Что лучше УСН или ЕНВД для ИП, ООО?
Многие ИП и организации задаются вопросом: что выгоднее — вмененка или упрощенка? В этой статье мы рассмотрим плюсы и минусы УСН и ЕНВД.
Скидка 45% в ноябре: 7 590 р. вместо
Простое ведение бухгалтерии
Система сама рассчитает налоги и напомнит вам о сроках платежей и сдачи отчетов
Автоматический расчет зарплаты, отпускных и больничных
Техподдержка 24/7, подсказки внутри сервиса, справочно-правовая база
Отправка отчетности через интернет
Отчеты и КУДиР формируются автоматически по данным бухучета
Электронный документооборот и быстрая проверка контрагентов
Документы, сделки, аналитические отчеты, сверка по НДС
Вопрос о том, какая система выгоднее, с начала 2021 года отпадает сам собой. ЕНВД отменяют, поэтому организации смогут выбирать только между ОСНО и УСН. У предпринимателей выбор больше — ОСНО, УСН, патент и самозанятость. Выберите режим с минимальной налоговой нагрузкой с помощью нашего бесплатного калькулятора. Если вы собираетесь переходить с ЕНВД на другой налоговый режим, прочитайте нашу статью — мы собрали в ней ответы на самые популярные вопросы по системам налогообложения. Не нашли ответа на свой вопрос? Задайте его в комментариях, обязательно ответим.
Общие черты УСН и ЕНВД
Упрощенка — специальный налоговый режим, при котором организация или ИП ведут упрощенный учет и освобождаются от ряда налогов: на имущество и прибыль, НДС (кроме импорта) и НДФЛ (для ИП без сотрудников). УСН можно применять при особых условиях, о которых мы уже писали. На упрощенке необходимо выбрать объект налогообложения: “Доходы” или “Доходы минус расходы”, — о критериях выбора мы также рассказывали в статье.
ЕНВД — также является спецрежимом, который освобождает бизнес от ряда налогов и подходит для определенных видов деятельности. Их перечень дан в ст.
Сходство между двумя спецрежимами заключается в следующем:
- УСН или ЕНВД выбирается добровольно.
- Оба спецрежима можно применять при численности сотрудников менее ста и участии других организаций менее 25%.
- Оба режима освобождают от уплаты налога на прибыль, НДС, налога на имущество. Исключения для УСН перечислены в ст. 346.11 НК РФ, для ЕНВД — в ст. 346.26 НК РФ.
- ИП без сотрудников не платят НДФЛ (кроме дивидендов, выигрышей и некоторых других доходов).
- Организации и ИП с работниками платят НДФЛ с зарплаты сотрудникам, страховые взносы, налог на транспорт, воду и землю, пошлины и акцизы — уплата и отчетность по ним происходит в общем порядке.
- Авансовые платежи по УСН и уплата налога по ЕНВД производится ежеквартально, в течение 25 дней после завершения квартала.
- Бухотчетность сдается в упрощенном виде.
- При ЕНВД и УСН “Доходы” можно сделать налоговый вычет на сумму уплаченных страховых взносов за сотрудников, уменьшив налог до 50%. (При УСН “Доходы минус расходы” уплаченные взносы попадают в расходы и тоже уменьшают налоговую базу).
- Если предприятие выходит за пределы критериев, которые назначены для спецрежима, оно переходит на ОСНО с начала того квартала, в котором возникло нарушение.
Отличия между УСН и ЕНВД
| УСН | ЕНВД |
|---|---|
При УСН налог зависит от величины доходов или от разницы между доходами и расходами. Регионы имеют право снижать налоговую ставку. Налог на УСН “Доходы” платится только в том случае, если у предприятия были доходы. Налог на УСН “Доходы минус расходы” уплачивается всегда, даже при убытке, и тогда он составляет 1% от выручки предприятия. Налог на УСН “Доходы минус расходы” уплачивается всегда, даже при убытке, и тогда он составляет 1% от выручки предприятия. |
При ЕНВД налог уплачивается в любом случае, вне зависимости от прибыльности предприятия, и является фиксированной величиной. Налоговая ставка составляет 15%, а база для исчисления налога зависит от вмененной доходности вида деятельности и коэффициентов, которые устанавливают федеральные и муниципальные органы власти. Поэтому налог на ЕНВД нужно платить, даже если предприятие работало в убыток. |
| На упрощенке использовать контрольно-кассовую технику придется в большинстве случаев. | На вмененке при продаже товаров и оказании услуг населению чаще всего достаточно выдать товарный чек или бланк строгой отчетности. Уточняйте требования для вашего вида деятельности. |
| При УСН налоговым периодом является календарный год, декларация сдается раз в год до 31 марта (организации) или до 30 апреля (ИП). Но авансовые платежи по налогу делаются раз в квартал в течение 25 дней после завершения квартала. | При ЕНВД налоговый период — квартал, налог уплачивается в течение 25 дней, а декларация подается в течение 20 дней после завершения отчетного квартала. |
| УСН можно начать применять с начала календарного года. | Применять ЕНВД или отказаться от него можно в любом месяце. |
Когда выгоднее применять УСН или ЕНВД?
Применять ЕНВД выгодно, когда бизнес приносит гораздо больший доход, чем установленный вмененный доход по данному виду деятельности. Тогда предприятие будет платить меньший налог, чем оно уплатило бы на УСН.
Если же бизнес приносит доход приблизительно равный или меньший, чем вмененный доход, то выгоднее применять УСН. Важно только разобраться, какой объект налогообложения лучше подойдет вашему предприятию. Мы уже писали, какой вид УСН стоит выбрать в зависимости от условий работы компании.
Но, конечно, выгоду применения УСН или ЕНВД нужно внимательно оценивать и просчитывать на основе реальных показателей деятельности предприятия, с учетом всех условий, в которых она ведется: наличие сотрудников, налоговая ставка в регионе и т. д. Если бизнес ведет несколько направлений деятельности, то по одним направлениям он может применять УСН, а по другим ЕНВД.
Онлайн-сервис Контур.Бухгалтерия поможет вам легко рассчитать все налоги. Если вы не можете определиться самостоятельно, то доверьте учет профессиональному бухгалтеру
Найти бухгалтера
Вам будут интересны статьи по теме «ЕНВД»ЕНВД: что делать и какую систему налогообложения выбрать
Единый налог на вменённый доход – это льготная система налогообложения для налогоплательщиков, которые осуществляют определенные виды деятельности. До её отмены осталось чуть больше месяца – она действует в России до конца 2020 года. С 1 января 2021 года вменёнка официально прекратит своё существование.
ЕНВД могли использовать (и пока что продолжают использовать) организации и ИП, которые занимаются видами деятельности из п. 3 ст. 346.29 НК РФ. Это оказание различных услуг и розничная торговля. Удобство ЕНВД – в том, что сумма налога фиксирована, она не зависит от выручки.
ЕНВД уплачивается на основании показателей, установленных в зависимости от вида деятельности: при торговле это площадь торговой точки, при оказании услуг — численность сотрудников.
Причина отмены ЕНВД
Отмена ЕНВД планировалась давно, с 2018 года. В 2020 году часть налогоплательщиков уже потеряла право применять ЕНВД из-за введения маркировки товаров (изделий из меха, обуви и лекарств). Окончательное решение об отмене вменённого налога было принято государством в связи развитием кассовой реформы, прошедшей уже несколько этапов в России. Благодаря онлайн-ККТ, контролировать выручку малого бизнеса стало гораздо проще.
Кого коснётся отмена ЕНВД
С 1 января 2021 года право применять ЕНВД утратят абсолютно все российские налогоплательщики на этом режиме – вне зависимости от региона и сферы деятельности. Утрата права применения касается всех: как организаций, так и индивидуальных предпринимателей.
Что нужно сделать до 2021 года
Заявление о прекращении применения ЕНВД подавать никуда не нужно. Самое главное, что сначала необходимо сделать – это определиться с системой налогообложения, выбрав один из спецрежимов (УСН/ПСН/НПД для самозанятых) или ОСН. Далее действия налогоплательщика зависят от выбранного режима.
При выборе УСН до 31 декабря 2020 года нужно подать уведомление по специальной форме о переходе на другой режим в налоговый орган – по месту нахождения организации / по месту жительства ИП.
При выборе ПСН нужно отправить заявление по установленной форме на получение патента – не позднее, чем за 10 дней до начала применения ПСН, но не позднее 17 декабря 2020 года. Это заявление можно подать в любой территориальный налоговый орган.
Отправить уведомление или заявление можно четырьмя способами:
— Путём личного визита в налоговый орган;
— Через личный кабинет налогоплательщика;
— По телекоммуникационным каналам связи – через оператора ЭДО;
— Почтовым отправлением с описью вложения.
При выборе НПД для самозанятых налогоплательщик должен зарегистрироваться в мобильном приложении или веб-кабинете «Мой налог».
При выборе общей системы налогообложения (ОСН) ничего подавать не нужно. Налогоплательщики на ЕНВД, не выбравшие до 31 декабря иной режим налогообложения, и не отправившие уведомление или заявление о переходе на него, автоматически будут переведены на ОСН. А это означает, что придётся платить налог на прибыль (организации) или НДФЛ (ИП), НДС и, при необходимости, другие региональные налоги.
Поэтому рекомендуем ответственно подойти к выбору режима и успеть подать заявление заблаговременно. Чтобы помочь представителям бизнеса определиться, эксперты оператора ЭДО Такском подготовили сравнительные таблицы по всем режимам, на которые можно перейти плательщикам ЕНВД.
Налоговые режимы для ИП
У ИП больше вариантов режимов налогообложения, на которые они могут перейти, чем у организаций. Это ОСН и четыре спецрежима. Рассмотрим их особенности.
Налоговые режимы для организаций
У организаций вариантов перехода остаётся всего три: 2 спецрежима и ОСН. ПСН и НПД организации не могут использовать в принципе.
Итак, как видно из сравнительных таблиц, вариантов для перехода остаётся не так много. При выборе нового режима налогообложения стоит отталкиваться, в первую очередь, от ограничений – проходит ли ИП/организация по ним для применения режима. Из оставшихся вариантов уже можно выбирать по ставке налога и объёму сдаваемой отчётности.
Кстати, сама ФНС также разработала сервис для помощи налогоплательщикам с выбором налогового режима.
Отправка заявления о переходе на другой режим в электронном виде
В решениях компании Такском уже реализована возможность отправки уведомлений (заявлений) о переходе на другой режим НО. Организации и ИП, которые сдают отчётность через сервисы Такском, могут направить такие уведомления (заявления) по установленной форме, подписав электронной подписью. Подтвердить свой выбор новой системы НО электронно – самый надёжный способ. Передача документа в ФНС произойдёт мгновенно, при этом документ не потеряется.
Для тех, кто пока только определяется с оператором по сдаче отчётности, Такском предлагает удобные сервисы и выгодные тарифы. Для сдачи отчётности у компании Такском есть три варианта решений.
Первый – это веб-кабинет «Онлайн-Спринтер», который работает через браузер. Для сдачи отчётности нужен лишь компьютер и доступ в интернет. Сервис обладает интуитивно-понятным интерфейсом и не требует установки дополнительного ПО на ПК. Данные и документы хранятся в защищённом облачном архиве оператора.
Второй вариант для сдачи отчётности – это ПО «Доклайнер», устанавливаемое на ПК пользователя. В этом случае документы хранятся на компьютере пользователя.
В обоих продуктах предусмотрен многопользовательский режим для одновременной работы нескольких сотрудников с возможностью ограничения прав пользования.
Ну и, для тех, кто привык к работе в учётной системе 1С и не планирует устанавливать дополнительных программ, Такском предлагает сдавать отчётность из самой 1С. «1С:Электронная отчётность» работает из большинства конфигураций семейства «1С:Предприятие» версий 8.2 и выше.
Во всех сервисах Такском есть все актуальные формы отчётов для сдачи отчётности на любых режимах налогообложения.
При переходе с ЕНВД на любой другой режим необходимо перенастроить кассовые аппараты, чтобы в кассовых чеках отображался новый налоговый режим. Сделать это необходимо до начала использования кассы в 2021 году. Перерегистрировать кассу в ИФНС не нужно.
Если вы используете фискальные накопители (ФН) со сроком 36 месяцев, то в некоторых случаях вам может понадобиться замена ФН и перерегистрация кассы.
Нужна помощь в перенастройке касс или консультация по фискальным накопителям? Обращайтесь в Центр технического обслуживания компании Такском:
— в Москве и МО: 8 (495) 730-73-43;
— в регионах (звонок бесплатный): 8 (800) 250-11-54
С действующими акциями вы можете познакомиться на нашем сайте.
Отправить
Запинить
Твитнуть
Поделиться
Поделиться
После отмены ЕНВД заявление о снятии с учета с вмененки подавать не придется
Добрый день, уважаемые ИП!
Давно уже говорят и пишут, что ЕНВД отменят с 1 января 2021 года. Я тоже писал про это ожидаемое событие на своем блоге.
Да, есть два законопроекта, которые предлагают продлить действие ЕНВД еще на три года, но шанс, что их одобрят — очень мал.
Вот еще одно подтверждение того, что ЕНВД отменят
ФНС опубликовала письмо от 21.08.20 № СД-4-3/13544@, в котором сообщает, что будет автоматически снимать с учета в качестве плательщиков ЕНВД в 2021 году.
Никаких заявлений писать не нужно. Если ЕНВД отменяют, то и заявления об отказе от применения ЕНВД в 2021 году подавать не придется.
Подчеркну, что ФНС будет снимать с ЕНВД автоматически только в 2021 году, после отмены ЕНВД.
Если в 2020 году хотите отказаться от ЕНВД, то заявление подавать нужно.
Что делать?
От себя добавлю, что нужно заранее побеспокоиться о переходе на другую систему налогов.
Посмотрите в сторону УСН, ПСН или НПД. Если ничего не делать, нет совмещения с другой системой налогообложения, то автоматом перейдете на ОСН (общая система налогообложения). ОСН система сложная, запутанная и мало каким ИП подходит.
Поэтому, заранее изучайте на какую систему налогов будете мигрировать с 2021 года.
Например, если захотите мигрировать на УСН, то заявление о переходе на УСН придется подавать до 31 декабря 2020 года.
То есть, вопросы с переходом на другую систему налогов с ЕНВД нужно решать уже ближе к декабрю 2020-го года.
P.S. Сейчас время такое, что постоянно все меняется. Есть мизерный шанс, что продлят действие ЕНВД (законопроекты регулярно вносятся). Лично я думаю, что отменят ЕНВД.
Но если что-то изменится в этом вопросе — обязательно напишу.
Следите за обновлениями блога: https://dmitry-robionek.ru/subscribe
Уважаемые предприниматели!
Готова новая электронная книга по налогам и страховым взносам для ИП на УСН 6% без сотрудников на 2021 год:
«Какие налоги и страховые взносы платит ИП на УСН 6% без сотрудников в 2021 году?»
В книге рассмотрены:
- Вопросы о том, как, сколько и когда платить налогов и страховых взносов в 2021 году?
- Примеры по расчетам налогов и страховых взносов «за себя»
- Приведен календарь платежей по налогам и страховым взносам
- Частые ошибки и ответы на множество других вопросов!
Советую прочитать:
- Похоже, взносы ИП «за себя» на 2021 год не будут повышать. И обновили взносы на 2022 и 2023 год
- Сплошное статистическое наблюдение в 2021 году: готовимся все! Что это такое и что делать?
- Каких ИП ФНС сможет принудительно «закрывать», начиная с 1 сентября 2020 года?
Я создал этот сайт для всех, кто хочет открыть свое дело в качестве ИП, но не знает с чего начать. И постараюсь рассказать о сложных вещах максимально простым и понятным языком.
ЕНВД в 2020-2021 году для ИП. Изменения и отмена — Финансы на vc.ru
{«id»:91901,»url»:»https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena»,»title»:»\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena&title=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena&text=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena&text=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430&body=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
\u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena&text=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena&text=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u0415\u041d\u0412\u0414 \u0432 2020-2021 \u0433\u043e\u0434\u0443 \u0434\u043b\u044f \u0418\u041f. \u0418\u0437\u043c\u0435\u043d\u0435\u043d\u0438\u044f \u0438 \u043e\u0442\u043c\u0435\u043d\u0430&body=https:\/\/vc.ru\/finance\/91901-envd-v-2020-2021-godu-dlya-ip-izmeneniya-i-otmena»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
4078 просмотров
Отмена ЕНВД в 2021 году — статья
Отмена ЕНВД в 2021 году – как подготовиться
Единый налог на вмененный доход будет упразднен 1 января 2021 года. Обсуждения отмены ЕНВД продолжались несколько лет, но теперь все решено. Со следующего года «вмененки» больше не будет. До конца 2020 индивидуальные предприниматели и организации, которые применяли ЕНВД, должны определиться, на какую схему налогообложения перейти со следующего года.
Обсуждения отмены ЕНВД продолжались несколько лет, но теперь все решено. Со следующего года «вмененки» больше не будет. До конца 2020 индивидуальные предприниматели и организации, которые применяли ЕНВД, должны определиться, на какую схему налогообложения перейти со следующего года.
Варианты перехода с ЕНВД
Доступные вам варианты зависят от вашего статуса. Если вы ИП, вам нужно выбрать что-то из этих пяти опций:
-
Самозанятость
-
ПСН (патентная система)
-
УСН («упрощенка») с объектом «доходы»
-
УСН с объектом «доходы минус расходы»
-
ОСН (общая система налогообложения)
Общая система налогообложения ждет всех ИП, которые не успеют выбрать режим до конца года. Советуем вам не затягивать с решением, потому что ОСН — самый неудобный для ИП вариант. Нагляднее пути перехода с «вмененки» для ИП представлены на схеме:
Если вы юрлицо, у вас два пути: «упрощенка» или ОСН (много налогов и отчетности).
У сельхозпроизводителей, у которых доля доходов от сельхоздеятельности больше 70 % в общем объеме, есть дополнительная опция — единый сельскохозяйственный налог (ЕСХН).
