы могут буквально принимать участие в искривлении трека ДНК таким образом, что они физически взаимодействуют со своими основными промоторами.
RSC эффективно удерживает индивидуальную нуклеосому и создает распространяющуюся выпуклость в гистонах, которая обнажает цепь ДНК для транскрипции [34]. Все это делается по отношению к секторам и кластерам, воплощенным внутри субъядерной структуры. После того, как РНК Pol II копирует нуклеотид, комплекс продвигается вперед, а другой механизм собирает гистоны и переупаковывает ДНК. Этот процесс намного сложнее, чем CHD, но согласуется с CHD в том, что должно быть относительное движение между носителем данных и механизмом, который его считывает.В таблице 3 показано соответствие между соответствующими функциями считывающей головки функций контроллера CHD и DHD. Интересно отметить, что контрольный сигнал для выполнения действия транскрипции обычно основан на взаимодействии с дистальными промоторами и энхансерами. Энхансеры могут находиться на расстоянии тысяч пар оснований от связанных с ними основных промоторов. Связанные с энхансером факторы могут буквально принимать участие в искривлении трека ДНК таким образом, что они физически взаимодействуют со своими основными промоторами. Это может вызвать транскрипцию активного гена.Этот изгиб ДНК представляет собой трехмерное структурное изменение, не имеющее аналога при ИБС. Поскольку промоторные области связаны с соответствующим им геном и/или генным кластером, белок-центрический взгляд на ген пересматривается, чтобы включить в его определение регуляторные и транскрипционные области и другие области нетранскрипционной последовательности [35]. Используя это определение, предполагается, что ген вместе с его комплексом промотор/базальная транскрипция согласуется с физическим расположением секторов с заголовками в CHD и функционально эквивалентен секторам в DHD.В обоих случаях контроллер должен идентифицировать запрошенные регионы, проверить и подтвердить, что они разрешены для копирования.
Это может вызвать транскрипцию активного гена.Этот изгиб ДНК представляет собой трехмерное структурное изменение, не имеющее аналога при ИБС. Поскольку промоторные области связаны с соответствующим им геном и/или генным кластером, белок-центрический взгляд на ген пересматривается, чтобы включить в его определение регуляторные и транскрипционные области и другие области нетранскрипционной последовательности [35]. Используя это определение, предполагается, что ген вместе с его комплексом промотор/базальная транскрипция согласуется с физическим расположением секторов с заголовками в CHD и функционально эквивалентен секторам в DHD.В обоих случаях контроллер должен идентифицировать запрошенные регионы, проверить и подтвердить, что они разрешены для копирования.
Совместное использование информации и производительность команды: метаанализ
%PDF-1.5 % 1 0 объект >поток 2009-09-28T19:08:40-04:002009-03-18T14:42:09-04:002009-09-28T19:08:40-04:00HELIOS pdfcatapplication/pdf
 ,;7Kŧ(hevn;&_t|n?FB&mlw6MMn?6nAw$Քl;ی_J}4Am{-Mcۙ.L~(vw|ȸ6#H`h h
78t d:O9,h5F~pn4Xt80v}1wQ͋ y౷2juf=iT>UyGνTsWw4 (>{9xj|1m6LOƮ/$# kR i.W#e3Uj=9
,;7Kŧ(hevn;&_t|n?FB&mlw6MMn?6nAw$Քl;ی_J}4Am{-Mcۙ.L~(vw|ȸ6#H`h h
78t d:O9,h5F~pn4Xt80v}1wQ͋ y౷2juf=iT>UyGνTsWw4 (>{9xj|1m6LOƮ/$# kR i.W#e3Uj=9Рекомендации по управлению информацией | Smartsheet
В 1970-х годах управление информацией начало выходить из управления данными, поскольку виртуальные носители стали вытеснять физические (перфокарты, магнитные ленты, бумага и т. д.). Когда в 80-х годах ПК стали заменять мейнфреймы в качестве основной вычислительной платформы, а в 90-х стали популярны сетевые системы, управление информацией стало самостоятельным.
Определение управления информацией постоянно развивается по мере изменения технологий, идей и потребностей бизнеса. IM может включать в себя цикл организационных действий: сбор данных, анализ, категоризацию, контекстуализацию и архивирование (а в некоторых случаях и их удаление) для поддержки потребностей бизнеса. Это означает, что у данных и информации есть жизненный цикл: они полезны в течение определенного периода времени, но в какой-то момент они перестают быть ценными.
Как и любая другая бизнес-практика, IM включает в себя общие концепции управления, такие как планирование, контроль и исполнение.Управление информацией также включает управление данными и связанные с ним действия. Управление данными — это разработка и внедрение инструментов и политик, которые позволяют данным переходить от этапа к этапу в течение их жизненного цикла.
Управление информацией состоит из четырех основных компонентов.
- Люди: Не только те, кто занимается обменом мгновенными сообщениями, но также создатели и пользователи данных и информации.
- Политики и процессы: Правила, определяющие, кто и к чему имеет доступ, шаги по хранению и защите информации, которые должны храниться и защищаться, а также временные рамки для архивирования или удаления.
- Технология: Физические предметы (компьютеры, картотечные шкафы и т. д.), в которых хранятся данные и информация, а также любое используемое программное обеспечение.

- Данные и информация: Что используют остальные компоненты.
Чем не является управление информацией
IM часто путают с управлением контентом или управлением знаниями. Хотя все три процесса взаимосвязаны и частично совпадают, у них есть некоторые различия.Управление контентом имеет дело с данными (блоками текста, изображениями, видео и т. д.), которые использует веб-сайт, и обложками для организации и отображения данных (например, теги XML или кодирование HTML). Управление знаниями похоже на библиотечное дело и имеет дело с информацией для обучения и образования, а также с передачей знаний и опыта и передачей извлеченных уроков.
Изучение структуры базы данных Access
Знакомство с таблицами, формами, запросами и другими объектами в базе данных Access может упростить выполнение самых разнообразных задач, таких как ввод данных в форму, добавление или удаление таблицы, поиск и замена данных и выполнение запросов.
В этой статье представлен общий обзор структуры базы данных Access. Access предоставляет несколько инструментов, которые можно использовать для ознакомления со структурой конкретной базы данных. В этой статье также объясняется, как, когда и почему вы используете каждый инструмент.
Примечание. В этой статье рассказывается о традиционных базах данных Access, состоящих из файла или набора файлов, содержащих все данные и функции приложения, например формы ввода данных.Некоторые из них не относятся к веб-базам данных Access и веб-приложениям Access.
Обзор
База данных — это набор информации, относящейся к определенному предмету или цели, такой как отслеживание заказов клиентов или поддержание музыкальной коллекции. Если ваша база данных не хранится на компьютере или хранится только ее часть, возможно, вы отслеживаете информацию из различных источников, которые необходимо координировать и систематизировать.
Например, предположим, что номера телефонов ваших поставщиков хранятся в разных местах: в картотеке, содержащей номера телефонов поставщиков, в файлах с информацией о продуктах в картотеке и в электронной таблице, содержащей информацию о заказах.Если номер телефона поставщика изменится, вам, возможно, придется обновить эту информацию во всех трех местах. В хорошо продуманной базе данных Access номер телефона сохраняется только один раз, поэтому вам нужно обновить эту информацию только в одном месте. В результате, когда вы обновляете номер телефона поставщика, он автоматически обновляется везде, где вы его используете в базе данных.
Доступ к файлам базы данных
Вы можете использовать Access для управления всей своей информацией в одном файле.В файле базы данных Access вы можете использовать:
Таблицы для хранения ваших данных.
Запросы для поиска и получения только нужных данных.

Формы для просмотра, добавления и обновления данных в таблицах.
Отчеты для анализа или печати данных в определенном макете.
1. Сохраняйте данные один раз в одной таблице, но просматривайте их из нескольких мест. Когда вы обновляете данные, они автоматически обновляются везде, где появляются.
2. Получить данные с помощью запроса.
3. Просмотрите или введите данные с помощью формы.
4. Отображение или печать данных с помощью отчета.
Все эти элементы — таблицы, запросы, формы и отчеты — являются объектами базы данных.