Как выбрать режим налогообложения вместо «вмененки»
Универсального ответа для всех никто не даст. Чтобы принять верное для вас решение, нужно посчитать доходы и расходы, взвесить плюсы и минусы подачи отчетности по каждому режиму налогообложения, учесть количество сотрудников и ограничения по видам деятельности.
Вид деятельности практически не влияет на переход с ЕНВД. Он имеет значение, если вы ИП и работаете в сфере общепита или розничной торговли. Собираясь переходить на ПНС, обратите внимание на то, что площадь занимаемого вашим бизнесом помещения не должна быть больше 50 квадратных метров. В ЕНВД допускалась площадь до 150 квадратных метров. Поэтому если ваш магазин или заведение занимает больше 50 метров, пожалуй, единственный удобный вариант для вас после отмены ЕНВД в 2021 году – «упрощенка».
В ЕНВД допускалась площадь до 150 квадратных метров. Поэтому если ваш магазин или заведение занимает больше 50 метров, пожалуй, единственный удобный вариант для вас после отмены ЕНВД в 2021 году – «упрощенка».
Изменения в отчетности после ЕНВД
Единый налог на вмененный доход предполагал сдачу одной декларации в квартал. Для ИП даже не нужна была книга учета доходов и расходов. После отмены «вмененки» с отчетностью будет посложнее. Частота и объем зависят от выбранного режима:
-
Самозанятые освобождены от налогового учета и отчетности.
-
Индивидуальные предприниматели на патентной системе должны вести книгу учета доходов и по запросу налоговой предоставлять ее. Декларации подавать не требуется.
-
«Упрощенка» для ИП и организаций требует ведения учета в разных форматах, а по итогам года все должны предоставить декларацию.
-
Общая система налогообложения – самая сложная, она предполагает регулярный учет и периодическую сдачу отчетности.
Сколько налогов придется платить
ОСН с НДС 20 % и налогом на прибыль 20 % для юрлиц и 13 % для ИП самый затратный для всех. Базовая ставка в УСН составляет 6 %, если платите налог с доходов, и 15%, если с разницы между доходами и расходами. В некоторых регионах ставки могут быть пониже. Уточните этот вопрос в налоговом органе вашего региона.
Выбравшие патентную систему платят 6 % от суммы возможного дохода за год. В каждом регионе эта сумма отличается, потому что региональные власти определяют ее самостоятельно по каждому виду деятельности. Самозанятые на патенте платят 4 % от полученного дохода при расчетах с физическими лицами, 6% при расчете с организациями.
Смена режима налогообложения после отмены ЕНВД в 2021 году
На общую систему перейти проще всего, потому что на него вас переведут по умолчанию, если вы не выберите другой режим до конца 2020 года. Совмещавщие ЕНВД с «упрощенку» тоже могут никаких действий не предпринимать, если хотят остаться на УСН. Остальным советуем поторопиться и принять решение о переходе максимум до середины декабря.
Совмещавщие ЕНВД с «упрощенку» тоже могут никаких действий не предпринимать, если хотят остаться на УСН. Остальным советуем поторопиться и принять решение о переходе максимум до середины декабря.
Сроки подачи уведомлений о переходе на другой режим налогообложения:
-
ПСН – до 17 декабря 2020 года
Заявление по форме № 26.5-1 либо по форме, которую рекомендует ФНС России в приложении к письму от 18.02.2020 № СД-4-3/2815@ -
УСН – до 31 декабря 2020 года
Уведомление по форме № 26.2-1. Нужно указать объект налогообложения («доходы» или «доходы минус расходы») и код налогоплательщика «2» -
Самозанятые – в любое время
Нужно зарегистрироваться специальном сайте ФНС России для самозанятых граждан. -
ЕСХН – до 31 декабря 2020 года
Уведомление по форме № 26.1-1
Отчетность по ЕНВД за 2020 год
После перехода с ЕНВД, независимо от выбранного вами режима, в налоговую нужно подать декларацию за 4 квартал 2020 года. Сделать это необходимо не позднее 20 января 2021 года, иначе вас ждут штрафы.
Вы можете заказать подготовку и отправку заявления о смене налогообложения в ФНС у нас на сайте
Единый налог на вмененный доход (ЕНВД)
ЕНВД – это единый налог на вмененный доход, который уплачивается при осуществлении определенных видов деятельности. При этом базой для расчетов по этому налогу являются различные физические показатели, устанавливаемые по каждому из видов деятельности, отнесенных к вмененке.
Федеральным законодательством устанавливается общий перечень видов деятельности, при которых есть возможность переходить на налог ЕНВД в соответствии со 2 пунктом 346.26 статьи НК. Также наряду с ним существует и список видов деятельности, при которых невозможно применение ЕНВД.
У региональных властей есть возможность вносить коррективы в список разрешенных для ЕНВД видов деятельности, но только в сторону сокращения их. Также предоставлено этим органам право применять коэффициенты к установленным ставкам.
Плательщики налога ЕНВДПлательщиками ЕНВД могут являться ЮЛ и ИП, которые соответствуют определенному перечню критериев, а также осуществляют экономическую деятельность, коды которой поименованы во 2 пунктом 346.26 статьи НК.
Что касается критериев, необходимых для применения ЕНВД, то они следующие:
- Среднесписочная численность сотрудников, которые находятся в штате ЮЛ или ИП не должна превышать 100 человек, согласно показателям года, предшествующего переходу на ЕНВД;
- Что касается ЮЛ, то доля входящих в состав участников этого общества других ЮЛ не должна превышать 25%;
- Желающие перейти на ЕНВД не должны входить в список крупнейших налогоплательщиков;
- Организация или ИП, пожелавшие перейти на ЕНВД не могут применять патентную систему налогообложения;
- Если вы хотите применять ЕНВД, то нельзя быть плательщиком СХ/налога или находиться в составе простого товарищества;
- Те лица, которые передали в аренду свои автогазозаправочные или автозаправочные станции также не вправе стать плательщиками налога ЕНВД.
Налоговая о налоге ЕНВД в 2013 году
В настоящий момент такая система, как ЕНВД, является обязательной для всех индивидуальных предпринимателей и юридических лиц, которые подпадают под указанные критерии и осуществляют закрепленные законодательством виды деятельности. Но уже с 2013 года ситуация изменится и такой налог, как ЕНВД, из обязательного превратиться в добровольный.
До конца же 2012 года для того, чтобы прекратить применять налог ЕНВД надо либо перестать осуществлять виды деятельности, которые подлежат этой системе, либо не соответствовать хотя бы одному из поименованных критериев. Налоговая инспекция сообщает, что желающим сменить статус плательщика ЕНВД на какой-либо другой, осталось подождать совсем немного.
Если Вы заметили на сайте опечатку или неточность, выделите её |
Что это такое ЕНВД простыми словами
Подбирая для работы режим налогообложения, многие ИП, а также организации выбирают для себя ЕНВД, что неудивительно, ведь данный режим очень прост как в учете, так и в проведении расчетов и формировании отчетности. С ним может справиться любой предприниматель, даже без помощи бухгалтера. Ведь никаких особых требований данная система не предъявляет к объекту предпринимательской деятельности.
Общие сведения
Общее ознакомление с этой системой налогообложения стоит начать с расшифровки ЕНВД – единый налог на вмененный доход. На практике, действительно оказывается, что для мелкого предпринимательства данный налог действительно оказывается единым. Иногда бывают исключения из правил, но общий смысл остается тот же. ЕНВД может освободить объект предпринимательства от таких налогов:
- Прибыльный налог
- НДФЛ
- НДС
- Имущественный налог и др.
Эта система налогообложения также удобна тем, что не обязывает предпринимателя вести учет всех расходов и доходов. Для него достаточно проводить учет физических показателей.
ЕНВД для ИП удобен также тем, что составлять по нему отчетность очень просто. Ведь налоговым периодом является квартал, а значит, большого накопления данных не происходит. Оплата по налогу также квартальная. То есть то, что предприниматель рассчитал для оплаты до 20 числа первого месяца следующего квартала, то он до 25 числа этого же месяца обязан уплатить в казну.
ЕНВД – это налог, какой определяется предпринимателем на основании установленных законодательством условных показателей, а значит реальный доход, который предприниматель получает, на сумму налога не влияет.
Кто имеет право уплачивать
Платить налоги по данной системе имеют право далеко не все организации и предприниматели, а только те, что осуществляют деятельность, подходящую под требования данной системы в законном порядке. К числу таких в статье №346 относятся:
- Предоставление услуг ремонта и технического обслуживания транспортной техники
- Осуществление перевозок пассажиров и грузов
- Предоставление услуг частными медиками, а также ветеринарные услуги
- Предоставление площади, пригодной для жилья в аренду
- Работа автостоянок
- Разные виды розничной торговли: как с торговым залом, так и без него и др.
Подробный перечень деятельности, которая подпадает под налог ЕНВД, можно найти в вышеуказанной статье. Там же есть и ограничения, которые по нему действуют. Например, этим налогом не может облагаться розничная торговля с размером торгового зала, больше 30 квадратов.
Также, система налогообложения ЕНВД требует предварительной постановки плательщика на учет конкретно по этому налогу. Данный процесс осуществляется путем подачи заявления в налоговый орган в специальной форме, которая разная для ООО и ИП. Процедура его рассмотрения заканчивается тем, что местный налоговый орган выдает Уведомление о постановке на учет ИП или ООО, как плательщика ЕНВД.
Смотрите самое полное видео о ЕНВД:
Как понять ЕНВД
Как объяснить, что такое ЕНВД для ИП простыми словами. Это та система налогообложения, при которой отображать количество реального дохода не надо. В ее рамках, для исчисления налога используются условные величины, чтобы определить доход с конкретного физического показателя. Они рассчитаны и предъявлены законодательными органами и носят постоянный характер.
Чтобы лучше понимать, стоит рассмотреть формулу ЕНВД, а она такова:
Базовая доходность*физический показатель*К1*К2*15%
Базовая доходность является ярким примером того самого вмененного дохода – это та сумма, которую государство ожидает, что вы получите, совершая свою предпринимательскую деятельность. Именно базовая доходность заранее принята властями, для определения примерной суммы налога и она же оказывает основное влияние на него.
Именно базовая доходность заранее принята властями, для определения примерной суммы налога и она же оказывает основное влияние на него.
Дополнительное влияние оказывает физический показатель, который является ярким отображением размеров вашего бизнеса. Ведь чем он больше – тем больше будет физический показатель, а значит ваш предполагаемый доход и соответственно, размер налога к уплате.
Отдельно надо поговорить о коэффициентах-дефляторах ЕНВД, что это такое простыми словами.
А простыми словами, это та корректировка, которую вносит государство, чтобы увеличить вашу налоговую базу, а следом – размер уплачиваемого налога. Как говорит это же государство, коэффициент – это поправка, для более точного определения базы, с учетом местонахождения бизнеса, ассортимента, проходимости и всего прочего. В общем, по мнению государства, этот коэффициент поможет приблизиться к реальным доходам предпринимателя.
Второй же коэффициент К2, часто на местном уровне установлен за 1 и поэтому существенного влияния на сумму исчисляемого налога не оказывает, а иногда призван даже ее уменьшить.
Итак, специальный режим налогообложения ЕНВД – помогает предпринимателям снизить свое налоговое бремя, дать свободу развития, а также получать большую прибыль от хозяйствования. Отчетность по нему проста и понятна. С нею может справиться даже сам ИП, не прибегая к помощи бухгалтера. Налоговый период ЕНВД- квартал. Именно по его истечении предприниматель подает отчетность в налоговую службу по месту регистрации, а также оплачивает рассчитанный им же размер налога. Данная система доступна не для всех видов деятельности, а окончательный ее перечень устанавливается на местном уровне с целью урегулирования соотношения предложений на региональном рынке.
Рубрикатор статей
Множественное вменение недостающих данных в эпидемиологических и клинических исследованиях: потенциал и подводные камни
- Джонатан AC Стерн, профессор медицинской статистики и эпидемиологии1,
- Ян Р.
 Уайт, старший научный сотрудник2,
Уайт, старший научный сотрудник2, - Джон Б. Карлин, директор клинической эпидемиологии и биостатистики unit3,
- Майкл Спратт, научный сотрудник1,
- Патрик Ройстон, старший научный сотрудник 4,
- Майкл Дж. Кенвард, профессор биостатистики5,
- Анджела М. Вуд, преподаватель биостатистики6,
- Джеймс Р. Карпентер, читатель по медицинским и социальным вопросам статистика5
- 1 Департамент социальной медицины Бристольского университета, Бристоль BS8 2PR
- 2 MRC Отдел биостатистики, Институт общественного здравоохранения, Кембридж CB2 0SR
- 3 Клиническая эпидемиология и Отдел биостатистики Детского научно-исследовательского института Мердока и Университета y of Melbourne, Parkville, Victoria 3052, Australia
- 4 Группы по раку и статистической методологии, Отдел клинических испытаний MRC, Лондон NW1 2DA
- 5 Отдел медицинской статистики, Лондонская школа гигиены и тропической медицины Лондон , WC1E 7HT
- 6 Департамент общественного здравоохранения и первичной медико-санитарной помощи, Институт общественного здравоохранения, Кембридж
- Для корреспонденции: JAC Sterne jonathan.sterne {at} bristol.ac.uk
В большинстве исследований отсутствуют некоторые данные. Джонатан Стерн и его коллеги описывают надлежащее использование и отчетность метода множественного вменения для работы с ними
Отсутствующие данные неизбежны в эпидемиологических и клинических исследованиях, но их способность подорвать достоверность результатов исследований часто упускается из виду в медицинской литературе. .1 Это отчасти объясняется тем, что статистические методы, которые могут решать проблемы, возникающие из-за отсутствия данных, до недавнего времени были недоступны для медицинских исследователей. Однако множественное вменение — относительно гибкий универсальный подход к работе с отсутствующими данными — теперь доступен в стандартном статистическом программном обеспечении 2 3 4 5, что позволяет обрабатывать отсутствующие данные в полурегулярном режиме. Все чаще сообщается о результатах, основанных на этом методе, требующем больших вычислительных ресурсов, но его необходимо применять осторожно, чтобы избежать ошибочных выводов.
Однако множественное вменение — относительно гибкий универсальный подход к работе с отсутствующими данными — теперь доступен в стандартном статистическом программном обеспечении 2 3 4 5, что позволяет обрабатывать отсутствующие данные в полурегулярном режиме. Все чаще сообщается о результатах, основанных на этом методе, требующем больших вычислительных ресурсов, но его необходимо применять осторожно, чтобы избежать ошибочных выводов.
В этой статье мы рассмотрим причины, по которым отсутствие данных может привести к смещению и потере информации в эпидемиологических и клинических исследованиях.Мы обсуждаем обстоятельства, при которых множественное вменение может помочь за счет уменьшения систематической ошибки или повышения точности, а также описываем возможные подводные камни при его применении. Наконец, мы описываем недавнее использование и составление отчетов об анализах с использованием множественного вменения в общих медицинских журналах и предлагаем руководящие принципы проведения таких анализов и составления отчетов о них.
Последствия отсутствия данных
Исследователи обычно устраняют недостающие данные, включая в анализ только полные случаи — тех людей, у которых нет недостающих данных ни по одной из переменных, необходимых для этого анализа.Однако результаты такого анализа могут быть необъективными. Кроме того, кумулятивный эффект отсутствия данных по нескольким переменным часто приводит к исключению значительной части исходной выборки, что, в свою очередь, приводит к значительной потере точности и мощности.
Риск смещения из-за отсутствия данных зависит от причин, по которым данные отсутствуют. Причины отсутствия данных обычно классифицируются как: полное отсутствие случайных данных (MCAR), отсутствие случайных данных (MAR) и отсутствие случайных данных (MNAR) (вставка 1).6 Эта номенклатура широко используется, хотя фразы мало что говорят об их техническом значении и практическом значении, которое может быть незаметным. Когда существует вероятность того, что данные отсутствуют случайно, но не полностью случайным образом, анализ, основанный на полных случаях, может быть необъективным. Такие предубеждения можно преодолеть с помощью таких методов, как множественное вменение, которые позволяют включать в анализ лиц с неполными данными. К сожалению, с помощью наблюдаемых данных невозможно отличить случайное отсутствие от случайного отсутствия.Следовательно, смещения, вызванные отсутствием данных не случайно, могут быть устранены только путем анализа чувствительности, исследующего влияние различных предположений о механизме пропуска данных.
Такие предубеждения можно преодолеть с помощью таких методов, как множественное вменение, которые позволяют включать в анализ лиц с неполными данными. К сожалению, с помощью наблюдаемых данных невозможно отличить случайное отсутствие от случайного отсутствия.Следовательно, смещения, вызванные отсутствием данных не случайно, могут быть устранены только путем анализа чувствительности, исследующего влияние различных предположений о механизме пропуска данных.
Блок 1 Типы отсутствующих данных *
Полностью отсутствуют случайно —Систематических различий между отсутствующими значениями и наблюдаемыми значениями нет. Например, измерения артериального давления могут отсутствовать из-за поломки автоматического сфигмоманометра.
Отсутствует случайно — Любая систематическая разница между отсутствующими значениями и наблюдаемыми значениями может быть объяснена различиями в наблюдаемых данных.Например, пропущенные измерения артериального давления могут быть ниже, чем измеренные артериальное давление, но только потому, что у молодых людей может быть больше шансов пропустить измерения артериального давления
Отсутствуют не случайно — Даже после того, как наблюдаемые данные приняты во внимание, сохраняются систематические различия между недостающими значениями и наблюдаемыми значениями. Например, люди с высоким кровяным давлением с большей вероятностью пропускают прием в клинику из-за головной боли
Статистические методы обработки недостающих данных
Для работы с недостающими данными обычно используются различные специальные подходы.К ним относятся замена отсутствующих значений значениями, рассчитанными на основе наблюдаемых данных (например, среднее значение наблюдаемых значений), использование индикатора отсутствующей категории 7 и замена отсутствующих значений последним измеренным значением (последнее значение, перенесенное на будущее) 8. эти подходы в целом статистически достоверны и могут привести к серьезной систематической ошибке. Единичное вменение пропущенных значений обычно приводит к слишком малым стандартным ошибкам, поскольку не учитывает тот факт, что мы не уверены в пропущенных значениях.
Единичное вменение пропущенных значений обычно приводит к слишком малым стандартным ошибкам, поскольку не учитывает тот факт, что мы не уверены в пропущенных значениях.
Когда в рандомизированном контролируемом исследовании отсутствуют данные о результатах, общий анализ чувствительности заключается в изучении «наилучшего» и «наихудшего» сценариев путем замены отсутствующих значений на «хорошие» результаты в одной группе и «плохие» результаты в другой. группа. Это может быть полезно, если имеется только несколько пропущенных значений бинарного результата, но поскольку вменение всех пропущенных значений как хороших или плохих является сильным предположением, анализ чувствительности может дать очень широкий диапазон оценок эффекта вмешательства, даже если есть только умеренное количество пропущенных результатов.Когда результаты являются количественными (числовыми), такой анализ чувствительности невозможен, потому что нет очевидных хороших или плохих результатов.
Существуют обстоятельства, при которых анализ полных случаев не приводит к систематической ошибке. Когда недостающие данные встречаются только в переменной результата, которая измеряется один раз для каждого человека, такой анализ не будет предвзятым, при условии, что все переменные, связанные с отсутствующим результатом, могут быть включены в качестве ковариат (при предположении о случайном отсутствии результата).Отсутствующие данные в переменных-предикторах также не вызывают смещения при анализе полных наблюдений, если причины отсутствия данных не связаны с результатом.9 10 В этих обстоятельствах специальные методы устранения недостающих данных могут уменьшить потерю точности и мощности в результате исключение лиц с неполными предикторами, которые не требуются во избежание систематической ошибки.
Если мы предположим, что данные отсутствуют случайно (вставка 1), то беспристрастный и статистически более эффективный анализ (по сравнению с анализом, основанным на полных случаях), как правило, может быть выполнен путем включения лиц с неполными данными. Иногда это возможно путем построения более общей модели, включающей информацию о частично наблюдаемых переменных — например, с использованием моделей случайных эффектов для включения информации о частично наблюдаемых переменных из промежуточных временных точек11 12 или путем использования байесовских методов для включения частично наблюдаемых переменных в полную статистическую информацию. Модель, на основе которой может быть получен интересующий анализ.13 Другие подходы включают взвешивание анализа для учета недостающих данных, 14 15 и оценку максимального правдоподобия, которая одновременно моделирует причины отсутствующих данных и ассоциации, представляющие интерес в содержательном анализе.13 Здесь мы сосредоточимся на множественном вменении, которое является популярной альтернативой этим подходам.
Иногда это возможно путем построения более общей модели, включающей информацию о частично наблюдаемых переменных — например, с использованием моделей случайных эффектов для включения информации о частично наблюдаемых переменных из промежуточных временных точек11 12 или путем использования байесовских методов для включения частично наблюдаемых переменных в полную статистическую информацию. Модель, на основе которой может быть получен интересующий анализ.13 Другие подходы включают взвешивание анализа для учета недостающих данных, 14 15 и оценку максимального правдоподобия, которая одновременно моделирует причины отсутствующих данных и ассоциации, представляющие интерес в содержательном анализе.13 Здесь мы сосредоточимся на множественном вменении, которое является популярной альтернативой этим подходам.
Что такое множественное вменение?
Множественное вменение — это общий подход к проблеме пропущенных данных, который доступен в нескольких обычно используемых статистических пакетах. Он направлен на то, чтобы учесть неопределенность в отношении недостающих данных путем создания нескольких различных наборов правдоподобных условно исчисленных данных и надлежащего объединения результатов, полученных на основе каждого из них.
Первым этапом является создание нескольких копий набора данных с заменой отсутствующих значений на вмененные значения.Они выбираются из их прогнозного распределения на основе наблюдаемых данных — таким образом, множественное вменение основано на байесовском подходе. Процедура вменения должна полностью учитывать всю неопределенность при прогнозировании пропущенных значений путем введения соответствующей изменчивости в множественные вмененные значения; мы никогда не сможем узнать истинные значения недостающих данных.
На втором этапе используются стандартные статистические методы для подгонки интересующей модели к каждому из вмененных наборов данных. Оценочные связи в каждом из вмененных наборов данных будут отличаться из-за вариации, вносимой в вменение пропущенных значений, и они полезны только при усреднении вместе, чтобы дать общие оценочные связи. Стандартные ошибки рассчитываются с использованием правил Рубина 16, которые учитывают различия в результатах между вмененными наборами данных, отражая неопределенность, связанную с отсутствующими значениями. Правильные выводы получены, потому что мы усредняем распределение недостающих данных с учетом наблюдаемых данных.
Стандартные ошибки рассчитываются с использованием правил Рубина 16, которые учитывают различия в результатах между вмененными наборами данных, отражая неопределенность, связанную с отсутствующими значениями. Правильные выводы получены, потому что мы усредняем распределение недостающих данных с учетом наблюдаемых данных.
Рассмотрим, например, исследование, изучающее связь систолического артериального давления с риском последующей ишемической болезни сердца, в котором у некоторых людей отсутствуют данные о систолическом артериальном давлении.Вероятность отсутствия систолического артериального давления может снижаться с возрастом (врачи чаще измеряют его у пожилых людей), увеличением индекса массы тела и курением в анамнезе (врачи чаще измеряют его у людей с риском сердечных заболеваний. факторы или сопутствующие заболевания). Если мы предположим, что данные отсутствуют случайным образом и что у нас есть данные систолического артериального давления для репрезентативной выборки лиц в разных группах по возрасту, курению, индексу массы тела и ишемической болезни сердца, то мы можем использовать множественное вменение для оценки общей связи. между систолическим артериальным давлением и ишемической болезнью сердца.
Множественное вменение может повысить достоверность медицинских исследований. Однако процедура множественного вменения требует, чтобы пользователь смоделировал распределение каждой переменной с пропущенными значениями в терминах наблюдаемых данных. Достоверность результатов множественного вменения зависит от тщательного и надлежащего проведения такого моделирования. Множественное вменение не следует рассматривать как рутинный метод, применяемый одним нажатием кнопки — во всех случаях, когда необходимо получить помощь специалиста в области статистики.
Подводные камни в анализе множественного вменения
В недавней статье BMJ сообщалось о разработке инструмента QRISK для прогнозирования сердечно-сосудистого риска, основанного на большой базе данных исследований общей практики. 17 Исследователи правильно определили проблему с отсутствующими данными в своей базе данных и использовали множественное вменение для обработки недостающих данных в своем анализе. Однако в их опубликованной модели прогноза было обнаружено, что риск сердечно-сосудистых заболеваний не связан с холестерином (кодируемым как отношение общего холестерина липопротеинов высокой плотности к холестерину высокой плотности), что было неожиданно.18 Впоследствии авторы пояснили, что, когда они ограничили свой анализ людьми с полной информацией (без пропущенных данных), возникла четкая связь между холестерином и риском сердечно-сосудистых заболеваний. Более того, аналогичный результат был получен после использования пересмотренной, улучшенной процедуры вменения19. Таким образом, важно знать о проблемах, которые могут возникнуть при анализе множественных вменений, которые мы обсудим ниже.
17 Исследователи правильно определили проблему с отсутствующими данными в своей базе данных и использовали множественное вменение для обработки недостающих данных в своем анализе. Однако в их опубликованной модели прогноза было обнаружено, что риск сердечно-сосудистых заболеваний не связан с холестерином (кодируемым как отношение общего холестерина липопротеинов высокой плотности к холестерину высокой плотности), что было неожиданно.18 Впоследствии авторы пояснили, что, когда они ограничили свой анализ людьми с полной информацией (без пропущенных данных), возникла четкая связь между холестерином и риском сердечно-сосудистых заболеваний. Более того, аналогичный результат был получен после использования пересмотренной, улучшенной процедуры вменения19. Таким образом, важно знать о проблемах, которые могут возникнуть при анализе множественных вменений, которые мы обсудим ниже.
Исключение переменной результата из процедуры вменения
Часто анализ исследует связь между одним или несколькими предикторами и результатом, но некоторые из предикторов имеют пропущенные значения.В этом случае результат содержит информацию об отсутствующих значениях предикторов, и эту информацию необходимо использовать.20 Например, рассмотрим модель выживания, связывающую систолическое артериальное давление со временем до ишемической болезни сердца, подогнанную к данным, которые имеют некоторые пропущенные значения систолическое кровяное давление. Когда вменяются недостающие значения систолического артериального давления, у лиц, у которых развивается ишемическая болезнь сердца, должны быть в среднем более высокие значения, чем у тех, у кого болезнь не наблюдается. Отсутствие учета исхода ишемической болезни сердца и времени до этого результата при вменении недостающих значений систолического артериального давления могло бы ошибочно ослабить связь между систолическим артериальным давлением и ишемической болезнью сердца.
Работа с переменными с ненормальным распределением
Многие процедуры множественного вменения предполагают, что данные распределены нормально, поэтому включение переменных с ненормальным распределением может привести к смещению. Например, если биохимический фактор имел сильно искаженное распределение, но неявно предполагалось, что он имеет нормальное распределение, то процедуры вменения могут дать некоторые неправдоподобно низкие или даже отрицательные значения. Прагматический подход здесь состоит в том, чтобы преобразовать такие переменные, чтобы приблизиться к нормальности перед вменением, а затем преобразовать вмененные значения обратно в исходную шкалу.При отсутствии данных в двоичных или категориальных переменных возникают различные проблемы. Некоторые процедуры21 могут обрабатывать эти типы отсутствующих данных лучше, чем другие 13, и эта область требует дальнейших исследований.22 23
Например, если биохимический фактор имел сильно искаженное распределение, но неявно предполагалось, что он имеет нормальное распределение, то процедуры вменения могут дать некоторые неправдоподобно низкие или даже отрицательные значения. Прагматический подход здесь состоит в том, чтобы преобразовать такие переменные, чтобы приблизиться к нормальности перед вменением, а затем преобразовать вмененные значения обратно в исходную шкалу.При отсутствии данных в двоичных или категориальных переменных возникают различные проблемы. Некоторые процедуры21 могут обрабатывать эти типы отсутствующих данных лучше, чем другие 13, и эта область требует дальнейших исследований.22 23
Вероятность случайного отсутствия данных
«Случайное отсутствие данных» — это допущение, которое оправдывает анализ, а не свойство данные. Например, предположение о случайном отсутствии данных может быть разумным, если переменная, которая прогнозирует отсутствие данных в интересующей ковариате, включена в модель вменения, но не в том случае, если переменная не включена в модель.Множественный анализ вменения позволит избежать систематической ошибки только в том случае, если в модель вменения будет включено достаточное количество переменных, позволяющих прогнозировать пропущенные значения. Например, если у лиц с высоким социально-экономическим статусом будет больше шансов измерить систолическое артериальное давление и меньше шансов иметь высокое систолическое артериальное давление, тогда, если социально-экономический статус не включен в модель, используемую при вменении систолического артериального давления, множественное вменение будет занижено. среднее систолическое артериальное давление и может ошибочно оценить связь между систолическим артериальным давлением и ишемической болезнью сердца.
Разумно включать широкий диапазон переменных в модели вменения, включая все переменные в основном анализе, плюс, насколько это возможно с вычислительной точки зрения, все переменные, предсказывающие сами пропущенные значения, и все переменные, влияющие на процесс, вызывающий пропущенные данные , даже если они не представляют интереса для анализа по существу24. Невыполнение этого требования может означать, что случайно пропущенное допущение не является правдоподобным и что результаты анализа по существу являются необъективными.
Невыполнение этого требования может означать, что случайно пропущенное допущение не является правдоподобным и что результаты анализа по существу являются необъективными.
Данные, которые отсутствуют не случайно
Некоторые данные по своей природе отсутствуют не случайно, потому что невозможно учесть систематические различия между отсутствующими значениями и наблюдаемыми значениями, используя наблюдаемые данные. В таких случаях множественное вменение может привести к ошибочным результатам. Например, рассмотрим исследование, изучающее предикторы депрессии. Если люди с большей вероятностью пропускают встречи из-за того, что они находятся в депрессивном состоянии в день встречи, тогда может оказаться невозможным сделать правдоподобным случайное пропущенное предположение, даже если в модель вменения включено большое количество переменных.Когда данные отсутствуют не случайно, смещение в анализе, основанном на множественном вменении, может быть таким же или большим, чем смещение в анализе полных случаев. К сожалению, по данным невозможно определить, насколько серьезной может быть проблема. Ответственность за рассмотрение всех возможных причин отсутствия данных и оценку вероятности того, что пропущенные данные не случайны, являются серьезной проблемой, возлагается на аналитика данных.
Если полные случаи и множественный анализ вменения дают разные результаты, аналитик должен попытаться понять, почему, и об этом следует сообщить в публикациях.
Вычислительные задачи
Множественное вменение требует больших вычислительных ресурсов и включает аппроксимации. Некоторые алгоритмы необходимо запускать повторно, чтобы получить адекватные результаты, а требуемая длина выполнения увеличивается, когда больше данных отсутствует. Непредвиденные трудности могут возникнуть, когда алгоритмы работают в условиях, отличных от тех, в которых они были разработаны, например, с большой долей отсутствующих данных, очень большим количеством переменных или небольшим количеством наблюдений. Эти вопросы более подробно обсуждаются в другом месте.25
Эти вопросы более подробно обсуждаются в другом месте.25
Практическое значение
Модели вменения, которые использовались в первоначальной и пересмотренной версиях инструмента прогнозирования сердечно-сосудистого риска QRISK, обсуждаемого выше, были разъяснены.26 Основные причины неожиданного открытия Нулевой ассоциацией между уровнем холестерина и риском сердечно-сосудистых заболеваний был упущение результатов сердечно-сосудистых заболеваний при вменении недостающих значений холестерина и вычислении отношения холестерина к ЛПВП на основе вмененных значений холестерина и ЛПВП, что привело к крайним значениям этого отношения, включенным в оценки.Воздействие этих ловушек было усилено большой долей отсутствующих данных (отсутствовали 70% значений холестерина ЛПВП).
Отчетность в новейшей литературе
Множественное вменение обычно включает гораздо более сложное статистическое моделирование, чем анализ одиночной регрессии, обычно описываемый в медицинских исследовательских работах. Однако ограничения на объем медицинских исследовательских работ означают, что детали процедуры вменения часто сообщаются кратко или вообще не сообщаются.Незнание рецензентами метода множественного вменения может затруднить им постановку соответствующих вопросов об используемых методах.
Чтобы изучить недавнее использование и отчетность по множественному вменению, мы провели поиск статей, сообщающих об оригинальных исследованиях, в четырех основных медицинских журналах ( New England Journal of Medicine , Lancet , BMJ и JAMA ). выводы, в которых использовалось множественное вменение. Статьи были найдены с использованием средств поиска на веб-сайтах каждого журнала для поиска фразы «множественное вменение» в полном тексте всех статей, опубликованных в течение указанного периода.Мы нашли 59 статей, и сообщаемое использование множественного вменения примерно удвоилось за шесть лет.
Таблица⇓ обобщает результаты нашего исследования. Использовались различные методы множественного вменения, при этом о конкретном методе часто сообщалось лишь неопределенно (например, со ссылкой на книгу). Тридцать шесть статей содержали по крайней мере некоторую информацию о количестве недостающих данных, но только семь полностью или частично сообщали о сравнениях распределений ключевых переменных у лиц с отсутствующими данными и без них.О количестве наборов данных, основанных на вменении, сообщалось в 22 документах. Результаты как предполагаемого, так и полного анализа случаев были полностью представлены только в семи статьях, причем в одном из них был представлен анализ чувствительности. Таким образом, редко удавалось оценить влияние допуска отсутствующих данных. Переменные, используемые в моделях вменения, редко указывались в списке, и вероятность случайного пропуска допущения редко оценивалась или обсуждалась.
Использовались различные методы множественного вменения, при этом о конкретном методе часто сообщалось лишь неопределенно (например, со ссылкой на книгу). Тридцать шесть статей содержали по крайней мере некоторую информацию о количестве недостающих данных, но только семь полностью или частично сообщали о сравнениях распределений ключевых переменных у лиц с отсутствующими данными и без них.О количестве наборов данных, основанных на вменении, сообщалось в 22 документах. Результаты как предполагаемого, так и полного анализа случаев были полностью представлены только в семи статьях, причем в одном из них был представлен анализ чувствительности. Таким образом, редко удавалось оценить влияние допуска отсутствующих данных. Переменные, используемые в моделях вменения, редко указывались в списке, и вероятность случайного пропуска допущения редко оценивалась или обсуждалась.
Отчетность о множественном вменении в 59 статьях, опубликованных в общих медицинских журналах с 2002 по 2007 гг. *
Предлагаемые руководящие принципы составления отчетов
В эпоху онлайн-приложений к исследовательским работам для авторов целесообразно и разумно предоставлять достаточно подробные сведения об анализе вменения для облегчения экспертной оценки, не отвлекаясь от основного вопроса исследования.Во вставке 2 перечислена информация, которую следует предоставить либо в качестве дополнений, либо в основном документе. Это расширяет руководство, предоставленное в рамках инициативы STROBE, по усилению отчетности наблюдательных исследований27, и дополняет предложения по представлению отчетов об анализах с использованием множественного вменения в эпидемиологической литературе28.
Вставка 2 Рекомендации по представлению любого анализа, на который могут повлиять отсутствующие данные
Сообщите количество пропущенных значений для каждой интересующей переменной или количество наблюдений с полными данными для каждого важного компонента анализа.Если возможно, укажите причины пропущенных значений и укажите, сколько человек было исключено из-за отсутствия данных при сообщении о потоке участников в исследовании.