Примечание. Некоторые базы данных Access содержат ссылки на таблицы, хранящиеся в других базах данных. Например, у вас может быть одна база данных Access, не содержащая ничего, кроме таблиц, и другая база данных Access, содержащая ссылки на эти таблицы, а также запросы, формы и отчеты, основанные на связанных таблицах. В большинстве случаев не имеет значения, является ли таблица связанной таблицей или фактически хранится в базе данных.
В большинстве случаев не имеет значения, является ли таблица связанной таблицей или фактически хранится в базе данных.
Таблицы и связи
Для хранения данных вы создаете по одной таблице для каждого типа отслеживаемой информации.Типы информации могут включать информацию о клиентах, продуктах и деталях заказа. Чтобы объединить данные из нескольких таблиц в запрос, форму или отчет, вы определяете отношения между таблицами.
Примечание. В веб-базе данных или веб-приложении нельзя использовать вкладку объекта «Отношения» для создания отношений. Вы можете использовать поля поиска для создания отношений в веб-базе данных или веб-приложении.
1.Информация о клиентах, которая когда-то существовала в списке рассылки, теперь находится в таблице «Клиенты».
2. Информация о заказе, которая когда-то существовала в электронной таблице, теперь находится в таблице «Заказы».
3. Уникальный идентификатор, например идентификатор клиента, отличает одну запись от другой в таблице. Добавляя поле уникального идентификатора одной таблицы в другую таблицу и определяя связь между двумя полями, Access может сопоставлять связанные записи из обеих таблиц, чтобы вы могли объединить их в форме, отчете или запросе.
Запросы
Запрос может помочь вам найти и получить данные, соответствующие заданным вами условиям, включая данные из нескольких таблиц. Вы также можете использовать запрос для обновления или удаления нескольких записей одновременно, а также для выполнения предопределенных или пользовательских вычислений с вашими данными.
Примечание. Вы не можете использовать запрос для обновления или удаления записей в веб-базе данных или веб-приложении.
1. В таблице Customers есть информация о клиентах.
В таблице Customers есть информация о клиентах.
2. В таблице Orders содержится информация о заказах клиентов.
3. Этот запрос извлекает данные об идентификаторе заказа и требуемой дате из таблицы «Заказы», а также данные о названии компании и городе из таблицы «Клиенты». Запрос возвращает только заказы, которые были необходимы в апреле, и только для клиентов, находящихся в Лондоне.
Формы
Вы можете использовать форму для простого просмотра, ввода и изменения данных по одной строке за раз. Вы также можете использовать форму для выполнения других действий, таких как отправка данных в другое приложение. Формы обычно содержат элементы управления, связанные с базовыми полями в таблицах. Когда вы открываете форму, Access извлекает данные из одной или нескольких из этих таблиц, а затем отображает данные в том макете, который вы выбрали при создании формы.Вы можете создать форму с помощью одной из команд Form на ленте, в мастере форм или создать форму самостоятельно в представлении «Дизайн».
Примечание. Вы используете представление «Макет», а не представление «Дизайн», для создания форм и отчетов в веб-базах данных и веб-приложениях.
1. В таблице одновременно отображается множество записей, но может потребоваться горизонтальная прокрутка, чтобы увидеть все данные в одной записи.Кроме того, когда вы просматриваете таблицу, вы не можете одновременно обновлять данные из более чем одной таблицы.
2. Форма фокусируется на одной записи за раз и может отображать поля из более чем одной таблицы. Он также может отображать изображения и другие объекты.
3. Форма может содержать кнопку, по нажатию которой можно напечатать отчет, открыть другие объекты или иным образом автоматизировать задачи.
Отчеты
Вы можете использовать отчет, чтобы быстро проанализировать данные или представить их определенным образом в печати или в других форматах. Например, вы можете отправить коллеге отчет, в котором данные группируются и подсчитываются итоги. Или вы можете создать отчет с адресными данными, отформатированными для печати почтовых этикеток.
Например, вы можете отправить коллеге отчет, в котором данные группируются и подсчитываются итоги. Или вы можете создать отчет с адресными данными, отформатированными для печати почтовых этикеток.
1. Используйте отчет для создания почтовых ярлыков.
2. Используйте отчет для отображения итогов на диаграмме.
3. Используйте отчет для отображения рассчитанных итогов.
Теперь, когда вы знакомы с базовой структурой баз данных Access, читайте дальше, чтобы узнать, как использовать встроенные инструменты для изучения конкретной базы данных Access.
См. сведения об объектах в базе данных
Один из лучших способов узнать о конкретной базе данных — использовать Database Documenter. Вы используете Database Documenter для создания отчета, содержащего подробную информацию об объектах в базе данных.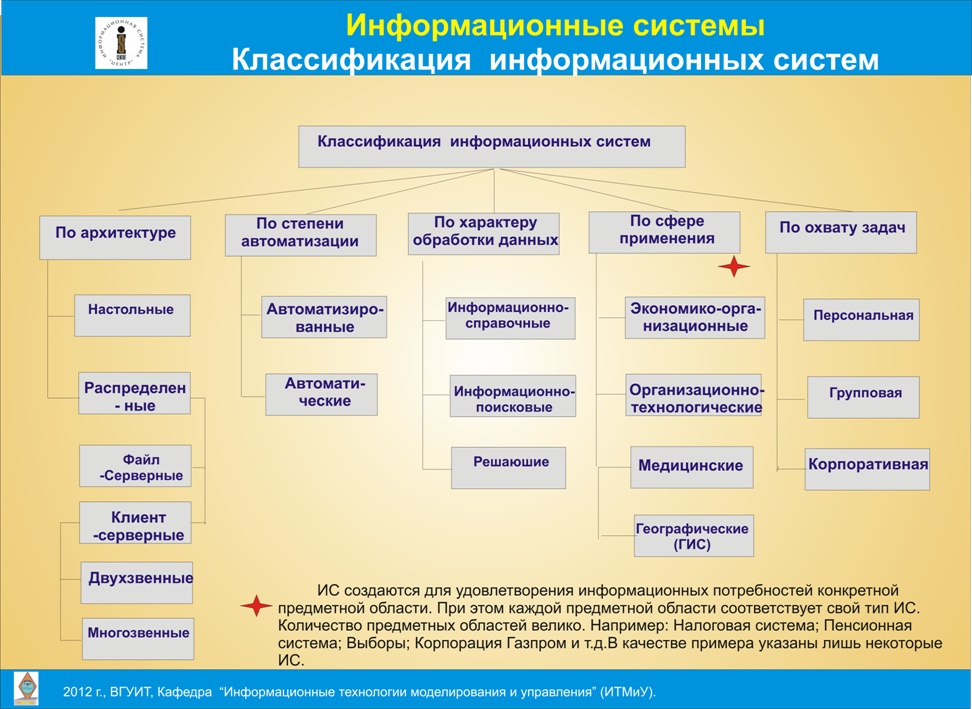 Сначала вы выбираете, какие объекты будут детализированы в отчете. Когда вы запускаете Database Documenter, его отчет содержит все данные о выбранных вами объектах базы данных.
Сначала вы выбираете, какие объекты будут детализированы в отчете. Когда вы запускаете Database Documenter, его отчет содержит все данные о выбранных вами объектах базы данных.
Откройте базу данных, которую вы хотите задокументировать.
На вкладке Инструменты базы данных в группе Анализ щелкните Database Documenter .
В диалоговом окне Documenter щелкните вкладку, соответствующую типу объекта базы данных, который вы хотите задокументировать.Чтобы создать отчет по всем объектам в базе данных, щелкните вкладку All Object Types .
Выберите один или несколько объектов, перечисленных на вкладке. Чтобы выбрать все объекты на вкладке, щелкните Выбрать все .
Щелкните OK .

Database Documenter создает отчет, содержащий подробные данные для каждого выбранного объекта, а затем открывает отчет в режиме предварительного просмотра.Например, если вы запустите Database Documenter для формы ввода данных, отчет, созданный Documenter, перечислит свойства для формы в целом, свойства для каждого из разделов в форме и свойства для любых кнопок, меток , текстовые поля и другие элементы управления в форме, а также все модули кода и разрешения пользователей, связанные с формой.