 Если возможно, опишите причины отсутствия данных в терминах других переменных (а не просто укажите универсальную причину, такую как неэффективность лечения)
Если возможно, опишите причины отсутствия данных в терминах других переменных (а не просто укажите универсальную причину, такую как неэффективность лечения)Уточните, есть ли важные различия между людьми с полными и неполными данными — например, предоставив таблица, в которой сравниваются распределения ключевых переменных воздействия и результатов в этих разных группах
Опишите тип анализа, использованный для учета отсутствующих данных (например, множественное вменение), и сделанные предположения (например, случайное отсутствие данных)
Для анализа, основанного на множественном вменении
Предоставьте подробную информацию о моделировании вменения:
Сообщите подробную информацию об используемом программном обеспечении и ключевых настройках для моделирования вменения
Сообщите количество вмененных наборов данных, которые были созданы (Хотя было предложено, что пяти наборов условно исчисленных данных будет достаточно для теоретической оснований, 10 11 большее число (не менее 20) может быть предпочтительным для уменьшения изменчивости выборки из процесса вменения29)
Какие переменные были включены в процедуру вменения?
Как поступали с нестандартно распределенными и бинарными / категориальными переменными?
Если статистические взаимодействия были включены в окончательный анализ, были ли они также включены в модели вменения?
Если большая часть данных рассчитана, сравните наблюдаемые и вмененные значения.
По возможности предоставьте результаты анализа, ограниченные до полных случаев, для сравнения с результатами, основанными на множественном вменении.Если есть существенные различия между результатами, предложите объяснения, помня о том, что анализ полных случаев может иметь больше случайных вариаций и что при предположении о случайном отсутствии множественного вменения следует скорректировать систематические ошибки, которые могут возникнуть при анализе полных случаев
Обсудите, делают ли переменные, включенные в модель вменения, вероятным случайное пропущенное предположение
Также желательно исследовать устойчивость ключевых выводов к возможным отклонениям от случайного отклонения от допущения о пропущенных случайных ошибках, предполагая, что диапазон пропущенных случайных значений не является случайным.
 механизмы анализа чувствительности.Это область текущих исследований40 31
механизмы анализа чувствительности.Это область текущих исследований40 31
Вставка 3 связывает предлагаемые руководящие принципы использования множественного вменения в опубликованном документе, в котором изучалась экономическая эффективность химиотерапии и стандартной паллиативной помощи у пациентов с развитыми немелкоклеточными легкими. рак.
Вставка 3 Пример использования множественного вменения
Burton et al32 использовали данные рандомизированного контролируемого исследования для сравнения экономической эффективности химиотерапии и стандартной паллиативной помощи у пациентов с распространенным немелкоклеточным раком легкого.Стоимость была получена для подгруппы из 115 пациентов, но только для 82 пациентов.
Они указали объем и распределение недостающих данных в таблице 1 своей статьи. Было заявлено, что характеристики пациента и опухоли сопоставимы с полными и неполными данными, но было указано, что влияние лечения на выживаемость различается. Авторы использовали процедуру множественного вменения в статистическом программном обеспечении SAS (PROC MI) для вменения недостающих данных. Перечислены переменные, включенные в модели вменения.Были созданы пять условно исчисленных наборов данных. Общая длина прогона составила 12 500 итераций, при этом импутации производились после каждых 2500-й импутации. Логарифмические и логит-преобразования использовались для работы с ненормальностью, а двухэтапная процедура использовалась для работы с переменными с высокой долей нулевых значений (полунепрерывные распределения). Перед анализом полные данные были преобразованы в исходные масштабы.
Полный анализ случая привел к более высокой средней стоимости химиотерапии по сравнению с паллиативной помощью (2804 фунта стерлингов (3285 евро; 4580 долларов США), 95% доверительный интервал от 1236 фунтов стерлингов до 4290 фунтов стерлингов), чем анализ с использованием множественного вменения (2384 фунтов стерлингов, 95 фунтов стерлингов). % CI от 833 до 3954 фунтов стерлингов).Полный анализ случая показал, что химиотерапия не была рентабельной (средняя чистая денежная выгода — 3346 фунтов стерлингов), но анализ множественных вменений показал, что она была рентабельной (средняя чистая денежная выгода 1186 фунтов стерлингов), хотя доверительные интервалы были широкими.
В ходе обсуждения авторы отметили, что анализ множественного вменения «предполагает, что неполные данные о затратах отсутствуют случайным образом, так что отсутствие компонентов затрат связано только с наблюдаемыми данными, либо с наблюдаемыми ковариатами, либо с эффективностью.Однако они не обсуждали, насколько правдоподобно случайное пропущенное предположение, и не проводили анализ чувствительности, исследуя устойчивость результатов к предполагаемому отсутствию случайных механизмов.
Резюме
Мы с энтузиазмом относимся к возможности множественного вменения и других методов14 для повышения достоверности результатов медицинских исследований и сокращения потерь ресурсов, вызванных отсутствием данных. Стоимость анализа множественного вменения невелика по сравнению со стоимостью сбора данных.Было бы жаль, если бы предотвращаемые ловушки множественного вменения замедлили прогресс в направлении более широкого использования этих методов. Больше не может быть оправдано отсутствие значений и причины, по которым они возникли, чтобы быть скрытым, а также потенциально вводящий в заблуждение и неэффективный анализ полных случаев, чтобы считаться адекватным. Мы надеемся, что обсуждаемые здесь подводные камни и рекомендации будут способствовать правильному использованию и представлению методов работы с недостающими данными.
Примечания
Процитируйте это как: BMJ 2009; 338: b2393
Сноски
Мы благодарим Люсинду Биллингем за проверку нашего описания статьи, описанной во вставке 3.
Соавторы: JACS, IRW, JBC и JRC написали первый черновик статьи.
 MS провела обзор использования множественного вменения в медицинских журналах и проанализировала данные. Все авторы внесли свой вклад в окончательный вариант и последующие редакции статьи. JACS, IRW и JRC выступят в качестве поручителей.
MS провела обзор использования множественного вменения в медицинских журналах и проанализировала данные. Все авторы внесли свой вклад в окончательный вариант и последующие редакции статьи. JACS, IRW и JRC выступят в качестве поручителей.Финансирование: финансируется за счет гранта Совета медицинских исследований Великобритании G0600599. IRW был поддержан грантом MRC U.1052.00.006, а JBC — грантом 334336 NHMRC (Австралия).
Конкурирующие интересы: не заявлены.
Провенанс и экспертная оценка: Не введен в эксплуатацию; внешняя экспертная оценка.
Каталожные номера
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
Little RJ, Rubin DB. Статистический анализ с отсутствующими данными. 2-е изд. Нью-Йорк: Wiley, 2002.
- ↵
- ↵
- ↵
- ↵
- ↵
Goldstein H, Carpenter J, Kenward MG, Levin K.Многоуровневые модели с многомерными смешанными типами отклика. Статистическое моделирование (в печати).
- ↵
Schafer JL. Анализ неполных многомерных данных. Лондон: Chapman and Hall, 1997.
- ↵
- ↵
- ↵
Рубин Д. Множественное вменение для неполучения ответов в опросах. Нью-Йорк: Wiley, 1987.
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- 000
- 000
- 000
- 000
- 000 ↵
- ↵
- ↵
Вменение отсутствующих данных в многомерные наборы данных розничной торговли (20110121, Dr.Ариндам Банерджи), доступный по адресу Technology Commercialization
Статус IP: Патент США выдан; Приложение №: 13/204 237Множественные прогнозы отсутствующих данных
Новая система обеспечивает множественное вменение отсутствующих элементов данных в наборах данных розничной торговли, используемых для моделирования и приложений поддержки принятия решений. Этот метод основан на многомерной тензорной структуре наборов данных и предлагает быструю масштабируемую схему, подходящую для больших наборов данных. Реализованный на компьютере алгоритм сначала идентифицирует набор данных розничной торговли (измеренное количество продуктов «p» за несколько периодов времени «t» и несколько розничных сетей и магазинов «s»).Затем он кодирует фиктивные переменные, соответствующие отсутствующим данным для релевантных комбинаций (p, s, t), и предоставляет множественные вменения отсутствующих данных для получения множества «полных» наборов данных для моделирования спроса.
Этот метод основан на многомерной тензорной структуре наборов данных и предлагает быструю масштабируемую схему, подходящую для больших наборов данных. Реализованный на компьютере алгоритм сначала идентифицирует набор данных розничной торговли (измеренное количество продуктов «p» за несколько периодов времени «t» и несколько розничных сетей и магазинов «s»).Затем он кодирует фиктивные переменные, соответствующие отсутствующим данным для релевантных комбинаций (p, s, t), и предоставляет множественные вменения отсутствующих данных для получения множества «полных» наборов данных для моделирования спроса.
На основе многомерной тензорной структуры наборов данных
Существующие методы вменения недостающих элементов данных в наборы данных розничной торговли сталкиваются с некоторыми ограничениями. Во-первых, отсутствующие элементы данных обычно заменяются определенными точечными оценками их соответствующих вмененных значений.Следовательно, результирующий набор данных не отражает естественную изменчивость, которая была бы, если бы отсутствующие данные были фактически записаны, а не вменены. Это упущение приводит к статистической погрешности в последующих анализах. Во-вторых, текущие процедуры обычно игнорируют корреляции данных по различным измерениям набора данных или могут рассматривать эти корреляции только по одному измерению. Путем одновременного рассмотрения многомерных зависимостей и корреляций в наборе данных розничной торговли можно получить гораздо большую точность и статистическую надежность.В этом новом подходе применяется многомерная тензорная структура наборов данных для обеспечения множественного вменения отсутствующих элементов данных в наборах данных розничной торговли.
Этап разработки
Преимущества
- Быстрая масштабируемая схема, подходящая для больших наборов данных
Характеристики
- Множественное вменение отсутствующих элементов данных в наборах данных розничной торговли
- На основе многомерного тензорного представления наборов данных
- Получает множество «полных» наборов данных для моделирования спроса
Приложения
- Прогнозирование отсутствующих элементов данных или значений в наборах данных розничной торговли
- Множественное вменение отсутствующих элементов данных
Профессор, информатика и инженерия
Публикации
Технический отчет
| Заинтересованы в лицензировании? |
|---|
Университет полагается на партнеров из отрасли при интеграции программного обеспечения в коммерческих целях. Лицензия доступна для этой технологии и предназначена для интеграции, продажи, производства или использования продуктов, заявленных в выданном патенте. Свяжитесь с нами, чтобы поделиться потребностями вашего бизнеса и технической заинтересованностью в этой технологии, а также если вы заинтересованы в лицензировании технологии для дальнейших исследований и разработок. Лицензия доступна для этой технологии и предназначена для интеграции, продажи, производства или использования продуктов, заявленных в выданном патенте. Свяжитесь с нами, чтобы поделиться потребностями вашего бизнеса и технической заинтересованностью в этой технологии, а также если вы заинтересованы в лицензировании технологии для дальнейших исследований и разработок. |
Вменение отсутствующих значений в многомерных феноменальных данных: вменяемые или нет, и как? | BMC Bioinformatics
Реальные данные
Текущая работа мотивирована тремя многомерными наборами феноменальных данных, каждый из которых имеет смесь непрерывных, порядковых, двоичных и номинальных переменных.Набор данных о хронической обструктивной болезни легких (ХОБЛ) был создан на основе исследования ХОБЛ, проведенного в отделении легочных заболеваний медицинского факультета Питтсбургского университета. Второй набор данных — это набор фенотипических данных Консорциума по исследованию тканей легких (LTRC, http://www.nhlbi.nih.gov/resources/ltrc.htm). Третий набор данных получен в результате исследования Программы исследований тяжелой астмы (SARP) (http://www.severeasthma.org/). Эти наборы данных представляют собой различные соотношения переменных / субъектов и различные пропорции типов данных в переменных.В таблице 1 сырые данные (RD) относятся к исходным необработанным данным с отсутствующими значениями, которые мы изначально получили. Полные данные (CD) представляют собой полный набор данных без каких-либо пропущенных значений после итеративного удаления переменных и субъектов с большим процентом пропущенных значений. Компакт-диски не содержат пропущенных значений и идеально подходят для моделирования для оценки различных методов (см. Раздел Моделируемые наборы данных).
Таблица 1 Описание трех наборов реальных данныхМетоды вменения
В этой статье мы сравним четыре недавно разработанных метода KNN с методами MICE и missForest. Ниже описаны методы и подробные реализации.
Ниже описаны методы и подробные реализации.
Два существующих метода MICE и missForest
Многовариантный расчет по цепным уравнениям (MICE) — популярный метод для вменения многомерных пропущенных данных. Он факторизует совместную условную плотность как последовательность условных вероятностей и вменяет пропущенные значения с помощью множественной регрессии последовательно на основе различных типов пропущенных ковариат. Для оценки параметров используется выборка Гиббса. Затем он проводит вменение для каждого условия переменной по всем остальным переменным.Мы использовали R-пакет «MICE» для реализации этого метода.
MissForest — это метод на основе случайных лесов для вменения феноменальных данных [26]. Метод рассматривает переменную пропущенного значения как переменную ответа и заимствует информацию из других переменных с помощью деревьев классификации и регрессии на основе повторной выборки, чтобы вырастить случайный лес для окончательного прогноза. Метод повторяется до тех пор, пока условно исчисленные значения не сойдутся. Метод реализован в пакете «missForest» R.
Методы вменения KNN
Метод KNN популярен благодаря своей простоте и доказанной эффективности во многих задачах вменения пропущенных значений.Для пропущенного значения метод ищет его K ближайших переменных или субъектов и рассчитывает средневзвешенное значение наблюдаемых значений идентифицированных соседей. Мы использовали выбор веса из метода LSimpute, который использовался для вменения пропущенных значений микроматрицы [28]. LSimpute — это расширение KNN, которое использует корреляции между генами и массивами, а недостающие значения вменяются средневзвешенным значением гена и оценок на основе массива. В частности, вес для k -го соседа отсутствующей переменной или объекта был задан как wk = rk2 / 1-rk2 + ε2, где r k — корреляция между k -м соседом и отсутствующей переменной или субъект и ε = 10 -6 .В результате этот алгоритм дает больший вес более близким соседям. Здесь мы расширили два метода KNN для LSimpute: вменение по ближайшим переменным (KNN-V) и вменение по ближайшим субъектам (KNN-S), чтобы их можно было использовать для вменения феноменальных данных со смешанными типами переменных. Кроме того, мы разработали гибрид этих двух методов с использованием глобальных весов переменных / субъектов (KNN-H) и адаптивных весов переменных / субъектов (KNN-A).
Здесь мы расширили два метода KNN для LSimpute: вменение по ближайшим переменным (KNN-V) и вменение по ближайшим субъектам (KNN-S), чтобы их можно было использовать для вменения феноменальных данных со смешанными типами переменных. Кроме того, мы разработали гибрид этих двух методов с использованием глобальных весов переменных / субъектов (KNN-H) и адаптивных весов переменных / субъектов (KNN-A).
Импутация по ближайшим переменным (KNN-V)
Чтобы расширить метод вменения KNN на данные со смешанными типами переменных, мы использовали установленные меры статистической корреляции между различными типами данных для измерения расстояния между различными типами переменных.Как описано в таблице 1, феноменальные данные обычно содержат четыре типа переменных — непрерывные (Con), двоичные (Bin), многоклассовые категориальные (Cat) и порядковые (Ord). В таблице 2 перечислены меры корреляции для разных типов данных для построения корреляционной матрицы для KNN-V (дополнительный файл 1 содержит более подробное описание):
Таблица 2 Измерения корреляции между различными типами переменныхРанговая корреляция Спирмена (Con vs.Против): мы используем ранговую корреляцию Спирмена для измерения корреляции между двумя непрерывными переменными. Это эквивалентно вычислению корреляции Пирсона на основе рангов: r = 1-6 × Σi = 1Ndi2N × N2-1, где d i — разность рангов каждого соответствующего наблюдения, а N — количество испытуемых.
Точечная бисериальная корреляция (Con vs. Bin) и ее расширение (Con vs. Cat): Точечная бисериальная корреляция между непрерывной переменной X и дихотомической переменной Y (Y = 0 или 1) определяется как r = X-1- X-0SX / pY × 1-pY, где X-1 и X-0 представляют собой средние значения X при Y = 1 и 0 соответственно, S X , стандартное отклонение X и p Y , пропорция испытуемые с Y = 1.Обратите внимание, что точечная бисериальная корреляция математически эквивалентна корреляции Пирсона, и для Y нет никакого основного предположения. Когда Y является многоуровневой категориальной переменной с более чем двумя возможными значениями, точечная бисериальная корреляция может быть обобщена, предполагая, что Y следует за полиномиальное распределение и условное распределение X при заданном Y нормально [29]. Это реализовано функцией «biserial.cor» в пакете «ltm» R.
Когда Y является многоуровневой категориальной переменной с более чем двумя возможными значениями, точечная бисериальная корреляция может быть обобщена, предполагая, что Y следует за полиномиальное распределение и условное распределение X при заданном Y нормально [29]. Это реализовано функцией «biserial.cor» в пакете «ltm» R.
Ранговая бисериальная корреляция (Ord vs Bin) и ее расширение (Ord vs Cat): ранговая бисериальная корреляция заменяет непрерывную переменную X в точечной бисериальной корреляции на ранги.Чтобы вычислить корреляцию между порядковой и номинальной переменной (двоичной или многоклассовой), мы преобразуем порядковую переменную в ранги, а затем применяем ранговую бисериальную корреляцию или ее расширение для вычисления [30].
Полисериальная корреляция (Con vs Ord): Полисериальная корреляция измеряет корреляцию между непрерывным X и порядковой переменной Y. Предполагается, что Y определяется из скрытой непрерывной переменной η, генерируемой с равным пространством и строго монотонной. Совместное распределение наблюдаемой непрерывной переменной X и η считается двумерным нормальным.Полисериальная корреляция — это предполагаемая корреляция между X и η, которая оценивается по максимальной вероятности [31]. Это реализовано функцией «polyserial» в пакете «polycor» R.
Полихорическая корреляция (Ord vs Ord): Полихорическая корреляция измеряет корреляцию между двумя порядковыми переменными. Подобно полисериальной корреляции, описанной выше, полихорическая корреляция оценивает корреляцию двух основных скрытых непрерывных переменных, которые, как предполагается, подчиняются двумерному нормальному распределению [32].Это реализовано функцией «полихор» в пакете «polycor» R.