Чтобы напечатать отчет, на вкладке Предварительный просмотр в группе Печать нажмите Печать .
Исследование таблицы в представлении «Дизайн»
Примечание. Представление «Дизайн» недоступно для таблиц в веб-базах данных.
Открытие таблицы в режиме конструктора позволяет детально просмотреть структуру таблицы.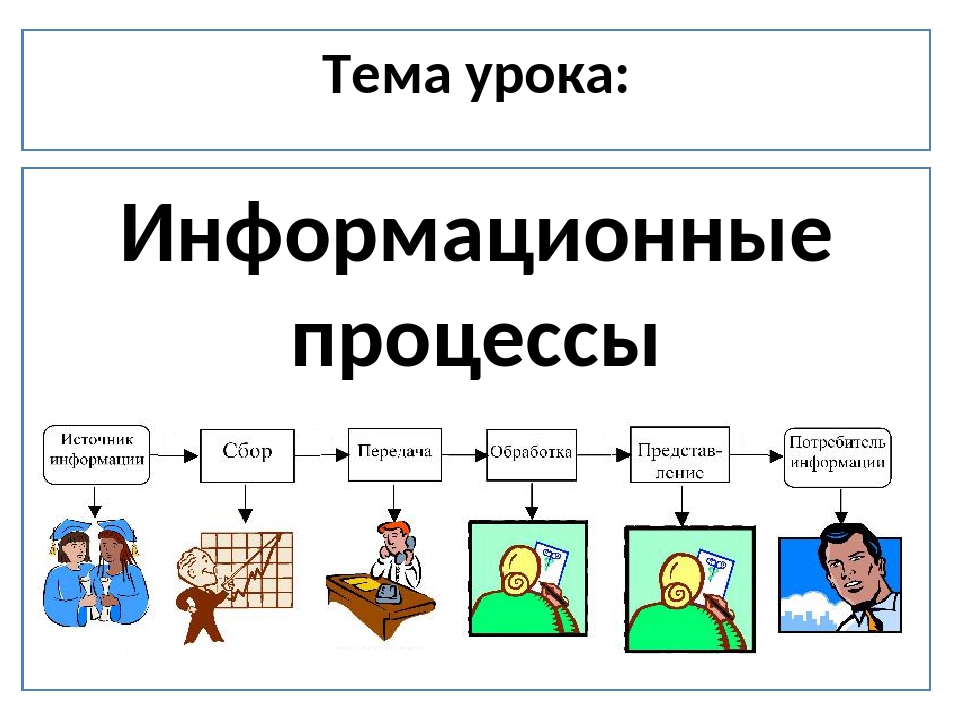 Например, вы можете найти настройку типа данных для каждого поля, найти любые маски ввода или посмотреть, используются ли в таблице какие-либо поля поиска — поля, которые используют запросы для извлечения данных из других таблиц.Эта информация полезна, поскольку типы данных и маски ввода могут повлиять на вашу способность находить данные и выполнять запросы на обновление. Например, предположим, что вы хотите использовать запрос на обновление для обновления определенных полей в одной таблице путем копирования данных в аналогичных полях из другой таблицы. Запрос не будет выполнен, если типы данных для каждого поля в исходной и целевой таблицах не совпадают.
Например, вы можете найти настройку типа данных для каждого поля, найти любые маски ввода или посмотреть, используются ли в таблице какие-либо поля поиска — поля, которые используют запросы для извлечения данных из других таблиц.Эта информация полезна, поскольку типы данных и маски ввода могут повлиять на вашу способность находить данные и выполнять запросы на обновление. Например, предположим, что вы хотите использовать запрос на обновление для обновления определенных полей в одной таблице путем копирования данных в аналогичных полях из другой таблицы. Запрос не будет выполнен, если типы данных для каждого поля в исходной и целевой таблицах не совпадают.
Откройте базу данных, которую вы хотите проанализировать.
В области навигации щелкните правой кнопкой мыши таблицу, которую вы хотите изучить, и выберите Представление «Дизайн» в контекстном меню.
При необходимости запишите имя каждого поля таблицы и тип данных, присвоенный каждому полю.

Тип данных, назначенный полю, может ограничивать размер и тип данных, которые пользователи могут вводить в поле. Например, пользователи могут быть ограничены 20 символами в текстовом поле и не могут вводить текстовые данные в поле с числовым типом данных.
Чтобы определить, является ли поле полем подстановки, щелкните вкладку Поиск в нижней части сетки макета таблицы в разделе Свойства поля .
В поле подстановки отображается один набор значений (одно или несколько полей, например имя и фамилия), но обычно хранится другой набор значений (одно поле, например числовой идентификатор). Например, поле поиска может хранить идентификационный номер сотрудника (сохраненное значение), но отображать имя сотрудника (отображаемое значение). Когда вы используете поле подстановки в выражениях или в операциях поиска и замены, вы используете сохраненное значение, а не отображаемое значение.
 Знакомство с сохраненными и отображаемыми значениями поля поиска — лучший способ убедиться, что выражение или операция поиска и замены, использующая поле поиска, работает так, как вы ожидаете.
Знакомство с сохраненными и отображаемыми значениями поля поиска — лучший способ убедиться, что выражение или операция поиска и замены, использующая поле поиска, работает так, как вы ожидаете.На следующем рисунке показано типичное поле поиска. Помните, что параметры, которые вы видите в свойстве Row Source поля, будут различаться.
Поле подстановки, показанное здесь, использует запрос для извлечения данных из другой таблицы. Вы также можете увидеть поле подстановки другого типа, называемое списком значений, в котором используется жестко запрограммированный список вариантов. На этом рисунке показан типичный список значений.
По умолчанию списки значений используют текстовый тип данных.
Лучший способ найти списки поиска и значений — отобразить вкладку Поиск и щелкнуть записи в столбце Тип данных для каждого поля в таблице.
 Дополнительные сведения о создании полей поиска и списков значений см. по ссылкам в разделе См. также .
Дополнительные сведения о создании полей поиска и списков значений см. по ссылкам в разделе См. также .
Верх страницы
См. отношения между таблицами
Чтобы увидеть графическое представление таблиц в базе данных, полей в каждой таблице и взаимосвязей между этими таблицами, используйте вкладку объекта Отношения .На вкладке объектов «Отношения» представлена общая картина таблицы и структуры отношений в базе данных — важная информация, когда вам нужно создать или изменить отношения между таблицами.
Примечание. Вы также можете использовать вкладку объекта Отношения для добавления, изменения или удаления отношений.
Откройте базу данных, которую вы хотите проанализировать.
На вкладке Инструменты базы данных в группе Отношения щелкните Отношения .

Появится вкладка объекта Отношения , на которой показаны отношения между всеми таблицами в открытой базе данных.
Примечание. Вы не можете использовать вкладку объекта «Отношения» в веб-базе данных или веб-приложении.
Верх страницы
5 Программное обеспечение для информационных систем
5 Программное обеспечение для информационных систем Глава 5Программное обеспечение информационных систем
5.1 Обзор программного обеспечения
Компьютерное оборудование практически бесполезно без компьютера программное обеспечение. Программное обеспечение — это программы, необходимые для ввода, обработки, вывод, хранение и управление деятельностью информационных систем.
Компьютерное программное обеспечение обычно подразделяют на два
основные типы программ: системное программное обеспечение и прикладное программное обеспечение.
Системное программное обеспечение
Системное программное обеспечение – это программы, управляющие ресурсы компьютерной системы и упростить программирование приложений.Они включают программное обеспечение, такое как операционная система, системы управления базами данных, сетевое программное обеспечение, переводчики и программные утилиты.
Прикладное программное обеспечение
Прикладное программное обеспечение – это программы, которые управляют производительность конкретного использования или приложения компьютеров для удовлетворения информации обработка потребностей конечных пользователей. Они включают готовое программное обеспечение, такое как обработка текстов и электронных таблиц. пакеты, а также внутреннее или внешнее программное обеспечение, предназначенное для удовлетворения конкретные потребности организации.
Тенденции в области программного обеспечения отошли от специально разработанных
уникальные программы, разработанные профессиональными программистами или конечными пользователями
организации в отношении использования готовых пакетов программного обеспечения, приобретенных конечными пользователями у
продавцы программного обеспечения.
Доступны два типа упаковки:
1. Вертикальные пакеты — вспомогательные пользователей в определенном отраслевом сегменте. Примеры включают пакеты, которые помогают управлять строительные проекты, отслеживать инвентаризацию больниц или точек быстрого питания.2. Горизонтальные пакеты — банка выполнять определенную общую функцию, такую как бухгалтерский учет или автоматизация делопроизводства, для диапазона предприятий.Взаимосвязь между аппаратными и программными компонентами [Рисунок 5.1][Слайд 5-3]
Рисунок 5.1 — отличный инструмент для объяснения отношения, которые существуют между аппаратным обеспечением компьютерных систем, системным программным обеспечением и программное обеспечение. Эта модель Aonion-skin@ указывает на то, что внешние слои опираются на объекты, предоставленные внутренними.
5.2 Операционные системы
Наиболее важный пакет системного программного обеспечения для любого
компьютер — это его операционная система. Каждая компьютерная система работает под управлением
Операционная система. Операционные системы для компьютеров, которыми пользуются многие пользователи,
значительно сложнее, чем операционные системы для персональных компьютеров.
Каждая компьютерная система работает под управлением
Операционная система. Операционные системы для компьютеров, которыми пользуются многие пользователи,
значительно сложнее, чем операционные системы для персональных компьютеров.
Что делает операционная система?
Операционная система — это программное обеспечение, которое контролирует все ресурсы компьютерной системы.Например это:
1. Назначает необходимые оборудование к программам 2. Расписание программ для выполнение на процессоре 3. Выделяет память требуется для каждой программы 4. Назначает необходимые устройства ввода и вывода 5. Управляет данными и программные файлы, хранящиеся во вторичном хранилище 6. Поддерживает файл каталоги и обеспечивает доступ к данным в файлах 7. Взаимодействует с пользователями
Мультипрограммирование — это возможности компьютера
одновременное выполнение нескольких программ на одном процессоре с помощью одного из
программы, использующие процессор, в то время как другие выполняют ввод или вывод.
Мультипрограммирование требует, чтобы активные части программы, конкурирующие за процессор, должны быть доступны в оперативной памяти. Виртуальная память кажущаяся увеличенная емкость основной памяти компьютера, и достигаемая за счет сохраняя в оперативной памяти только те части программ, которые необходимы в данный момент, с полные программы, хранящиеся во вторичном хранилище.
Режимы работы компьютерной системы
Операционные системы позволяют системе, которой они управляют, работать в различных режимах.К ним относятся пакетная обработка, разделение времени и работа в режиме реального времени. обработка.
Пакетная обработка Программы обработки или транзакции пакетами, без участия пользователя взаимодействие.
Системы с разделением времени, обеспечивающие интерактивность
обработка путем выделения короткого временного интервала для использования сервера каждому пользователю в
повернуть.
Системы обработки в реальном времени, которые реагируют на событие в течение фиксированного интервала времени; используется, например, на производственных предприятиях или для собирать данные с нескольких единиц оборудования в лаборатории.
С переходом на мультипроцессоры, в которых несколько (или даже много) процессоров настраиваются в одной компьютерной системе, многопроцессорность операционные системы были разработаны для распределения работы между несколькими процессорами. Эти системы также поддерживают мультипрограммирование, что позволяет многим программам конкурировать за процессоры.
Операционные системы для персональных компьютеров
Операционные системы персональных компьютеров,
предназначенные для одного пользователя, намного проще, чем операционные системы, работающие на больших
компьютеры, к которым могут иметь одновременный доступ сотни или тысячи пользователей.Один
важной возможностью, которую операционная система может предложить в среде персональных компьютеров, является многозадачность :
возможность запускать сразу несколько задач от имени пользователя.
Самые популярные операционные системы для микрокомпьютеров:
Windows 95 — Windows 95 — это усовершенствованная операционная система
.— графический интерфейс пользователя
— настоящая многозадачность
— сетевые возможности
— мультимедиа
DOS — старая операционная система, которая использовалась на микрокомпьютеры
— это однопользовательская однозадачная операционная система
.— можно добавить графический интерфейс и возможности многозадачности. с помощью операционной среды, такой как Microsoft Windows
OS/2 Warp — графический интерфейс пользователя
— многозадачность
— возможности виртуальной памяти
— телекоммуникационные возможности
Windows NT — многозадачная сетевая операционная система
— многопользовательская сетевая операционная система
— устанавливается на сетевых серверах для управления локальной территорией сети с требованиями к высокопроизводительным вычислениям
UNIX — популярная операционная система который доступен для микро-, мини-компьютерных систем и мейнфреймов
— многозадачная и многопользовательская система
— устанавливается на сетевых серверах
MacIntosh System 7 — многозадачность
— возможности виртуальной памяти
— графический интерфейс пользователя
Пользовательский интерфейс
Пользовательский интерфейс представляет собой комбинацию средств, с помощью которых
пользователь взаимодействует с компьютерной системой. Он позволяет конечному пользователю общаться с
операционной системы, чтобы они могли загружать программы, получать доступ к файлам и выполнять другие задачи. То
три основных типа пользовательских интерфейсов:
Он позволяет конечному пользователю общаться с
операционной системы, чтобы они могли загружать программы, получать доступ к файлам и выполнять другие задачи. То
три основных типа пользовательских интерфейсов:
1. Командный диск 2. Управление меню 3. Графический пользовательский интерфейс (графический интерфейс)
Самый популярный графический интерфейс пользователя — это предоставляется Windows 95. Среда Windows стала стандартной платформой для компьютеры.
Цель открытых систем
Стремление к использованию открытых систем в организационных вычислений, чтобы программное и аппаратное обеспечение любого поставщика могло работать с оборудованием любого другой требует операционной системы, которая будет работать на любой аппаратной платформе.Термин система Aopen@ используется как противоположность проприетарным системам конкретного производителя.
В открытых системах организациям нужна мобильность,
масштабируемость и совместимость прикладного программного обеспечения.
Портативное приложение: можно перенести с одного компьютера системы в другую.
Масштабируемое приложение: это приложение, которое можно перемещать без существенное перепрограммирование.
Совместимость: означает, что машины различных поставщики и возможности могут работать вместе для получения необходимой информации.
5.3 Программное обеспечение для личной продуктивности
Программное обеспечение для личной продуктивности является наиболее распространенным прикладное программное обеспечение. Запускаемые на персональных компьютерах, эти программы помогают пользователю в определенный круг задач. В совокупности с профессиональными вспомогательными системами и системами поддерживающее групповую работу, программное обеспечение для личной продуктивности является мощным средством реализации сегодняшних работа со знаниями.
Функции программного обеспечения для персональной производительности [Рис. 5.3][Слайд 5-4]
Программное обеспечение для повышения
производительность пользователя по определенному кругу общих задач. Это программное обеспечение поддерживает базу данных
управление и анализ, создание и презентация, а также отслеживание действий и заметок. Все
это программные приложения. Управление данными поддерживается управлением базой данных
систем, а программное обеспечение для работы с электронными таблицами помогает в анализе данных. Для нужд авторства
и презентации, пользователи используют прикладное программное обеспечение для обработки текстов, настольных
издательское дело, создание презентаций и мультимедиа. Управление личной информацией
программное обеспечение используется для отслеживания действий и личных заметок.Коммуникационное программное обеспечение позволяет
пользователю подключаться к телекоммуникационной сети для обмена информацией с
других пользователей или систем. Веб-браузеры используются для доступа к ресурсам Интернета.
Всемирная сеть.
Это программное обеспечение поддерживает базу данных
управление и анализ, создание и презентация, а также отслеживание действий и заметок. Все
это программные приложения. Управление данными поддерживается управлением базой данных
систем, а программное обеспечение для работы с электронными таблицами помогает в анализе данных. Для нужд авторства
и презентации, пользователи используют прикладное программное обеспечение для обработки текстов, настольных
издательское дело, создание презентаций и мультимедиа. Управление личной информацией
программное обеспечение используется для отслеживания действий и личных заметок.Коммуникационное программное обеспечение позволяет
пользователю подключаться к телекоммуникационной сети для обмена информацией с
других пользователей или систем. Веб-браузеры используются для доступа к ресурсам Интернета.