Phi (Bin vs Bin): коэффициент Phi измеряет корреляцию между двумя дихотомическими переменными. Коэффициент phi — это линейная корреляция лежащего в основе двумерного дискретного распределения [33] — [35]. Корреляция Phi рассчитывается как r = X2 / N, где N — количество испытуемых, а X 2 — статистика хи-квадрат для таблицы сопряженности 2 × 2 двух бинарных переменных.
V Крамера (корзина против кошки и кошка против кошки): V Крамера измеряет корреляцию между двумя номинальными переменными с двумя или более уровнями.Он основан на статистике хи-квадрат Пирсона [36]. Формула имеет следующий вид: r = X2N × H-1, где N — количество испытуемых, X 2 — статистика хи-квадрат для таблицы непредвиденных обстоятельств, а H — количество строк или столбцов, в зависимости от того, что меньше.
Отметим, что все меры корреляции в таблице 2 основаны на классической корреляции Пирсона (некоторые с дополнительными гауссовыми предположениями о данных), и в результате корреляции из разных типов данных сопоставимы при выборе K ближайших соседей.Соответствующая мера расстояния может быть вычислена как d = | 1 — r |, где r — мера корреляции между попарными переменными. Учитывая пропущенное значение в матрице данных для переменной x (отсутствует в субъекте i), только K ближайших соседей x (обозначенных как y 1 … y K ) включаются в модель прогнозирования. Кроме того, ни одному из y 1 ,…, y K не разрешено иметь пропущенные значения для того же объекта, что и пропущенное значение, которое нужно спрогнозировать. Для каждого соседа строится обобщенная модель линейной регрессии с одним предиктором: g (μ) = α + βy k с использованием доступных случаев, где μ = E (x) и g (.ik = g-1α + βyik. Наконец, средневзвешенное значение оцененных вмененных значений от K ближайших соседей используется для вменения отсутствующего значения непрерывного типа данных. Для номинальных переменных (двоичных или многоклассовых категориальных) используется взвешенное большинство голосов от K ближайших соседей. Для порядковых переменных мы рассматриваем уровни как положительные целые числа (например, 1, 2, 3,…, q), а вмененное значение дается округленным значением средневзвешенного значения.
Таблица 3 Методы агрегирования информации о вменении различных типов данных от K ближайших соседейВменение ближайшими субъектами (KNN-S)
Процедура KNN-S в целом такая же, как и в KNN-V. Здесь мы заимствуем информацию от ближайших субъектов, а не от переменных. Таким образом, у нас будет смешанный тип значений внутри каждого вектора (предмета). Мы определили сходство пары испытуемых расстоянием Гауэра [37]. Для каждой пары субъектов это среднее расстояние между каждой переменной для рассматриваемой пары субъектов: dij = Σv = 1VδijvdijvΣv = 1Vδijv, где d ijv — оценка несходства между испытуемыми i и j для v th переменная и δ ijv указывает, доступна ли переменная v th как для субъектов i, так и для j; принимает значение 0 или 1.В зависимости от различных типов переменных, d ijv определяется по-разному: (1) для дихотомических и многоуровневых категориальных переменных d ijv = 0, если два субъекта согласны по переменной v th , в противном случае d ijv = 1; (2) вклад других переменных (непрерывных и порядковых) — это абсолютная разница обоих значений, деленная на общий диапазон этой переменной [37]. Расчет расстояния Гауэра реализован функцией «гирлянды» в «кластерном» R-пакете.
Здесь мы заимствуем информацию от ближайших субъектов, а не от переменных. Таким образом, у нас будет смешанный тип значений внутри каждого вектора (предмета). Мы определили сходство пары испытуемых расстоянием Гауэра [37]. Для каждой пары субъектов это среднее расстояние между каждой переменной для рассматриваемой пары субъектов: dij = Σv = 1VδijvdijvΣv = 1Vδijv, где d ijv — оценка несходства между испытуемыми i и j для v th переменная и δ ijv указывает, доступна ли переменная v th как для субъектов i, так и для j; принимает значение 0 или 1.В зависимости от различных типов переменных, d ijv определяется по-разному: (1) для дихотомических и многоуровневых категориальных переменных d ijv = 0, если два субъекта согласны по переменной v th , в противном случае d ijv = 1; (2) вклад других переменных (непрерывных и порядковых) — это абсолютная разница обоих значений, деленная на общий диапазон этой переменной [37]. Расчет расстояния Гауэра реализован функцией «гирлянды» в «кластерном» R-пакете.
Гибридное вменение по ближайшим субъектам и переменным (KNN-H)
Поскольку и ближайшие переменные, и ближайшие субъекты часто содержат информацию для улучшения вменения, мы предлагаем объединить вмененные значения из KNN-S и KNN-V следующим образом:
KNN-H = p × KNN-S + 1-p × KNN-V.
После Bø et. al. [28], мы оценили p путем моделирования 5% вторичных пропущенных значений в наборе данных. Определите набор данных (D ij ) NP с индикатором отсутствующего значения I ij = 1, если он отсутствует, и 0 в противном случае.i20 в качестве оценки p. Подобно вменению KNN-V, вмененные значения KNN-H округляются до ближайшего целого числа для порядковых переменных и взвешенного большинства голосов для номинальных переменных.
Гибридное вменение с использованием адаптивного веса (KNN-A)
Bø et. al. [28] наблюдали, что логарифмические отношения квадратов ошибок logev2 / es2 были убывающей функцией от r max в вменении пропущенного значения микроматрицы, где r max — это корреляция между переменной с пропущенным значением и ее ближайшим соседом. Такая тенденция подсказывала, что, когда r max больше, больший вес следует придавать KNN-V. Таким образом, p должно различаться для разных r max . Мы применили ту же процедуру для оценки адаптивного веса p: мы оценили p на основе e S и e V в каждом скользящем окне r max , (r max -0,1, r max + 0.1) и требуют, чтобы было извлечено не менее 10 наблюдений для вычисления p.
Такая тенденция подсказывала, что, когда r max больше, больший вес следует придавать KNN-V. Таким образом, p должно различаться для разных r max . Мы применили ту же процедуру для оценки адаптивного веса p: мы оценили p на основе e S и e V в каждом скользящем окне r max , (r max -0,1, r max + 0.1) и требуют, чтобы было извлечено не менее 10 наблюдений для вычисления p.
Метод оценки
Мы сравнили различные методы вменения пропущенных значений как в смоделированных, так и в реальных наборах данных.Мы оценили эффективность вменения путем вычисления среднеквадратичной ошибки (RMSE) для непрерывных и порядковых переменных и доли ложной классификации (PFC) для номинальных переменных. Чистые смоделированные данные обсуждаются в смоделированных наборах данных ниже. Для реальных наборов данных мы сначала сгенерировали полный набор данных (CD) из исходного набора необработанных данных (RD) с пропущенными значениями. Затем мы смоделировали пропущенные значения (например, случайным образом с коэффициентом пропущенных 5%), чтобы получить набор данных с пропущенными значениями (MD), выполнили условное вычисление для MD и оценили эффективность, вычислив RMSE между вмененными и реальными значениями.ij-yijp-12 для порядковых переменных (p — количество возможных уровней y j ) и e 2 = X ( ŷ ij ≠ y ij ) для номинальных переменных (χ (.) — индикаторная функция). RMSE для непрерывных и порядковых переменных определяется как avee2, а PFC для номинальных переменных составляет ave ( e ).Мы оценили RMSE и PFC по 20 случайно сгенерированным MD.
Смоделированные наборы данных
Моделирование полных наборов данных (CD). Чтобы продемонстрировать эффективность различных методов при различной структуре корреляции, мы рассмотрели три сценария для моделирования N = 600 субъектов и P = 300 переменных.
Моделирование I (шесть кластеров переменных + шесть тематических кластеров): мы сначала сгенерировали количество субъектов в каждом кластере из Пуа (80) и количество переменных в каждом кластере из Пуа (40).Чтобы создать структуру корреляции между переменными, мы сначала сгенерировали общий базис δ i (i = 1… 6) с длиной N для переменных в кластере i из N (μ, 4), где μ выбирается случайным образом из UNIF (- 2, 2). Затем мы сгенерировали набор наклона и пересечения (α ip , β ip ), p = 1… v i , так что каждая переменная является линейным преобразованием общего базиса и, следовательно, корреляционная структура сохраняется. Остальные переменные, не зависящие от этих сгруппированных переменных, были случайными выборками из N (0, 4).Структура корреляции субъектов была сформирована по аналогичной стратегии: сначала мы сгенерировали общий базис γ j (j = 1… 6) из N (1,2) длиной P. Для всех субъектов в кластере j было γ j . добавлен к каждому из них, чтобы создать корреляцию внутри предметов. Остальные предметы были созданы из N (0, 4 × I P × P ). Чтобы создать данные смешанного типа, мы случайным образом преобразовали 100 переменных в номинальные и 60 переменных в порядковые, произвольно генерируя от 3 до 6 порядковых / номинальных уровней.Пропорции различных типов переменных были аналогичны таковому в наборе данных по ХОБЛ. Тепловые карты матриц объекта и переменного расстояния моделируемых данных показаны на рисунке 1.
Рисунок 1Тепловая карта матрицы расстояний в моделировании I. (a) переменных и (b) Матрицы расстояний до объекта моделирования I . (черный: небольшое расстояние / высокая корреляция; белый: большое расстояние / низкая корреляция).
Моделирование II (двадцать групп переменных + двадцать тематических групп): количество кластеров увеличено до 20.Количество субъектов в каждом кластере было получено из Пуа (25), а количество переменных в каждом кластере — из Пуа (15) (дополнительный файл 1: Рисунок S1).
Моделирование III (без групп переменных + сорок групп субъектов): в этом моделировании мы сгенерировали данные с разреженной корреляцией между переменными, но сильной корреляцией между субъектами, настройка аналогична номинальным переменным в наборе данных SARP (дополнительный файл 1 : Рисунок S6 (c)). Количество субъектов в каждом кластере соответствовало Пуа (14).В каждом тематическом кластере использовалось общее основание γ c (c = 1… 40) с длиной P, которое было добавлено случайной ошибкой из N (0, 0,01). Мы создали разреженную категориальную переменную, отсекая непрерывную переменную на крайних квантилях (≤5% или ≥ 95%), и произвольно генерировали другую точку отсечения из UNIF (0,01, 0,99), что позволило создать до 30 уровней. (Дополнительный файл 1: Рисунок S2).
Создание наборов данных с пропущенными значениями (MD) из полных данных (CD): MD были сгенерированы путем случайного удаления значений m% из смоделированного CD, описанного выше, или CD из реальных данных, описанных в разделе «Реальные данные».В наших исследованиях моделирования мы считали m% = 5%, 20%, 40%. Все три настройки были повторены 20 раз.
Мера вменяемости
Текущая практика в этой области заключается в том, чтобы вменять все недостающие данные после фильтрации переменных или субъектов с более чем фиксированным процентом (например, 20%) пропущенных значений. Эта практика неявно предполагает, что все пропущенные значения вменяются путем заимствования информации из других переменных или субъектов. Это предположение обычно верно для микрочипов или других данных маркеров с высокой пропускной способностью, поскольку гены обычно взаимодействуют друг с другом и совместно регулируются на системном уровне.Однако для многомерных феноменальных данных мы заметили, что многие переменные не связаны или не взаимодействуют с другими переменными и их трудно вменять. Поэтому для выявления этих недостающих значений мы вводим новую концепцию «вменяемости» и разрабатываем количественную «меру вменяемости» (IM). В частности, для набора данных с пропущенными значениями мы генерируем «второй уровень» пропущенных значений, как описано выше. Затем мы выполняем методы KNN-V и KNN-S на «вторичном смоделированном слое» пропущенных значений.Процедура повторяется t раз (обычно достаточно t = 10), и E i и E j могут быть рассчитаны как среднее значение RMSE для пропущенных значений второго уровня объекта i (i = 1,…, N) и переменной j (j = 1,…, P) t раз делений. Пусть IMs i = exp (-E i ) и IMv j = exp (-E j ). IM для отсутствующего значения Dij определяется как max (IMs i , IMv j ). IM предоставляет количественные свидетельства того, насколько хорошо каждое пропущенное значение может быть вменено путем заимствования информации из других переменных или субъектов.Диапазон IM составляет от 0 до 1, а небольшие значения IM представляют собой большие ошибки вменения, которые должны вызывать опасения при использовании вменения. Подробная процедура создания IM описана в Дополнительном файле 2, алгоритм 1. В руководстве по применению, которое будет предложено в разделе «Результат», мы будем рекомендовать пользователям избегать вменения или вменять с осторожностью пропущенные значения, если IM меньше заранее заданного порога.
В частности, для набора данных с пропущенными значениями мы генерируем «второй уровень» пропущенных значений, как описано выше. Затем мы выполняем методы KNN-V и KNN-S на «вторичном смоделированном слое» пропущенных значений.Процедура повторяется t раз (обычно достаточно t = 10), и E i и E j могут быть рассчитаны как среднее значение RMSE для пропущенных значений второго уровня объекта i (i = 1,…, N) и переменной j (j = 1,…, P) t раз делений. Пусть IMs i = exp (-E i ) и IMv j = exp (-E j ). IM для отсутствующего значения Dij определяется как max (IMs i , IMv j ). IM предоставляет количественные свидетельства того, насколько хорошо каждое пропущенное значение может быть вменено путем заимствования информации из других переменных или субъектов.Диапазон IM составляет от 0 до 1, а небольшие значения IM представляют собой большие ошибки вменения, которые должны вызывать опасения при использовании вменения. Подробная процедура создания IM описана в Дополнительном файле 2, алгоритм 1. В руководстве по применению, которое будет предложено в разделе «Результат», мы будем рекомендовать пользователям избегать вменения или вменять с осторожностью пропущенные значения, если IM меньше заранее заданного порога.
Схема самообучающегося выбора (STS)
В нашем анализе ни один метод вменения не показал универсальных результатов лучше, чем все другие методы.Таким образом, лучший выбор метода вменения зависит от конкретной структуры данных. Ранее мы предложили схему самообучающегося выбора (STS) для вменения пропущенных значений микрочипа [24]. Здесь мы применили схему STS и оценили ее производительность на полных реальных наборах данных. На рисунке 2 показана схема схемы STS и то, как мы оценили схему STS. С компакт-диска было смоделировано 20 МД (MD 1 , MD 2 ,…, MD 20 ). Наша цель состояла в том, чтобы определить лучший метод для набора данных. Для этого мы случайным образом сгенерировали второй уровень пропущенных значений в каждом MD b (1 ≤ b ≤ 20) 20 раз и обозначили наборы данных с двумя уровнями пропущенных значений как MD b, i (1 ≤ я ≤ 20). Метод, который дает наилучшие результаты при вменении пропущенных значений второго уровня, т. Е. Генерирует наименьшее среднее значение RMSE, был определен как метод, выбранный схемой STS для вменения пропущенных значений MD b (обозначается как M b, STS ). Рассмотрим оптимальный метод, идентифицированный STS первого уровня как «истинный» оптимальный метод вменения, обозначенный как M b * , мы подсчитали, сколько раз из 20 симуляций M b, STS = M b * ( я.е. Σb = 120IMb, STS = Mb * / 20, где I (.) — индикаторная функция) как точность схемы STS.
Для этого мы случайным образом сгенерировали второй уровень пропущенных значений в каждом MD b (1 ≤ b ≤ 20) 20 раз и обозначили наборы данных с двумя уровнями пропущенных значений как MD b, i (1 ≤ я ≤ 20). Метод, который дает наилучшие результаты при вменении пропущенных значений второго уровня, т. Е. Генерирует наименьшее среднее значение RMSE, был определен как метод, выбранный схемой STS для вменения пропущенных значений MD b (обозначается как M b, STS ). Рассмотрим оптимальный метод, идентифицированный STS первого уровня как «истинный» оптимальный метод вменения, обозначенный как M b * , мы подсчитали, сколько раз из 20 симуляций M b, STS = M b * ( я.е. Σb = 120IMb, STS = Mb * / 20, где I (.) — индикаторная функция) как точность схемы STS.
Схема оценки производительности схемы STS в реальном полном наборе данных (CD). Отсутствующие наборы данных генерируются случайным образом 20 раз (MD 1 ,…, MD 20 ). Схема STS применяется для изучения наилучшего метода из моделирования STS (обозначается как M b, STS для b-го набора отсутствующих данных MD b ). Истинно лучший (с точки зрения RMSE) метод для MD b обозначается как M b * , а лучший метод STS (с точки зрения RMSE по MD b, 1 ,…, MD b, 20 ). обозначается как M b, STS .Когда M b, STS = M b * , схема STS успешно выбирает оптимальный метод.
Оценка глобальных выбросов в окружающую среду: применение множественного условного исчисления
Андридж Р.Р., Литтл Р.Дж. (2010) Обзор условного исчисления «горячей палубы» для неполучения ответов на вопросы обследования. Int Stat Rev 78: 40–64
Статья Google Scholar
Азомаху Т., Лэйсни Ф., Ван Нгуен П. (2006) Экономическое развитие и выбросы CO 2 : непараметрический панельный подход. J Public Econ 90: 1347–1363
J Public Econ 90: 1347–1363
Статья Google Scholar
Бертинелли Л., Штробл Е. (2005) Кривая Кузнеца для окружающей среды с полупараметрическим пересмотром. Econ Lett 88: 350–357
Статья Google Scholar
Coleman A (2009) Модель пространственного арбитража с ограничениями транспортной пропускной способности и внутренними транспортными ценами. Am J Agric Econ 91: 42–56
Статья Google Scholar
Cranmerand SJ, Gill J (2013) Мы должны быть дискретными в этом: непараметрический метод вменения для недостающих категориальных данных.Br J Polit Sci 43: 425–449
Статья Google Scholar
Дасгупта С., Лапланте Б., Ван Х., Уиллер Д. (2002) Противостояние кривой Кузнеца для окружающей среды. J Econ Perspect 16: 147–168
Статья Google Scholar
Гельман А., Хилл Дж. (2006) Анализ данных с использованием регрессии и многоуровневых / иерархических моделей. Издательство Кембриджского университета, Кембридж
Google Scholar
Грэм Дж., Ольховски А., Гилрет Т. (2007) Сколько вменений действительно необходимо? Некоторые практические разъяснения теории множественного вменения.Prev Sci 8: 206–213
Статья Google Scholar
Grossman GM, Krueger AB (1991) Воздействие североамериканского соглашения о свободной торговле на окружающую среду. Рабочие документы NBER 3914, Национальное бюро экономических исследований, Inc
Гроссман Г.М., Крюгер А.Б. (1995) Экономический рост и окружающая среда. Q J Econ 110: 353–377
Статья Google Scholar
Heil MT, Selden TM (2001) Выбросы углерода и экономическое развитие: будущие траектории, основанные на историческом опыте. Environ Dev Econ 6: 63–83
Environ Dev Econ 6: 63–83
Статья Google Scholar
Holtz-Eakin D, Selden TM (1995) Разжигание огня? CO 2 выбросы и экономический рост. J Public Econ 57: 85–101
Статья Google Scholar
Honaker J, King G (2010) Что делать с отсутствующими значениями в данных поперечного сечения временных рядов. Am J Polit Sci 54: 561–581
Статья Google Scholar
Honaker J, King G, Blackwell M (2011) Амелия II: программа для недостающих данных.J Stat Softw 45: 1–47
Google Scholar
Ивами Т. (2004) Экономическое развитие и / или качество окружающей среды: выбросы CO 2 и SO 2 в Восточной Азии. Обсудить серию Пап F Март 2004 г.
Юннинен Х., Ниска Х., Туппурайнен К., Руусканен Дж., Колехмайнен М. (2004) Методы условного расчета недостающих значений в наборах данных о качестве воздуха. Atmos Environ 38: 2895–2907
Статья Google Scholar
Kabacoff R (2011) R в действии: анализ данных и графики с R.Manning Publications Co
Кинг Дж., Хонакер Дж., Джозеф А., Шев К. (2001) Анализ неполных данных по политологии: альтернативный алгоритм для множественного вменения. Am Polit Sci Rev 95: 49–69
Google Scholar
Кузнец С. (1955) Экономический рост и неравенство доходов. Am Econ Rev 45: 1-28
Google Scholar
Ли CC, Chiu YB, Sun CH (2010) Гипотеза экологической кривой Кузнеца для загрязнения воды: имеют ли регионы значение? Энергетическая политика 38: 12–23
Статья Google Scholar
Little RJA (1988) Тест на полное случайное отсутствие для многомерных данных с пропущенными значениями. J Am Stat Assoc 83: 1198–1202
J Am Stat Assoc 83: 1198–1202
Статья Google Scholar
Манаги С., Хибики А., Цуруми Т. (2009) Улучшает ли открытость торговли качество окружающей среды? J Environ Econ Manag 58: 346–363
Статья Google Scholar
Маццанти М., Монтини А., Зоболи Р. (2007) Экологические кривые Кузнеца для парниковых газов и загрязнителей воздуха в Италии: данные из секторальных экологических счетов и данных провинций.Экон Полит 24: 369–406
Google Scholar
Millimet D, List J, Stengos T (2003) Кривая Кузнеца для окружающей среды: реальный прогресс или неверно указанные модели? Rev Econ Stat 85: 1038–1047
Статья Google Scholar
Мияма Э., Манаги С. (2014) Экологическая кривая Кузнеца в Азии. В: Managi S (ed) Справочник по экономике окружающей среды в Азии. Рутледж, Нью-Йорк
Google Scholar
Orubu CO, Omotor DG (2011) Качество окружающей среды и экономический рост: поиск экологических кривых Кузнеца для загрязнителей воздуха и воды в Африке.Энергетическая политика 39: 4178–4188
Статья Google Scholar
Рубин Д.Б. (1976) Вывод и недостающие данные. Биометрия 63: 581–592
Статья Google Scholar
Рубин Д.Б. (1977) Разработка общей и гибкой системы обработки неполучения ответов в выборочных обследованиях. Рабочий документ, подготовленный для Управления социального обеспечения США
Rubin DB, Schenker N (1986) Множественное вменение для интервальной оценки из простых случайных выборок с игнорируемым отсутствием ответа.J Am Stat Assoc 81: 366–374
Статья Google Scholar
Шафик Н. (1994) Экономическое развитие и качество окружающей среды: эконометрический анализ. Oxf Econ Pap 46: 757–773
(1994) Экономическое развитие и качество окружающей среды: эконометрический анализ. Oxf Econ Pap 46: 757–773
Google Scholar
Стерн Д. (2004) Взлет и падение кривой Кузнеца для окружающей среды. World Dev 32: 1419–1439
Статья Google Scholar
Цуруми Т., Манаги С. (2010a) Декомпозиция кривой Кузнеца для окружающей среды: масштаб, техника и композиционные эффекты.Environ Econ Policy Stud 11: 19–36
Статья Google Scholar
Цуруми Т., Манаги С. (2010b) Влияет ли замещение энергии на соотношение выбросов углекислого газа и доходов? J Jpn Int Econ 24: 540–551
Статья Google Scholar
Всемирная комиссия по окружающей среде и развитию (1987) Наше общее будущее. Oxford University Press, Oxford
Google Scholar
Yaguchi Y, Sonobe T, Otsuka K (2007) За пределами кривой Кузнеца для окружающей среды: сравнительное исследование выбросов SO 2 и CO 2 между Японией и Китаем.Environ Dev Econ 12: 445–470
Статья Google Scholar
Импутация
Посмотреть самую последнюю версию.
Архивный контент
Информация, помеченная как архивная, предназначена для справочных, исследовательских или учетных целей. Он не регулируется веб-стандартами правительства Канады и не изменялся и не обновлялся с момента его архивирования. Пожалуйста, «свяжитесь с нами», чтобы запросить формат, отличный от доступных.
Архивировано
Эта страница помещена в архив в Интернете.
Объем и цель
Принципы
Руководящие принципы
Показатели качества
Источники
Объем и назначение
Импутация — это процесс, используемый для присвоения значений замены для отсутствующих, недействительных или несовместимых данных, которые не удалось отредактировать. Это происходит после опроса респондентов (если возможно) и ручного просмотра и исправления анкет (если применимо).Вменение обычно используется для обработки неполучения ответа и, иногда, неответа единицы. Отсутствие ответа по модулю происходит, когда для данной записи не собирается никакая полезная информация, в то время как неответ по элементу происходит, когда собрана некоторая, но не вся желаемая информация. После вменения файл данных обследования обычно должен содержать только достоверные и внутренне непротиворечивые записи данных, которые затем можно использовать для оценки представляющих интерес количеств населения.
Это происходит после опроса респондентов (если возможно) и ручного просмотра и исправления анкет (если применимо).Вменение обычно используется для обработки неполучения ответа и, иногда, неответа единицы. Отсутствие ответа по модулю происходит, когда для данной записи не собирается никакая полезная информация, в то время как неответ по элементу происходит, когда собрана некоторая, но не вся желаемая информация. После вменения файл данных обследования обычно должен содержать только достоверные и внутренне непротиворечивые записи данных, которые затем можно использовать для оценки представляющих интерес количеств населения.
Принципы
В соответствии с принципом Феллеги-Холта (Fellegi and Holt, 1976), поля, подлежащие вменению, определяются путем внесения изменений в минимальное количество полученных ответов, чтобы гарантировать, что завершенная запись прошла все изменения.Определение полей для вменения может быть выполнено до вменения или одновременно с вменением.
Вменение выполняется лицами, имеющими полный доступ к микроданным и, следовательно, владеющими вспомогательной информацией, известной как для единиц с полями, подлежащими вменению, так и без них. Вспомогательная информация может использоваться для прогнозирования пропущенных значений с использованием регрессионной модели, для поиска «близких» доноров для вменения получателей или для построения классов вменения (, например, , Haziza and Beaumont, 2007).Его также можно использовать непосредственно как заменяющие значения для неизвестных пропущенных значений.
Основной принцип, лежащий в основе вменения, заключается в использовании имеющейся вспомогательной информации для максимально точного приближения неизвестных пропущенных значений и, таким образом, для получения оценок качества характеристик совокупности. Следовательно, применение этого принципа обычно должно приводить к уменьшению как систематической ошибки, так и дисперсии, вызванной несоблюдением всех желаемых значений.
Хорошие процессы условного исчисления автоматизированы, объективны и воспроизводимы, позволяют эффективно использовать доступную вспомогательную информацию, имеют контрольный журнал для целей оценки и обеспечивают внутреннюю непротиворечивость условно начисленных записей.
Рекомендации
Вспомогательные переменные
Выбор вспомогательных переменных, используемых для вменения, также называемых соответствующими переменными для вменения доноров, должен в основном основываться на силе их связи с переменными, которые будут вменяться. С этой целью рассмотрите возможность использования методов моделирования и проконсультируйтесь с экспертами в предметной области для получения информации о переменных.
Рассмотрите возможность использования различных источников данных ( e.грамм. текущие данные обследования, исторические данные, административные данные, параданные, и т. Д. ) для переменных, которые могут использоваться в качестве вспомогательных переменных для подстановки пропущенных значений. Изучите качество и соответствие этих доступных переменных, чтобы определить, какие из них в конечном итоге использовать в качестве вспомогательных.
Оцените тип неполучения ответа. То есть попытайтесь определить, какие вспомогательные переменные могут объяснить механизм (ы) неполучения ответов, чтобы использовать их для обогащения метода вменения.Включите такие вспомогательные переменные в метод вменения, особенно если они также связаны с переменными, подлежащими вменению.
Примите во внимание тип характеристик, которые необходимо оценить (например, изменение уровня по сравнению с , агрегаты высокого уровня по сравнению с небольшими областями и перекрестные по сравнению с продольными ) при выборе вспомогательных переменных и разработке условного исчисления.
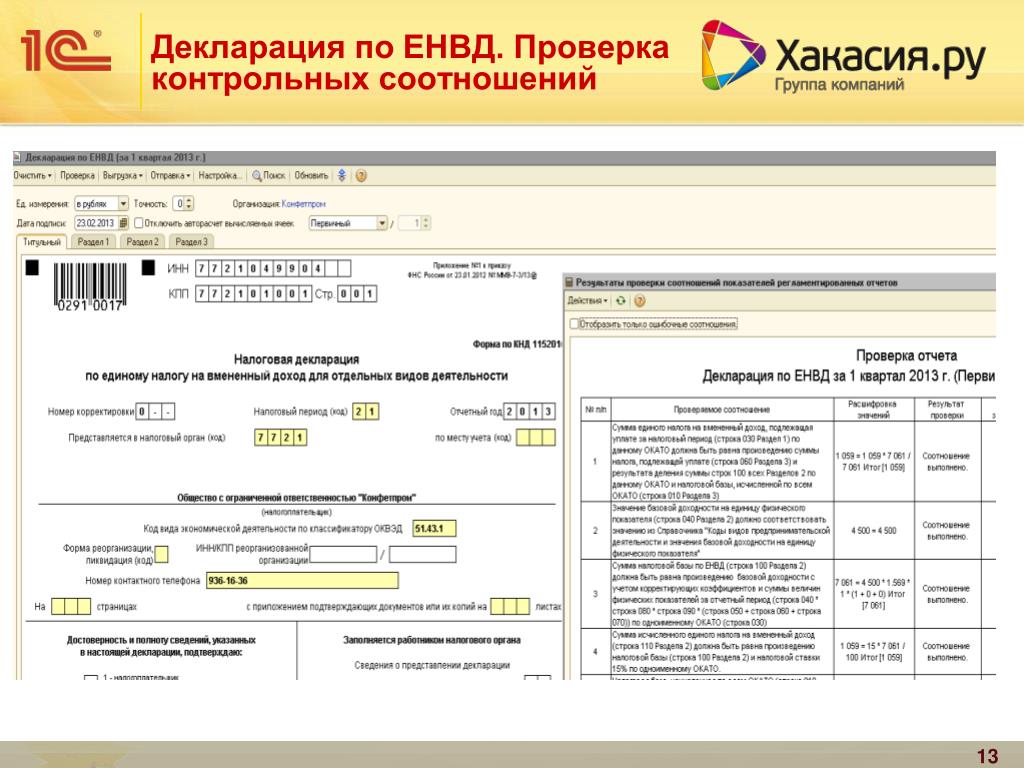 стратегия, направленная на сохранение отношений по интересам; e.грамм. используйте историческую вспомогательную информацию, если вас интересуют изменения, или используйте информацию о домене (если таковая имеется), если вас интересует оценка предметной области.
стратегия, направленная на сохранение отношений по интересам; e.грамм. используйте историческую вспомогательную информацию, если вас интересуют изменения, или используйте информацию о домене (если таковая имеется), если вас интересует оценка предметной области.
Методы вменения и их реализация
Методы вменения можно классифицировать как детерминированные или стохастические, в зависимости от того, присутствует ли некоторая степень случайности в процессе вменения (Kalton and Kasprzyk, 1986; Kovar and Whitridge, 1995).Методы детерминированного вменения включают логическое вменение, историческое (, например, перенос ) вменение, среднее вменение, соотношение и регрессионное вменение и вменение ближайшего соседа. Эти методы можно далее разделить на методы, которые полагаются исключительно на выведение вмененного значения из данных, доступных для не ответивших, и других вспомогательных данных (логических и исторических), и методы, использующие наблюдаемые данные от других респондентов для данного обследования. Наблюдаемые данные от отвечающих единиц могут использоваться напрямую путем передачи данных из выбранной записи донора или с помощью явных параметрических моделей (соотношение и регрессия).Стохастические методы вменения включают случайную горячую колоду, вменение ближайшего соседа, где случайный выбор делается из нескольких «ближайших» ближайших соседей, регрессия со случайными остатками и любой другой детерминированный метод с добавленными случайными остатками.
Обычно следует проводить серьезное моделирование, чтобы выбрать соответствующие вспомогательные переменные и подходящую модель вменения. (Модель вменения — это набор предположений о переменных, требующих вменения.) После того, как такая модель найдена, следует определить стратегию вменения, насколько это возможно, в соответствии с этой моделью. Это должно помочь в контроле систематической ошибки и дисперсии неполучения ответов и может потребоваться для правильной оценки дисперсии.

Попытайтесь заставить вмененную запись быть внутренне непротиворечивой, но как можно более похожей на запись неудавшегося редактирования. Это достигается путем вменения минимального числа переменных в определенном смысле, что позволяет сохранить как можно больше данных о респондентах (принцип Феллеги-Холта).Основное предположение состоит в том, что респондент с большей вероятностью сделает только одну или две ошибки, а не несколько, хотя на практике это не всегда верно.
В некоторых обследованиях необходимо использовать несколько различных типов методов вменения в зависимости от наличия вспомогательной информации. Обычно это достигается в автоматизированной иерархии методов. Тщательно разработайте и протестируйте методы, используемые на каждом уровне иерархии, и максимально ограничьте количество таких уровней.Точно так же, когда требуется свертывание классов вменения, тщательно разработайте и протестируйте методы вменения для каждого набора классов.
Когда используется вменение доноров, постарайтесь вменять данные для записи от как можно меньшего числа доноров. С практической точки зрения это можно интерпретировать как одного донора на каждый раздел вопросника, поскольку практически невозможно обработать все переменные одновременно для большого вопросника. Кроме того, постарайтесь ограничить количество раз, когда конкретный донор используется для вменения получателей, чтобы контролировать дисперсию вмененных оценок.На основе имеющихся доноров это может означать, что одинаково хорошие действия по вменению имеют соответствующий шанс быть выбранным, чтобы избежать искусственного завышения размера определенных групп населения.
Для больших съемок может потребоваться обработка переменных последовательно за два или более прохода, а не за один проход, чтобы снизить вычислительные затраты. Кроме того, в записи могут быть обширные ошибки ответа.
 Любое из этих условий может затруднить точное следование руководящим принципам: могут быть случаи, когда требуется более одного донора (на каждый раздел анкеты) и при этом вменяется более минимальное количество переменных.
Любое из этих условий может затруднить точное следование руководящим принципам: могут быть случаи, когда требуется более одного донора (на каждый раздел анкеты) и при этом вменяется более минимальное количество переменных.
Влияние на смету
Информация о процессе вменения должна храниться в файлах пост-вменения и быть доступной для надлежащей оценки воздействия вменения на оценки, а также на отклонения. Такая информация включает переменные, указывающие, какие значения были вменены и каким методом, переменные, используемые для указания, какие доноры использовались для вменения получателей и так далее. Сохраните не вмененные и вмененные значения полей записи для целей оценки.
Учитывайте степень и влияние вменения при анализе данных. Даже если степень условного вменения низкая, изменения в отдельных записях могут иметь значительное влияние; например, когда изменения вносятся в большие блоки или когда большие изменения вносятся в несколько блоков. В целом, чем больше степень и влияние вменения, тем более рассудительным аналитик должен быть при использовании данных. В таких случаях анализы могут вводить в заблуждение, если вмененные значения рассматриваются как наблюдаемые.
Используемые методы вменения могут не сохранять взаимосвязи между переменными и могут оказывать значительное влияние на распределение данных. Например, на агрегированном уровне могло измениться немногое, но значения в одном домене могли систематически перемещаться вверх, в то время как значения в другом домене могли перемещаться вниз на компенсационную величину. На самом деле это может означать, что переменную предметной области необходимо учитывать в стратегии вменения.
Оцените степень и последствия вменения.Обобщенная система имитационного моделирования (GENESIS) является одним из возможных инструментов для этой цели. Он выполняет вменение в среде моделирования и может использоваться для оценки систематической ошибки и дисперсии вмененных оценок в определенных условиях.

Обобщенные системы
- Существует ряд обобщенных систем, реализующих множество алгоритмов для непрерывных или категориальных данных. Их следует учитывать при разработке методологии вменения.Системы, как правило, просты в использовании после внесения изменений, и они включают алгоритмы для определения полей для вменения. Они хорошо документированы и хранят контрольный журнал, позволяющий оценить процесс вменения. В настоящее время в Статистическом управлении Канады доступны две системы: Generalized Edit and Imputation System (GEIS / BANFF) (Kovar et al , 1988; Statistics Canada, 2000a) для количественных экономических переменных и Canadian Census Edit and Imputation System (CANCEIS) (Bankier и др. , 1999) для качественных и количественных переменных.