Всемирная сеть.
Электронные таблицы
Пакеты электронных таблиц представляют собой программы
которые используются для анализа, планирования и моделирования. Они обеспечивают электронную замену
для более традиционных инструментов, таких как бумажные рабочие листы, карандаши и калькуляторы.В
таблица строк и столбцов хранится в памяти компьютера и отображается на
видео экран. Данные и формулы вводятся в рабочий лист, и компьютер выполняет
расчеты по введенным формулам. Пакет электронных таблиц также можно использовать в качестве
инструмент поддержки принятия решений для выполнения анализа «что, если».
Они обеспечивают электронную замену
для более традиционных инструментов, таких как бумажные рабочие листы, карандаши и калькуляторы.В
таблица строк и столбцов хранится в памяти компьютера и отображается на
видео экран. Данные и формулы вводятся в рабочий лист, и компьютер выполняет
расчеты по введенным формулам. Пакет электронных таблиц также можно использовать в качестве
инструмент поддержки принятия решений для выполнения анализа «что, если».
Управление базой данных
Пакеты управления базами данных облегчают хранение, обслуживание и использование данных в базе данных, совместно используемой многими пользователями.Микрокомпьютерные DBM позволяют пользователям:
1. Создайте и поддерживайте база данных
2. Запросите базу данных с помощью язык запросов 3. Подготовьте отформатированный отчеты
Кроме того, пакеты предлагают функции безопасности, сетевые
подключение и возможность представлять графический вывод, а также выполнять
расчеты табличного типа.
Обработка текстов
Пакеты обработки текстов — это программы, которые компьютеризировать создание, издание и печать документов путем электронной обработки текстовые данные.Обработка текстов является важным приложением автоматизации делопроизводства. Слово обработка — самая популярная авторская и презентационная деятельность. Фактически, это наиболее распространенное приложение для персональных компьютеров.
Настольная издательская система
Организации используют программное обеспечение для настольных издательских систем, чтобы
производить свои собственные печатные материалы, такие как информационные бюллетени, брошюры, руководства и книги с
несколько стилей шрифта, графики и цветов на каждой странице. Компоненты, необходимые для настройки
скромная настольная издательская система включает в себя: дисплей с высоким разрешением, лазерный принтер,
программное обеспечение для настольных издательских систем и, возможно, сканер.
Программное обеспечение для презентаций
Целью презентационной графики является предоставление информация в графической форме, которая помогает конечным пользователям и менеджерам понять бизнес предложения и производительность и принимать лучшие решения по ним. Важно отметить что презентационная графика не заменяет отчеты и отображение чисел и текста материал.
Программное обеспечение для создания мультимедиа
Программное обеспечение для создания мультимедиа позволяет пользователям разрабатывать мультимедийные презентации.Используя эти пакеты, вы можете разработать привлекательные программное обеспечение курсов компьютерного обучения (CBT) или презентации для клиентов. Это программное обеспечение имеет превосходные графические изображения, компьютерная анимация и движущееся видео, которые можно комбинировать с высококачественный звук в сочетании с текстом.
Гипермедиа – это электронные документы,
содержать несколько форм мультимедиа, включая текст, графику, видео, голосовые сообщения или другие
единиц информации, таких как рабочие листы. В гипермедийном способе доставки информации
связи могут быть установлены между различными элементами в большом мультимедийном документе.Эти
связи позволяют пользователю переходить от одной темы непосредственно к связанной, а не
последовательно сканировать информацию. Гипертекст – это методология построения и
интерактивное использование текстовых баз данных. По определению, гипертекст содержит только текст и
ограниченное количество графики.
В гипермедийном способе доставки информации
связи могут быть установлены между различными элементами в большом мультимедийном документе.Эти
связи позволяют пользователю переходить от одной темы непосредственно к связанной, а не
последовательно сканировать информацию. Гипертекст – это методология построения и
интерактивное использование текстовых баз данных. По определению, гипертекст содержит только текст и
ограниченное количество графики.
Управление личной информацией
Пакеты управления личной информацией (PIM) инструменты, которые помогают работникам умственного труда отслеживать задачи, людей, проекты, обязательства и идеи.Эти пакеты помогают конечным пользователям хранить, упорядочивать и извлекать текстовые и числовые данные. в виде заметок, списков, вырезок, таблиц, служебных записок, писем, отчетов и так далее.
Коммуникационное программное обеспечение и веб-браузер
Коммуникационное программное обеспечение позволяет пользователю
подключиться к телекоммуникационной сети для обмена информацией с другими пользователями
или системы. Программное обеспечение предоставляет следующие возможности:
Программное обеспечение предоставляет следующие возможности:
1. Отправка и получение электронная почта 2.Передача файлов. Ты сможешь загрузить программу или файл данных с удаленного компьютера на свою рабочую станцию или загрузить файл на удаленный компьютер. 3. Эмуляция терминала — позволяя персональному компьютеру действовать как терминал, когда это требуется в конкретном случае применение. 4. Отправка и получение факс
Все чаще причина подключения к телекоммуникационная сеть должна получить доступ к ресурсам Интернета. Интернет браузеры быстро становятся одной из самых популярных категорий программных пакетов.Браузер это программа, которая позволяет пользователю получать доступ к электронным документам, включенным в Всемирная паутина Интернета, набор взаимосвязанных баз данных гипермедиа, распределенных среди удаленных сайтов.
5.4 Языки программирования и их трансляторы [Рис. 5.8][Слайд 5-5]
Большая часть программного обеспечения, используемого в
организация должна быть запрограммирована или настроена. Языки программирования — это языки
какие компьютерные программы написаны на инт.Язык программирования позволяет программисту или
пользователю разрабатывать наборы инструкций, которые составляют компьютерную программу. Эти
языки развивались на протяжении четырех поколений и могут быть сгруппированы в пять основных
категории:
Языки программирования — это языки
какие компьютерные программы написаны на инт.Язык программирования позволяет программисту или
пользователю разрабатывать наборы инструкций, которые составляют компьютерную программу. Эти
языки развивались на протяжении четырех поколений и могут быть сгруппированы в пять основных
категории:
1. Машинные языки 2. Языки ассемблера 3. Языки высокого уровня 4. Четвертое поколение языки 5. Объектно-ориентированный языки
Машинные языки:
Машинные языки — самый базовый уровень языки программирования.Они были первым поколением машинных языков.
Недостатки машинных языков:
1. Программы приходилось писать с использованием двоичных кодов уникальным для каждого компьютера.
2. Программисты должны были детально знать внутренние операции конкретного типа процессора, который они использовали.
3. Программирование было сложным и подвержено ошибкам
4.Программы не переносим на другие компьютеры.
Языки ассемблера:
Ассемблерные языки являются вторым поколением языков ассемблера. машинные языки.Они были разработаны, чтобы уменьшить трудности с пишущей машиной. языковые программы. Язык ассемблера также является языком низкого уровня (относится к машинным ресурсов, таких как регистры и адреса памяти), это также специфично для компьютера. Модель или серия моделей.
Программа на ассемблере переведена в машинный язык с помощью простого транслятора, называемого ассемблером . сборка сегодня языки используются только тогда, когда необходим жесткий контроль над аппаратными ресурсами компьютера. требуется, например, в некоторых системных программах, особенно для вычислений в реальном времени.
Преимущества:
1. Использует символьные закодированные инструкции, которые легче запомнить
2. Программирование упрощается, поскольку программист не необходимо знать точное место хранения данных и инструкций.
3. Эффективное использование компьютерные ресурсы перевешиваются высокими затратами на очень утомительную разработку систем и блокировкой переносимости программы.

Недостаток:
1.Языки ассемблера уникальны для определенных типов компьютеров.
2. Программы не переносим на другие компьютеры.
Языки высокого уровня (процедурные)
Языки высокого уровня третьего поколения языки программирования. Эти языки содержат утверждения, каждое из которых переводится на несколько инструкций машинного языка. Языки высокого уровня включают COBOL (бизнес прикладные программы), BASIC (конечные пользователи микрокомпьютеров), FORTRAN (научные и инженерные приложения), и более популярными сегодня являются C, C++ и Visual Basic.
Преимущества:
1. Легче изучить и понять, чем ассемблер язык как инструкции ( операторов) которые напоминают человеческий язык или стандартный обозначение математики.
2. Иметь менее жесткие правила, формы и синтаксис, чтобы снижается вероятность ошибки.
3. Являются машинно-независимыми программами, поэтому программы написанные на языке высокого уровня, не нужно перепрограммировать при установке нового компьютера. установлен.
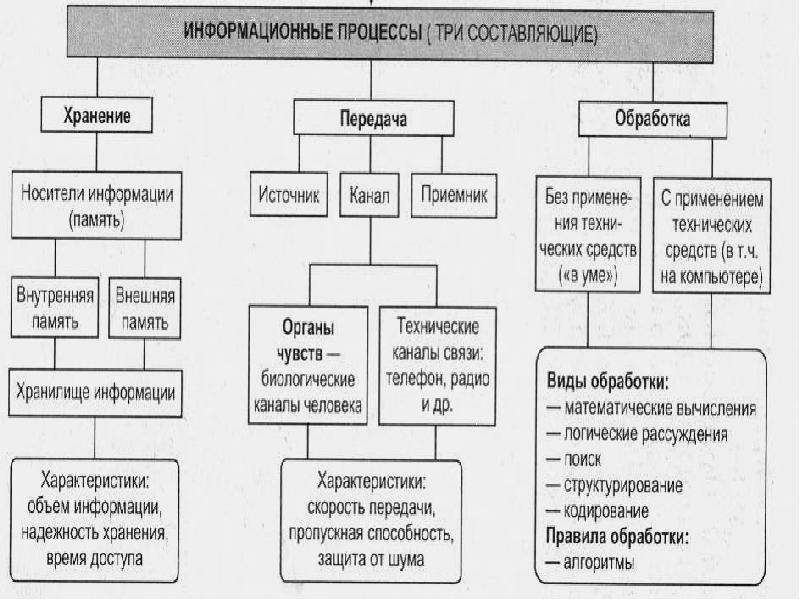
4. Программистам не нужно учить новый язык для каждый компьютер, который они программируют.
Недостатки:
1. Менее эффективны, чем программы на языке ассемблера. и требуют большего количества компьютерного времени для перевода в машинные инструкции.
Помимо языков программирования высокого уровня
Языки четвертого поколения (4GL) определяют, что необходимо сделать, а не детализировать шаги для этого.4GL включают в себя различные языки программирования, которые являются более непроцедурными и диалоговыми, чем предыдущие языки.
Преимущества:
1.
Упрощен процесс программирования.
2. Используйте непроцедурные языки, поощряющие пользователей и программисты определяют результаты, которые они хотят, в то время как компьютеры определяют последовательность инструкций, которые обеспечат эти результаты.
3. Используйте естественные языки, не навязывающие жесткого грамматические правила
Недостатки:
1.Менее гибкий, чем другие языки
2. Менее эффективный (с точки зрения скорости обработки и необходимая емкость хранилища).
На принадлежность к пятое поколение. Следующие типы языков программирования, вероятно, повлияют на развитие такой новой парадигмы:
1. Объектно-ориентированный языки программирования (ООП) связывают элементы данных и процедуры или действия, которые будут выполняются на них, вместе в объекты.Примеры включают Smalltalk, C++, Visual Basic, Java, Турбо С++, С++, Объект С+ 2.Языки, которые облегчить параллельную обработку в системах с большим количеством процессоров. 3. Функциональные языки (например, LISP), основанный на математической концепции вычислений как приложения функции. 4. Ограниченные подмножества естественные языки, которые можно обрабатывать благодаря прогрессу в искусственных интеллект.
Преимущества:
1. Языки ООП проще в использовании и более эффективен для программирования ориентированного на графику пользовательского интерфейса, необходимого многим Приложения.
2. Запрограммированные объекты можно использовать повторно.
Переводчики: компиляторы и интерпретаторы
Различные пакеты программного обеспечения доступны, чтобы помочь
программисты разрабатывают компьютерные программы. Например, переводчики языков программирования
программы, которые переводят другие программы в коды инструкций машинного языка, которые
компьютеры могут выполнять. Другие программные пакеты, называемые инструментами программирования, помогают программистам.
писать программы, предоставляя средства для создания и редактирования программ. Язык
программы-переводчики (языковые процессоры) — это программы, которые переводят другие программы в
коды инструкций машинного языка, которые может выполнять компьютер. Эти программы позволяют вам
писать свои собственные программы, предоставляя средства создания и редактирования программ.
Другие программные пакеты, называемые инструментами программирования, помогают программистам.
писать программы, предоставляя средства для создания и редактирования программ. Язык
программы-переводчики (языковые процессоры) — это программы, которые переводят другие программы в
коды инструкций машинного языка, которые может выполнять компьютер. Эти программы позволяют вам
писать свои собственные программы, предоставляя средства создания и редактирования программ.
Программы-переводчики языков программирования известны разнообразие имен.
Ассемблер: перевод символической инструкции коды программ, написанных на языке ассемблера, в инструкции машинного языка.
Компилятор: переводит (компилирует) язык высокого уровня операторы (исходные программы) в программы машинного языка.
Интерпретатор: переводит и выполняет каждую программу
оператор по одному, вместо того, чтобы сначала создавать полную программу на машинном языке,
как это делают компиляторы и ассемблеры.
5.5 Языки четвертого поколения: (4GL)
4GL включают множество языков программирования, которые являются более непроцедурными и разговорными, чем предыдущие языки.Использование Языки четвертого поколения позволяют в несколько раз увеличить производительность в сфере информации. разработка систем.
Категории языков четвертого поколения и их Роль в вычислениях для конечных пользователей
Отличительной чертой 4GL является то, что они определяют что делать а не как это сделать . Характеристики 4GL включают:
1. Языки непроцедурный 2. Они не указывают полная процедура выполнения задачи (заполняется программой переводчик для 4GL).3. Около одной десятой в 4GL требуется больше инструкций, чем в процедурных языках. [Фигура 5.12] 4. Основные категории 4GL — это языки запросов, генераторы отчетов и генераторы приложений — 90–109. Рисунок 5.13 [Слайд 5-6] 5. Языки запросов и Генераторы отчетов избавляют от необходимости разрабатывать определенные приложения, предоставляя прямые доступ к базе данных.Генераторы приложений позволяют относительно легко указать в непроцедурные условия система для такого доступа.6. У 4GL также есть программное обеспечение генераторы для создания систем поддержки принятия решений и исполнительных информационных систем.
Три категории 4GL:
1. Язык запросов
2. Генераторы отчетов 3. Генераторы приложений
Языки запросов
Языки запросов позволяют конечным пользователям получать доступ к базам данных напрямую. Характеристики языка запросов включают:
1. Используется онлайн для ad-hoc запросы, то есть запросы, которые не определены заранее 2.Результат запроса обычно не форматируется, поскольку отображается в формате по умолчанию, выбранном системой сам. 3. Взаимодействие обычно простой, используются только очень простые вычисления. 4. Большинство языков запросов также позволяют обновлять базы данных. Благодаря многим языкам запросов можно запросить графический вывод на запрос.

Шесть основных стилей для запросов к базе данных:
1. Заполнение формы 2. Выбор меню 3. Командный запрос язык, например SQL 4.Запрос на примере (QBE) 5. Прямая манипуляция 6. Ограниченный натуральный язык
Языки запросов подходят для:
1. Автоматический кассир машины 2. Электронные киоски
Генераторы отчетов
Генератор отчетов позволяет конечному пользователю или специалист по информационным системам, чтобы подготовить отчет без детализации всех необходимых шаги, такие как форматирование документа.
Характеристики генераторов отчетов включают:
1.Предлагайте пользователям больше контролировать содержание и внешний вид вывода, чем язык запросов. 2. Указанные данные могут быть извлечены из указанных файлов или баз данных, сгруппированы, упорядочены и обобщены в указанным способом и отформатирован для печати по желанию.