Оценка отклонения
Рассмотрите возможность использования методов для адекватного измерения дисперсии выборки при вменении и измерения добавленной дисперсии, вызванной неполучением ответов и вменением (Ли и др. , 2002; Haziza, 2008; Beaumont and Rancourt, 2005). Эта информация требуется для соответствия Политике Статистического управления Канады по информированию пользователей о качестве данных и методологии (Статистическое управление Канады, 2000d; см. Приложение 2, где воспроизводится эта Политика).Для этой цели можно использовать Систему оценки дисперсии из-за неполучения ответов и вменения (SEVANI), разработанную Статистическим управлением Канады.
Заключительный отчет и рекомендации Комитета по мерам качества (Beaumont, Brisebois, Haziza, Lavallée, Mohl, Rancourt and Trépanier, 2008) содержат дополнительные руководящие принципы для оценки дисперсии при наличии условного исчисления, которые следует прочитать и принять во внимание перед внедрением любых новых методология или программное обеспечение.

Ресурсы
- Чтобы получить общую подготовку по вменению или более подробную информацию по некоторым конкретным вопросам, существуют различные ресурсы. Во-первых, предлагается пройти курс Статистического управления Канады «0423: Отсутствие ответов и вменение: теория и применение». Бюллетень Imputation также является интересным и полезным источником информации по этому вопросу. Наконец, внешние консультанты, такие как Дэвид Хазиза и J.N.K. Рао, а также ряд внутренних консультантов, в том числе члены Отдела статистических исследований и инноваций, члены Комитета по показателям качества и члены Комитета по практике вменения, готовы ответить на вопросы.
Показатели качества
Основные элементы качества: точность, своевременность, интерпретируемость, согласованность.
Оценки, полученные после того, как было обнаружено неполучение ответа и использовалось условное исчисление, чтобы справиться с этим неполучением ответа, обычно не эквивалентны оценкам, которые были бы получены, если бы все желаемые значения были соблюдены без ошибок. Разница между этими двумя типами оценок называется ошибкой неполучения ответов. Смещение и дисперсия неполучения ответов ( i.е. смещение и дисперсия, вызванные несоблюдением всех желаемых значений) — это две величины, связанные с ошибкой отсутствия ответа, которые обычно представляют интерес. Эти неизвестные величины, для которых мы в идеале хотели бы получить точные измерения, связаны с аспектом «точность» качества.
Теоретически систематическая ошибка отсутствия ответов устраняется, если стратегия вменения основана на правильно заданной модели вменения с хорошей предсказательной силой. Такая модель вменения также приводит к сокращению дисперсии неполучения ответов.Модель вменения определена правильно, если с учетом выбранных вспомогательных переменных выполняются предположения, лежащие в основе ее первых моментов (обычно среднее значение и дисперсия). Это предсказуемо, если выбранные вспомогательные переменные хорошо связаны с переменными, которые должны быть исчислены. Как указано в приведенных выше рекомендациях, переменные, используемые в определении средства оценки, и переменные, связанные с механизмом неполучения ответов, следует рассматривать как потенциальные вспомогательные переменные. Целью данного руководства является обеспечение того, чтобы при выбранных вспомогательных переменных респонденты и не респонденты были похожи в отношении измеряемых переменных.
Это предсказуемо, если выбранные вспомогательные переменные хорошо связаны с переменными, которые должны быть исчислены. Как указано в приведенных выше рекомендациях, переменные, используемые в определении средства оценки, и переменные, связанные с механизмом неполучения ответов, следует рассматривать как потенциальные вспомогательные переменные. Целью данного руководства является обеспечение того, чтобы при выбранных вспомогательных переменных респонденты и не респонденты были похожи в отношении измеряемых переменных.
Трудно измерить величину систематической ошибки, связанной с неполучением ответов, но можно вывести показатели, которые с ней связаны. Поскольку величина систематической ошибки неполучения ответов зависит от адекватности модели вменения, стандартные методы проверки модели, которые можно найти в классических учебниках по регрессии, можно использовать для получения полезных показателей. Например, графики остатков модели по сравнению с различными вспомогательными переменными, включая предсказанные значения, могут использоваться для обнаружения возможных ошибок в спецификации модели.Остатки также можно использовать для получения различной статистики. Для логистической регрессии полезным индикатором может быть статистика теста Хосмера-Лемешоу. Эти индикаторы также могут быть полезны для того, чтобы дать представление о том, как контролировалась дисперсия неполучения ответов, особенно те, которые дают информацию о силе связи между вспомогательными переменными и переменными, которые должны быть исчислены.
В дополнение к вышеупомянутой диагностике модели, оценки дисперсии неполучения ответов или оценки общей дисперсии могут обеспечить надежные измерения повышенной вариабельности из-за неполучения ответов при условии, что смещение неполучения ответов можно считать достаточно малым.Общая дисперсия — это дисперсия выборки, к которой добавляется компонент отсутствия ответа, чтобы отразить дополнительную неопределенность из-за отсутствия ответа. Существует множество методов оценки дисперсии, которые учитывают неполучение ответов и условное исчисление, а также некоторое программное обеспечение. Например, оценки компонента неполучения ответов или общей дисперсии можно получить, используя SEVANI .
Существует множество методов оценки дисперсии, которые учитывают неполучение ответов и условное исчисление, а также некоторое программное обеспечение. Например, оценки компонента неполучения ответов или общей дисперсии можно получить, используя SEVANI .
Другие индикаторы могут быть рассмотрены и полезны для указания степени условного исчисления, но их труднее напрямую связать с систематической ошибкой и дисперсией неполучения ответов.Коэффициент условного исчисления по переменным и по важным областям является одним из этих показателей. Для оценок итогов и средних значений еще одним полезным показателем является вклад в ключевые оценки, который исходит из условно исчисленных значений. Большой вклад условно исчисленных значений может указывать на то, что смещение и / или дисперсия в связи с неполучением ответов не являются маленькими. Другие индикаторы воздействия условного исчисления на окончательные оценки также могут быть определены для получения дополнительной информации о надежности оценок.
Как подчеркивалось в приведенном выше обсуждении, перед определением любой стратегии вменения необходимо провести серьезное моделирование.Это требует времени и ресурсов. Таким образом, на практике необходимо найти соответствующий баланс между временем, затрачиваемым на создание файла условно исчисленных данных (своевременность), и качеством базовой модели вменения, чтобы избежать необоснованной задержки выпуска данных. В соответствующих случаях использование обобщенных систем для вменения может способствовать значительному сокращению времени обработки, особенно времени, необходимого для разработки системы, и, таким образом, обеспечить, чтобы больше времени можно было посвятить выбору хорошей стратегии вменения.
Наконец, необходимо четко описать и предоставить пользователям методологию условного исчисления вместе с некоторыми из вышеупомянутых показателей и мер. Это обеспечивает лучшую интерпретируемость результатов опроса. Насколько это возможно и актуально, для целей согласованности следует рассмотреть возможность использования аналогичных методологий вменения в обследованиях, собирающих аналогичную информацию.
Это обеспечивает лучшую интерпретируемость результатов опроса. Насколько это возможно и актуально, для целей согласованности следует рассмотреть возможность использования аналогичных методологий вменения в обследованиях, собирающих аналогичную информацию.
Ссылки
Банкир, М., М. Лашанс. и П. Пуарье. 1999. «Общая реализация Новой методологии вменения .» Proceedings of the Survey Research Methods Section. Американская статистическая ассоциация, 548-553.
Beaumont, J.-F., F. Brisebois, D. Haziza, P. Lavallée, C. Mohl, E. Rancourt и J. Trépanier. 2008. Заключительный отчет и рекомендации: Оценка дисперсии при наличии условного исчисления, Комитет по мерам качества. Технический отчет Статистического управления Канады.
Бомонт, Ж.-Ф. и Э. Ранкур. 2005. «Оценка дисперсии при наличии условного исчисления в Статистическом управлении Канады.»Документ, представленный Консультативному комитету Статистического управления Канады по статистическим методам, май 2005 г.
Феллеги, И. и Д. Холт. 1976. «Системный подход к автоматическому редактированию и вменению». Журнал Американской статистической ассоциации. Том. 71. с. 17-35.
Haziza, D., and J.-F. Бомонт. 2007. «О построении классов вменения в обследованиях». Международное статистическое обозрение. Том. 75. с. 25-43.
Хазиза, Д.2008. «Вменение и умозаключение при наличии недостающих данных». В Справочнике по статистике. Том. 29. Глава 10: Выборочные исследования: теория, методы и выводы. Д. Пфефферманн и К.Р. Рао ( ред. ). Elsevier BV (появится).
Kalton, G. and D. Kasprzyk. 1986. «Обработка отсутствующих данных обследования». Методология исследования. Том. 12. с. 1-16.
Ковар, Дж. Г. и П. Уитридж. 1995. «Расчет данных бизнес-обследований.»In Business Survey Methods. B.G. Cox et al. ( eds. ) New York. Wiley. p. 403-423.
Г. и П. Уитридж. 1995. «Расчет данных бизнес-обследований.»In Business Survey Methods. B.G. Cox et al. ( eds. ) New York. Wiley. p. 403-423.
Ковар, Дж. Г., Дж. Макмиллан и П. Уитридж. 1988. Обзор и стратегия обобщенной системы редактирования и вменения. Статистическое управление Канады, Рабочий документ отдела методологии no. BSMD 88-007 E / F.
Ли, Х., Э. Ранкур и К.-Э. Сярндал. 2002. «Оценка отклонения от данных обследования при единственном вменении». В опросе нет ответа.R.M. Groves et al. ( ред. ) Нью-Йорк. Вайли. с. 315-328.
Статистическое управление Канады. 2000г. «Политика информирования пользователей о качестве данных и методологии». Руководство Статистического управления Канады. Раздел 2.3. (Воспроизведено в Приложении 2). Последнее обновление 4 марта 2009 г. /about-apercu/policy-politique/info_user-usager-eng.htm
Статистическое управление Канады 2000a. Функциональное описание обобщенной системы редактирования и вменения. Технический отчет Статистического управления Канады.
ANZ OA IP-CFS Imputation NE (13622.AX) Цена акций, новости, котировки и история
ASX — Цена ASX с задержкой. Валюта в австралийских долларах
0,00000,0000 (0,00%)На момент закрытия: 23:00 AEST
| Предыдущее закрытие | 0,0000 |
| Доходность с начала года | -5,10% |
| Коэффициент расходов (нетто) 90 | 0,00% |
| Категория | Equity Australia Large Blend |
| Прирост последней капитализации | 0. 00 00 |
| Рейтинг Morningstar | ★★★★★ |
| Рейтинг риска Morningstar | Ниже среднего |
| Рейтинг устойчивости | Н / Д |
| Бета (5-летние ежемесячно) | 0,96 | |
| Доходность | 3,47% | |
| Средняя доходность за 5 лет | Нет данных | |
| 1244 | 24 985 Оборот | 4 985 9850.00 |
| Среднее значение для категории | Н / Д | |
| Дата создания | 31 мая 2003 г. |
К сожалению, мы не смогли найти ничего по этой теме.
Откройте для себя новые инвестиционные идеи, получив доступ к объективному и глубокому анализу инвестиций
Frontiers | Оценка точности методов вменения в пятикомпонентной смешанной совокупности
Введение
За последнее десятилетие технологии генотипирования для полногеномных ассоциативных исследований (GWAS) позволили провести обширное и быстрое генотипирование общих вариантов (Ding and Jin, 2009; Ragoussis, 2009; Vergara et al. , 2018). Коммерческие наборы генотипов с однонуклеотидным полиморфизмом (SNP) содержат от 300 000 до 2,5 миллионов маркеров, но ни один из них не имеет полного покрытия генома человека. Вменение генотипа может использоваться для улучшения охвата и мощности GWAS путем определения аллелей негенотипированных SNP на основе паттернов неравновесия по сцеплению (LD), полученных из непосредственно генотипированных маркеров, и сравнения их с подходящей эталонной популяцией (Marchini and Howie, 2010; Pei et al., 2010; Malhotra et al., 2014). Эти условно рассчитанные варианты затем можно использовать для тестирования ассоциации, для улучшения точного картирования целевой области или для проведения метаанализа.
, 2018). Коммерческие наборы генотипов с однонуклеотидным полиморфизмом (SNP) содержат от 300 000 до 2,5 миллионов маркеров, но ни один из них не имеет полного покрытия генома человека. Вменение генотипа может использоваться для улучшения охвата и мощности GWAS путем определения аллелей негенотипированных SNP на основе паттернов неравновесия по сцеплению (LD), полученных из непосредственно генотипированных маркеров, и сравнения их с подходящей эталонной популяцией (Marchini and Howie, 2010; Pei et al., 2010; Malhotra et al., 2014). Эти условно рассчитанные варианты затем можно использовать для тестирования ассоциации, для улучшения точного картирования целевой области или для проведения метаанализа.
Мета-анализ — мощный и широко используемый метод, но если данные исследования были получены с использованием разных платформ, может наблюдаться снижение статистической мощности из-за минимального перекрытия между генотипированными маркерами. Чтобы преодолеть это снижение мощности, вменение может использоваться для увеличения перекрытия маркеров между наборами данных, тем самым повышая мощность метаанализа (Anderson et al., 2008; Марчини и Хауи, 2010; Hancock et al., 2012; Макрей, 2017).
Вменение зависит от адекватного соответствия гаплотипов на основе LD, и поэтому важно, чтобы эталонная популяция была генетически подобна вменяемой популяции. Многочисленные справочные наборы данных находятся в свободном доступе в Интернете и могут использоваться для вменения с помощью подходящего программного обеспечения для вменения. К ним, среди прочего, относятся данные фазы 3 1000 геномов (1000G) (Sudmant et al., 2015), Проект разнообразия генома человека (Cavalli-Sforza, 2005), Консорциум эталонных гаплотипов (HRC) (McCarthy et al., 2016) и консорциумом HapMap (International HapMap 3 Consortium et al., 2010). Большинство вышеупомянутых справочных панелей сосредоточены в основном на представлении европейского населения, а данные по африканскому населению и смешанным популяциям, имеющим африканское происхождение, ограничены.
Африканские и смешанные популяции более разнородны по структуре блоков гаплотипов и, как таковые, выиграют от более крупного набора справочных данных, включающего большее генетическое разнообразие (Vergara et al., 2018).Справочные наборы данных такого рода увеличили бы шансы того, что наблюдаемый гаплотип присутствует в справочных данных, тем самым значительно улучшив точность вменения для африканцев и смешанных лиц африканского происхождения. К счастью, в последние годы произошло существенное увеличение представленности африканского населения в данных 1000G (Sudmant et al., 2015), и были созданы дополнительные базы данных, посвященные представлению африканского населения. Консорциум по астме среди популяций африканского происхождения в Северной и Южной Америке [CAAPA, (Mathias et al., 2016)] справочную панель можно загрузить с сайта dbGap с идентификатором доступа: phs001123.v1.p1 (требуется доступ) и проекта по вариациям африканского генома (AGVP) (Gurdasani et al., 2015), а также с ресурса African Genome Resource ( AGR, не общедоступно) — это три ресурса, которые недавно стали жизнеспособным вариантом для точного вменения численности африканского населения.
AGR 1 содержит самую большую коллекцию гаплотипов африканского происхождения, со всеми образцами 1000G и дополнительными 2000 образцами из Уганды, по 100 образцов из каждой группы из пяти популяций из Эфиопии, Египта, Намибии (Nama / Khoesan) и Южная Африка (зулусский).AGR содержит 97 004 203 двуаллелельных SNP, охватывающих аутосомы и Х-хромосому для 4 956 образцов 1 . Контрольная панель 1000G содержит 84 237 642 двуаллельных SNP для 2 504 образцов, выбранных из 26 популяций в Европе, Азии, Америке, Южной и Восточной Азии (Sudmant et al., 2015). Справочная панель CAAPA содержит полногеномные последовательности для 883 образцов, включенных в 19 исследований типа случай-контроль по астме в Северной и Южной Америке. Всего 31 163 897 аутосомных SNP включены в панель для вменения (Mathias et al. , 2016).
, 2016).
Помимо выбора контрольной панели, используемое программное обеспечение также влияет на точность вменения (Hancock et al., 2012). Многие пакеты программного обеспечения для вменения находятся в свободном доступе и ранее были протестированы и проверены на точность, включая Impute2 (Howie et al., 2009), Beagle (Verma et al., 2014), MaCH, MaCH-Minimac и MaCH-Admix (Roshyara et al., 2014). др., 2016). Эти пакеты программного обеспечения для вменения были оценены среди африканского и афроамериканского населения с использованием различных эталонных панелей, и были получены различные степени качества и точности вменения (Hancock et al., 2012; Рошяра и др., 2016).
Huang et al. (2009) проверили точность вменения в 29 популяциях с использованием справочного материала HapMap и показали, что самая высокая точность вменения была достигнута для европейского населения, за которым следуют группы населения Восточной Азии, Центральной и Южной Азии, Америки, Океании, Ближнего Востока и Африки. . Дополнительный результат этого исследования заключался в том, что объединение нескольких эталонных популяций привело к повышению точности вменения для любой анализируемой совокупности (Huang et al., 2009). Хотя в настоящее время доступны более подходящие эталонные панели, которые повысили бы точность вменения для африканцев, эти результаты показывают, что существуют трудности при вменении популяций, для которых существует ограниченное количество эталонных индивидов.