Генераторы приложений
Генератор приложений позволяет указать целое приложение, состоящее из нескольких программ, без особого подробного кодирования. Характеристики генераторов приложений включают:
1.Большинство генераторов производят (генерировать) код на процедурном языке. Затем этот код может быть изменен в соответствии с точные потребности приложения.
2. Целевые генераторы по отношению к конечным пользователям просты в использовании. Они нацелены на ограниченный домен приложений. Они производят код в основном из спецификации структуры файлов и баз данных. и из заданных макетов экранов и отчетов. Указана необходимая обработка в терминах, естественных для конечных пользователей. 3.Трафаретная живопись Средство позволяет указать графический интерфейс пользователя для системы под разработка. 4. Мощное приложение генераторы требуют опыта специалистов по информационным системам и инструменты общего назначения.Они часто могут работать на мэйнфреймах и миникомпьютерах. 5. Генераторы приложений все больше интегрируются в среды автоматизированной разработки программного обеспечения (CASE).
Преимущества:
1.Упростил процесс программирования.
2. Используйте непроцедурные языки, поощряющие пользователей и программисты определяют результаты, которые они хотят, в то время как компьютеры определяют последовательность инструкций, которые обеспечат эти результаты.
3. Используйте естественные языки, не навязывающие жесткого грамматические правила
Недостатки:
1. Менее гибкий, чем другие языки
2. Программы, написанные на 4GL, как правило, гораздо менее эффективен при выполнении программы, которая программирует на языках высокого уровня.Поэтому их использование ограничено проектами, которые не требуют такой эффективности.
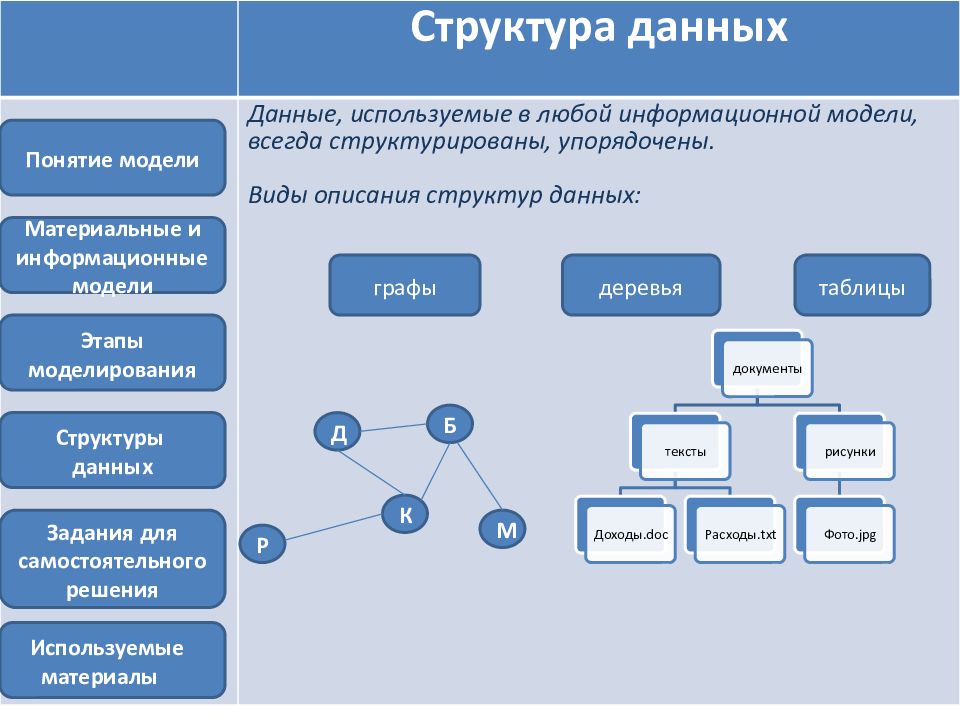
5.6 Объектно-ориентированные языки
Идея объектно-ориентированного программирования (ООП) состоит в том, чтобы создавать программы программных объектов, чтобы связать элементы данных и процедуры или действия, которые будут выполняться над ними, объединяются в объекты. Примеры включают Smalltalk, С++, Турбо С++, Объект С+, Java.
Характеристики ООП включают:
1.ООП, объекты объединяются (инкапсулировать) данные с операциями, которые воздействуют на данные. 2. Класс поддержки ООП определение и наследование, создание объектов как экземпляров классов, отправка сообщений в методы в этих объектах во время выполнения программы и другие особенности ООП. 3. ООП упрощает проектирование мультимедийных систем и графических пользовательских интерфейсов.
Три фундаментальные концепции объектно-ориентированного программирование:
1. Объекты 2. Классы 3.Наследование
Объекты: основные компоненты, из которых состоят программы. построен.В программном обеспечении — программный компонент, который моделирует реальный объект путем инкапсуляции данные и инструкции, которые работают с этими данными.
Класс: это шаблон, из которого создаются объекты. Классы могут быть определены в иерархии.
Наследование: в объектно-ориентированном программировании, классы ниже в иерархии наследует свойства (атрибуты и методы) классов выше в нем.
Преимущества:
1. Языки ООП проще в использовании и более эффективен для программирования ориентированного на графику пользовательского интерфейса, необходимого многим Приложения.
2. Экономит много времени на программирование, так как наследование свойств означает, что запрограммированные объекты можно использовать повторно.
Что такое структуры данных? — Определение из WhatIs.
 com
comСтруктура данных — это специализированный формат для организации, обработки, поиска и хранения данных. Существует несколько основных и расширенных типов структур данных, все из которых предназначены для организации данных в соответствии с определенной целью. Структуры данных упрощают пользователям доступ к нужным им данным и работу с ними надлежащим образом.Самое главное, структуры данных определяют организацию информации, чтобы машины и люди могли лучше ее понимать.
В информатике и компьютерном программировании структура данных может быть выбрана или предназначена для хранения данных с целью их использования с различными алгоритмами. В некоторых случаях основные операции алгоритма тесно связаны с дизайном структуры данных. Каждая структура данных содержит информацию о значениях данных, взаимосвязях между данными и, в некоторых случаях, о функциях, которые можно применять к данным.
Например, в объектно-ориентированном языке программирования структура данных и связанные с ней методы связаны вместе как часть определения класса. В необъектно-ориентированных языках могут быть определены функции для работы со структурой данных, но технически они не являются частью структуры данных.
В необъектно-ориентированных языках могут быть определены функции для работы со структурой данных, но технически они не являются частью структуры данных.
Типичных базовых типов данных, таких как целые числа или значения с плавающей запятой, которые доступны в большинстве языков компьютерного программирования, как правило, недостаточно для того, чтобы уловить логический смысл обработки и использования данных.Тем не менее, приложения, которые принимают, обрабатывают и производят информацию, должны понимать, как данные должны быть организованы, чтобы упростить обработку. Структуры данных логически объединяют элементы данных и облегчают эффективное использование, сохранение и совместное использование данных. Они обеспечивают формальную модель, описывающую способ организации элементов данных.
Структуры данных являются строительными блоками для более сложных приложений. Они разрабатываются путем объединения элементов данных в логическую единицу, представляющую абстрактный тип данных, который имеет отношение к алгоритму или приложению. Примером абстрактного типа данных является «имя клиента», состоящее из строк символов «имя», «отчество» и «фамилия».
Примером абстрактного типа данных является «имя клиента», состоящее из строк символов «имя», «отчество» и «фамилия».
Важно не только использовать структуры данных, но также важно выбирать правильную структуру данных для каждой задачи. Выбор неподходящей структуры данных может привести к замедлению времени выполнения или зависанию кода. Пять факторов, которые следует учитывать при выборе структуры данных, включают следующие:
- Какая информация будет храниться?
- Как эта информация будет использоваться?
- Где должны сохраняться или храниться данные после их создания?
- Как лучше организовать данные?
- Какие аспекты управления резервированием памяти и хранилища следует учитывать?
Как используются структуры данных?
Как правило, структуры данных используются для реализации физических форм абстрактных типов данных.Структуры данных являются важной частью разработки эффективного программного обеспечения. Они также играют решающую роль в разработке алгоритмов и в том, как эти алгоритмы используются в компьютерных программах.
Ранние языки программирования, такие как Fortran, C и C++, позволяли программистам определять свои собственные структуры данных. Сегодня многие языки программирования включают обширный набор встроенных структур данных для организации кода и информации. Например, списки и словари Python, а также массивы и объекты JavaScript являются распространенными структурами кодирования, используемыми для хранения и извлечения информации.
Инженеры-программисты используют алгоритмы, которые тесно связаны со структурами данных, такими как списки, очереди и сопоставления одного набора значений с другим. Этот подход можно использовать в различных приложениях, включая управление коллекциями записей в реляционной базе данных и создание индекса этих записей с использованием структуры данных, называемой двоичным деревом.
Этот подход можно использовать в различных приложениях, включая управление коллекциями записей в реляционной базе данных и создание индекса этих записей с использованием структуры данных, называемой двоичным деревом.
Некоторые примеры использования структур данных включают следующее:
- Хранение данных. Структуры данных используются для эффективного сохранения данных, например для определения набора атрибутов и соответствующих структур, используемых для хранения записей в системе управления базами данных.
- Управление ресурсами и услугами. Ресурсы и службы базовой операционной системы (ОС) включаются за счет использования структур данных, таких как связанные списки для выделения памяти, управления файловыми каталогами и деревьями структуры файлов, а также очередей планирования процессов.
- Обмен данными. Структуры данных определяют организацию информации, совместно используемой приложениями, например пакетов TCP/IP.

- Заказ и сортировка. Структуры данных, такие как двоичные деревья поиска, также известные как упорядоченное или отсортированное двоичное дерево, предоставляют эффективные методы сортировки объектов, таких как строки символов, используемые в качестве тегов. С помощью таких структур данных, как очереди с приоритетом, программисты могут управлять элементами, организованными в соответствии с определенным приоритетом.
- Индексация .Еще более сложные структуры данных, такие как B-деревья, используются для индексации объектов, например, хранящихся в базе данных.
- Поиск. Индексы, созданные с использованием бинарных деревьев поиска, B-деревьев или хэш-таблиц, ускоряют поиск определенного искомого элемента.
- Масштабируемость. Приложения для работы с большими данными используют структуры данных для распределения и управления хранилищем данных в распределенных хранилищах, обеспечивая масштабируемость и производительность.
 Некоторые среды программирования больших данных, такие как Apache Spark, предоставляют структуры данных, которые отражают базовую структуру записей базы данных для упрощения запросов.
Некоторые среды программирования больших данных, такие как Apache Spark, предоставляют структуры данных, которые отражают базовую структуру записей базы данных для упрощения запросов.
Структуры данных часто классифицируют по их характеристикам. Следующие три характеристики являются примерами:
- Линейная или нелинейная. Эта характеристика описывает, расположены ли элементы данных в последовательном порядке, например в виде массива, или в неупорядоченной последовательности, например в виде графика.
- Гомогенные или гетерогенные. Эта характеристика описывает, относятся ли все элементы данных в данном репозитории к одному типу. Одним из примеров является набор элементов в массиве или различных типов, таких как абстрактный тип данных, определенный как структура в C или спецификация класса в Java.
- Статическая или динамическая. Эта характеристика описывает, как компилируются структуры данных.
 Статические структуры данных имеют фиксированные размеры, структуры и места в памяти во время компиляции.Динамические структуры данных имеют размеры, структуры и области памяти, которые могут уменьшаться или расширяться в зависимости от использования.
Статические структуры данных имеют фиксированные размеры, структуры и места в памяти во время компиляции.Динамические структуры данных имеют размеры, структуры и области памяти, которые могут уменьшаться или расширяться в зависимости от использования.
Если структуры данных являются строительными блоками алгоритмов и компьютерных программ, то примитивные или базовые типы данных являются строительными блоками структур данных. Типичные базовые типы данных включают следующие:
- Логическое значение , в котором хранятся логические значения, которые являются либо истинными, либо ложными.
- целое число , в котором хранится диапазон математических целых чисел или счетных чисел.Целые числа разного размера содержат разный диапазон значений — например, 8-битное целое со знаком содержит значения от -128 до 127, а длинное 32-битное целое без знака содержит значения от 0 до 4 294 967 295.

- Числа с плавающей запятой , хранящие формульное представление действительных чисел.
- Числа с фиксированной точкой , которые используются в некоторых языках программирования и содержат действительные значения, но обрабатываются как цифры слева и справа от десятичной точки.
- Символ , который использует символы из определенного отображения целочисленных значений в символы.
- Указатели, которые являются опорными значениями, указывающими на другие значения.
- Строка , представляющая собой массив символов, за которым следует код остановки — обычно значение «0» — или управляется с помощью поля длины, которое представляет собой целочисленное значение.
Тип структуры данных, используемый в конкретной ситуации, определяется типом операций, которые потребуются, или видами алгоритмов, которые будут применяться. Различные типы структур данных включают следующие:
Различные типы структур данных включают следующие:
- Массив. Массив хранит набор элементов в смежных ячейках памяти. Элементы одного типа хранятся вместе, поэтому положение каждого элемента можно легко вычислить или получить с помощью индекса. Массивы могут быть фиксированными или гибкими по длине.
- Стек . В стеке хранится коллекция элементов в линейном порядке применения операций. Этот порядок может быть последним пришел, первым ушел (LIFO) или первым пришел, первым ушел (FIFO).
- Очередь . Очередь хранит набор элементов подобно стеку; однако порядок операций может быть только «первым пришел, первым вышел».
- Связанный список. Связанный список хранит набор элементов в линейном порядке.
 Каждый элемент или узел в связанном списке содержит элемент данных, а также ссылку или ссылку на следующий элемент в списке.
Каждый элемент или узел в связанном списке содержит элемент данных, а также ссылку или ссылку на следующий элемент в списке.
- Дерево. В дереве хранится набор элементов в абстрактной иерархической форме. Каждый узел связан со значением ключа, а родительские узлы связаны с дочерними узлами или подузлами. Существует один корневой узел, который является предком всех узлов в дереве.
- Куча. Куча — это древовидная структура, в которой значение ключа, связанное с каждым родительским узлом, больше или равно значению ключа любого из его дочерних значений ключа.
- График. График хранит набор элементов нелинейным образом.
 Графы состоят из конечного набора узлов, также известных как вершины, и соединяющих их линий, также известных как ребра. Они полезны для представления реальных систем, таких как компьютерные сети.
Графы состоят из конечного набора узлов, также известных как вершины, и соединяющих их линий, также известных как ребра. Они полезны для представления реальных систем, таких как компьютерные сети. - Трие. Дерево, также известное как дерево ключевых слов, представляет собой структуру данных, в которой строки хранятся как элементы данных, которые можно организовать в виде визуального графа.
- Хэш-таблица. Хеш-таблица, также известная как хэш-карта, хранит набор элементов в ассоциативном массиве, который отображает ключи в значения. Хеш-таблица использует хеш-функцию для преобразования индекса в массив сегментов, содержащих нужный элемент данных.
Они считаются сложными структурами данных, поскольку могут хранить большие объемы взаимосвязанных данных.
Как выбрать структуру данныхПри выборе структуры данных для программы или приложения разработчики должны учитывать ответы на следующие три вопроса:
- Поддерживаемые операции.
 2).
2). - Элегантность программирования. Удобны ли организация структуры данных и ее функциональный интерфейс?
Некоторые реальные примеры включают:
- Связанные списки лучше всего подходят, если программа управляет коллекцией элементов, которые не нужно заказывать, требуется постоянное время для добавления или удаления элемента из коллекции, а увеличение времени поиска допустимо.
- Стеки лучше всего подходят, если программа управляет коллекцией, которая должна поддерживать порядок LIFO.
- Очереди следует использовать, если программа управляет коллекцией, которая должна поддерживать порядок FIFO.
- Двоичные деревья хороши для управления коллекцией элементов с отношениями родитель-потомок, например генеалогическим древом.
- Двоичные деревья поиска подходят для управления отсортированной коллекцией, когда целью является оптимизация времени, необходимого для поиска определенных элементов в коллекции.