Точность вменения ранее оценивалась для африканских популяций (Huang et al., 2009; Hancock et al., 2012; Roshyara et al., 2016) и для популяций с двух- или трехсторонним смешиванием, с результатами, достигающими более 75%. точность (Nelson et al., 2016). В настоящем исследовании мы оценили точность вменения в популяции южноафриканских цветных (SAC), смешанных с пятью способами. Население SAC содержит генетический вклад от говорящих на банту африканцев, кхосана, европейцев, а также выходцев из Южной и Восточной Азии (de Wit et al. , 2010; Daya et al., 2013). Хотя вменение в этой совокупности проводилось ранее, а полученные данные использовались для анализа ассоциаций (Chimusa et al., 2014), точность вменения в этой сильно смешанной совокупности еще предстоит оценить.
, 2010; Daya et al., 2013). Хотя вменение в этой совокупности проводилось ранее, а полученные данные использовались для анализа ассоциаций (Chimusa et al., 2014), точность вменения в этой сильно смешанной совокупности еще предстоит оценить.
Здесь мы оценили качество и точность результатов, полученных при вменении в совокупности SAC, и показали, что справочная панель AGR, доступ к которой осуществляется через сервер иммутации Sanger, обеспечивает высочайшее качество и точность вмененных данных. Собственный протокол, использующий контрольную панель IMPUTE2 и 1000G, предполагал больше вариантов, чем Sanger (AGR), но с немного сниженным качеством и точностью.
Методы
Данные SAC
Доступны два источника данных для когорты SAC, а именно генотипы, полученные с использованием массива Affymetrix 500k, содержащего 500000 маркеров SNP (Affymetrix, Калифорния, США), и многоэтнического массива генотипирования Illumina (Illumina, Калифорния, США) ( MEGA) с 1.7 миллионов маркеров. Это исследование было проведено в соответствии с рекомендациями Комитета по этике медицинских исследований Стелленбошского университета (регистрационный номер проекта S17 / 01/013, S17 / 02/037 и 95/072) до набора участников и получения письменного информированного согласия от всем участникам исследования до сбора крови. Все субъекты дали информированное согласие в соответствии с Хельсинкской декларацией. Протокол был одобрен Комитетом по этике медицинских исследований Стелленбошского университета.
Данные генотипа, полученные с использованием массивов Affymetrix и MEGA, были подвергнуты итеративному контролю качества (QC) с использованием PLINK v1.9 (Purcell et al., 2007; Chang et al., 2015), как описано ранее (Schurz et al., 2018) , за исключением связанных лиц, которые не удаляются. Лица, у которых отсутствовала более 10% информации о генотипе, и SNP с отсутствием более 2% были удалены, а также любые варианты с частотой минорных аллелей (MAF) ниже 5%, а также локусы с чрезмерной гетерозиготностью (подробное описание процесса фильтрации можно найти в дополнительных данных S3). Все оставшиеся недостающие данные распределяются случайным образом (данные не показаны), и был использован строгий фильтр SNP, чтобы гарантировать, что в данных нет вариантов с неправильным генотипом, которые могут повлиять на точность вменения (дополнительные данные S4).
Все оставшиеся недостающие данные распределяются случайным образом (данные не показаны), и был использован строгий фильтр SNP, чтобы гарантировать, что в данных нет вариантов с неправильным генотипом, которые могут повлиять на точность вменения (дополнительные данные S4).
Эти шаги контроля качества повторялись до тех пор, пока не удалялись никакие дополнительные варианты или особи, и завершались проверкой соответствия пола для удаления лиц с неверной информацией о поле. Гармонизатор генотипов версии 1.4.15 (Deelen et al., 2014) была использована для согласования двух наборов данных с эталонной панелью 1000 Genomes Phase 3 [сборка 37 генома человека (Sudmant et al., 2015)], обновления идентификаторов SNP и удаления любых вариантов, отсутствующих в эталонной панели. Для совмещения нитей для совмещения требовалось минимальное значение LD 0,3, по крайней мере, с тремя вариантами фланкирования. Вторичное выравнивание MAF также использовалось при пороге 5%. Наконец, минимальная апостериорная вероятность вызова генотипов во входных данных была оставлена равной 0 по умолчанию.4.
Поэтапность и расчет
Три различных контрольных панели были использованы для проведения пяти протоколов фазирования и условного исчисления, чтобы оценить, какой из них наиболее эффективен для нашей смешанной популяции (таблица 1). Первый протокол был внутренним методом, в котором данные Affymetrix (файлы PLINK) были поэтапно распределены с использованием SHAPEIT v2 (Delaneau et al., 2012) с использованием эффективного размера популяции по умолчанию, равного 15 000. Затем был выполнен расчет с использованием IMPUTE2 v2.3.2. (Howie et al., 2009) и контрольная панель 1000G Phase 3 (Sudmant et al., 2015) с параметрами по умолчанию, за исключением эффективного размера популяции, который был установлен на 15 000 для согласованности с процессом фазирования гаплотипа.
Таблица 1. Использованные методы фазирования гаплотипа и вменения генотипа.
Второй и третий протоколы использовали сервер импутации Сэнгера 1 (SIS). Генотипы из массива Affymetrix 500k в формате файла PLINK были преобразованы в формат Variant Call Format (VCF) с помощью PLINK v1.9, а затем загружены на сервер, где фазирование было выполнено с помощью SHAPEITv2.r790 (Delaneau et al., 2012) с последующим вменением с использованием алгоритма позиционного преобразования Барроуза-Уиллера (PBWT) (Durbin, 2014). Вменение было выполнено в двух отдельных прогонах: в первом прогоне использовалась эталонная панель 1000G фазы 3 для вменения, а во втором прогоне использовалась панель ресурсов африканского генома.
Четвертый и пятый протоколы использовали сервер импутации штата Мичиган [MIS, (Das et al., 2016)]. Файлы PLINK были преобразованы в VCF с помощью PLINK v1.9 и загружены на сервер для двух прогонов вменения, оба из которых были выполнены в режиме контроля качества и в режиме вменения.SHAPEITv2.r790 использовался для фазирования гаплотипа в обоих прогонах с последующим вменением с использованием алгоритма Minimac3 (Das et al., 2016). Для первого прогона для контроля качества использовался вариант смешанной популяции, и было выполнено фазирование гаплотипа с последующим вменением с помощью эталонной панели 1000G Phase 3. Для второго прогона вменения афроамериканское население было обязательно выбрано для контроля качества при вменении с помощью контрольной панели CAAPA.
Таким образом, все эти методы по-разному реализуют скрытую марковскую модель (HMM).Impute2 использует цепь Маркова для реализации HMM, а minimac3 использует процедуру Монте-Карло для реализации HMM (Li et al., 2010). PBWT также работает на итерации Монте-Карло, но вместо HMM он выводит гаплотипы с помощью позиционного преобразования Берроуза Уиллера. Все эти алгоритмы вменения выполняют ряд итераций фазирования (вывод гаплотипа) и вменения, а затем вероятности для каждого генотипа усредняются для всех итераций, чтобы получить апостериорную вероятность для каждого вмененного генотипа (дополнительные данные S2).
Хотя предварительная фазировка гаплотипа, как было показано, немного снижает точность вменения, она использовалась в этом исследовании для согласованности между протоколами (сервер в Мичигане не имел возможности не фазировать данные) и для увеличения скорости вменения (Howie et al. ., 2009).
Для всех прогонов вменения контрольные панели включали все доступные совокупности, поскольку известно, что использование комплексной контрольной панели повышает точность вменения (Huang et al., 2009). Из пяти выполненных вариантов вменения только прогон MIS (CAAPA) не смог выполнить вменение по X-хромосоме.Однако результаты для X-хромосомы были включены для других четырех прогонов вменения, поскольку точность X-сцепленного вменения ранее не оценивалась.
Контроль качества условно исчисленных данных
Вмененные данные были возвращены из программного обеспечения вменения в одном из двух форматов: либо в форме файла VCF, либо в формате Impute2 (генерация / выборка), и в зависимости от формата была использована одна из двух процедур контроля качества для преобразования вмененных данные от вероятностей генотипа до фактических генотипов.Данные, полученные в результате двух процедур, были сравнены и показали полное совпадение и, таким образом, могут использоваться как взаимозаменяемые.
Процедура 1
Для внутреннего условного исчисления, выполненного с использованием Impute2, был получен выходной файл генерации / выборки и преобразован в файл PLINK с помощью GTOOL версии 0.7.5. R версии 3.2.4 использовался для идентификации INDELS, которые были удалены с помощью GTOOL (R Development Core Team, 2013). Это было выполнено для более точного присвоения идентификаторов SNP и информации об аллелях при вызове генотипов с помощью GTOOL.Порог определения генотипа был установлен на 0,7, что было определено как лучшее соотношение точности вменения и количества вмененных вариантов (дополнительный рисунок S1). После вызова генотипов полученные файлы PLINK ped / map были преобразованы в файлы PLINK bed / bim / fam, и все варианты с аллелями, не вызывающими вызова, были удалены.
Процедура 2
Для вменения, выполненного с использованием двух онлайн-серверов, были возвращены файлы VCF. Файлы VCF были преобразованы в файлы PLINK ped / map с использованием порога определения генотипа, равного 0.7 (команда PLINK: — команда vcf-min-gp) и кодирование всех не вызывающих вызовов аллелей как N (команда PLINK: — output-missing-genotype N). INDELS и SNP с не вызывающими аллелями были удалены, а файлы преобразованы в формат кровати PLINK (bed / bim / fam).
Качество и точность вменения
Для оценки качества вменения мы рассмотрели внутренние метрики качества, полученные из каждого протокола вменения: балл INFO (в случае IMPUTE2) и значение r-квадрат (для PBWT и Minimac3). Хотя информационная оценка и метрики качества в квадрате нельзя напрямую сравнивать, они показали высокую корреляцию в двух заметных исследованиях: одном, проведенном Маркини и Хоуи (Marchini and Howie, 2010), и другом, проведенном Браунингом и Браунингом (Браунинг и Браунинг, 2016).В обоих документах сообщается, что оценки качества, полученные с помощью нескольких широко используемых программ вменения, включая те, которые используются в протоколах этого исследования, сильно коррелированы. Эти значения находятся в диапазоне от 0 до 1, где более высокое значение указывает на повышенное качество вмененного SNP. Эти показатели качества использовались для оценки качества данных, а не качества данных. Медианные оценки качества были нанесены на график относительно MAF, чтобы определить, как на качество повлиял MAF, и оценить, какой протокол вменения вернул данные наилучшего качества при заданном MAF.
Точность вменения оценивалась путем извлечения перекрывающихся лиц из MEGA и вмененных данных Affymetrix и с использованием PLINK, любые варианты, которые перекрывались между двумя платформами до вменения, были удалены. Между двумя массивами было всего 41 815 вариантов, генотипированных на обеих платформах, и они были равномерно распределены по геному и не должны влиять на анализ, если их удалить после вменения. Анализ выполнялся для каждой хромосомы, и для каждого SNP сравнивались аллели между вмененными данными Affymetrix и данными MEGA.Если оба аллеля SNP совпадают, это будет считаться полным совпадением (или обратным совпадением, если аллели были правильными, но нити поменялись местами). Если совпадал только один аллель, это считалось половинным совпадением, а если ни один аллель не совпадал, это считалось несоответствием. Для каждой хромосомы регистрировали общее количество вмененных вариантов и строили график их распределения по MAF, чтобы определить, как количество вариантов коррелирует с MAF между различными протоколами вменения.
Для определения точности вменения было оценено совпадение SNP между MEGA и вмененными данными Affymetrix.В рамках этого перекрытия количество SNP, которые были полными, перевернутыми, половинными или несовпадающими, регистрировались вместе с их средним баллом INFO или значением r-квадрата. Поскольку перевернутые SNP можно перевернуть, чтобы выровнять ссылку или другой набор данных, если планируется метаанализ, перевернутые SNP считались совпадающими для целей расчета точности вменения. Точность рассчитывалась путем сравнения доли перекрывающихся SNP, которые были полными (или перевернутыми), с количеством перекрывающихся SNP.Это обеспечило указание точности и частоты ошибок в перекрывающейся области и должно быть хорошим показателем общей точности вменения. Эти расчеты были выполнены для аутосом и X-хромосомы отдельно, чтобы определить, насколько точно и с каким качеством были вменены X-сцепленные варианты по сравнению с аутосомными вариантами.
Результаты
Данные генотипирования
После QC и выравнивания цепей 919 особей и 239 612 вариантов со скоростью генотипирования 99.39% осталось в наборе данных Affymetrix 500k, а 771 человек с 1 491 347 вариантами остался в наборе данных MEGA с уровнем генотипирования 99,43%. В общей сложности 325 человек были генотипированы как по массиву Affymetrix, так и по массиву MEGA, и 43 140 маркеров SNP перекрывались между двумя платформами. После вменения 325 человек с данными генотипа как из MEGA, так и из Affymetrix были извлечены как из данных MEGA, так и из вмененных данных Affymetrix, чтобы их вмененные генотипы (Affymetrix) можно было напрямую сравнить с их фактическими генотипами (MEGA) для определения точности генотипирования.43 140 SNP, которые были генотипированы на обеих платформах, были удалены из обоих наборов данных после вменения, чтобы не искажать анализ точности.
Импутация
Для когорты SAC наилучшие результаты вменения генотипа были получены с помощью собственных методов IMPUTE2 (с эталонной панелью 1000G) и сервера вменения Sanger (с эталонной панелью AGR). Собственный метод привел к наиболее предполагаемым вариантам как по аутосомам (60 438 387), так и по Х-хромосоме (2 574 793), за которыми следует SIS (AGR) (52 088 766 аутосомных и 1 638 163 X-сцепленных вариантов), в то время как в SIS с контрольной панелью 1000G было немного меньше вмененных вариантов, чем с панелью AGR (50 418 390 аутосомных и 1 679 254 X-сцепленных вариантов).Сервер вменения в Мичигане имел лишь примерно вдвое меньше вмененных вариантов, чем другие методы, для любой контрольной панели (таблица 2). Количество вмененных вариантов, которые не достигли порога определения генотипа (0,7), было самым низким в собственном методе, за которым следовали результаты сервера Мичигана, а у SIS (1000G) и SIS (AGR) был самый высокий процент вариантов, не достигших генотипа. порог вызова (Таблица 2). Когда вмененные варианты Affymetrix сравнивали с генотипами MEGA, данные SIS (AGR) имели самую высокую точность (в перекрывающейся области) для обеих аутосом (89.27%) и Х-хромосома (90,21%). Точность вменения для внутреннего метода и метода SIS (1000G) была очень похожей, при этом внутренний метод имел немного меньшую частоту ошибок для всего генома. Точность Мичиганского сервера была хорошей для аутосом (~ 62-83%), но недостаточной для Х-хромосомы (~ 65%) (Таблица 3). SIS (AGR) рассчитал наименьшее количество X-связанных вариантов, но с максимальной точностью, тогда как собственный метод имел в два раза больше X-связанных вариантов, чем Sanger, с падением точности только на 1,28% (таблицы 3, 4).
Таблица 2. Количество вмененных вариантов и вариантов, перекрывающихся с MEGA, а также процент вызовов, которые не достигли порога вызова генотипа (0,7). Расчетное количество SNP дано в миллионах, а количество перекрывающихся — на десять тысяч.
Таблица 3. Частота ошибок по всему геному и точность вменения аутосом и Х-хромосомы.
Таблица 4. Количество SNP и соответствующий средний балл качества для трех категорий в перекрывающемся регионе MEGA.
Для аутосом и Х-хромосомы SIS (AGR) дала наилучшее качество вменения во всех диапазонах MAF, за которым последовал внутренний метод, где качество уступало SIS (1000G) только для низкого MAF (0-1%) варианты на Х-хромосоме (рис. 1). Сервер в Мичигане произвел условное исчисление самого низкого качества согласно внутренним показателям качества (рисунок 1 и таблица 4). Средний показатель качества был сопоставим по всем аутосомным хромосомам, и, таким образом, только хромосома 1 показана как представление аутосом и для сравнения с Х-хромосомой (рис. 1).Рисунок 2 подтверждает, что метод SIS (AGR) и внутренний метод дали наилучшее качество вменения, поскольку большее количество SNP было вменено с высоким качеством как для хромосомы 1, так и для X-хромосомы. Поскольку SIS (AGR) имеет наибольшее количество вмененных генотипов, не достигающих порогового значения, существует компромисс между качеством и количеством вариантов между SIS (AGR) и внутренним методом.
Рис. 1. Средний показатель качества для всех вариантов в определенном диапазоне MAF для всех вмененных наборов данных.
Рисунок 2. Распределение количества условно рассчитанных SNP по показателям качества для хромосомы 1 (A), и хромосомы (B), X.
Обсуждение
Точность вменения ранее оценивалась в африканской и трехкомпонентной смешанной популяциях, но мы выполнили первую оценку в пятикомпонентной смешанной совокупности. Точность вменения для лиц афроамериканского происхождения (считающаяся трехкомпонентной) колеблется от 78% (Malhotra et al., 2014) до 89% (Howie et al., 2009). Люди из Южной Африки, говорящие на банту, были вменены с точностью около 95%, и даже у африканских санов точность вменения составила 89% (Huang et al., 2009). В настоящем исследовании SIS (AGR) и внутренний протокол вменения имели схожую точность (89% и 88%, соответственно, таблица 2) по сравнению с предыдущими результатами для африканских и смешанных популяций. Однако следует отметить, что явное большинство несовпадающих вариантов были неоднозначными (вмененный генотип A / T и генотип MEGA G / C, или наоборот), и большинство полусоответствующих вариантов были вменены как мономорфные (данные не показано).Эти неоднозначные варианты были вменены с высоким качеством (таблица 3) и не были удалены при фильтрации по показателю качества, но их можно было удалить или сопоставить с эталонным аллелем с помощью соответствующего программного обеспечения (такого как Genotype Harmonizer). Однако удаление этих неоднозначных вариантов не является обязательным. При анализе одного набора данных интересующие неоднозначные варианты можно сравнить с соответствующим эталонным геномом, а затем перевернуть. Это особенно полезно при проведении метаанализа, поскольку эти варианты будут сопоставимы, даже если они происходят из разных наборов данных.Если эти неоднозначные варианты считаются правильно вмененными, то точность вменения с помощью SIS (AGR) увеличивается до 96%, а точность внутреннего протокола вменения увеличивается до 94%. Точность и качество можно дополнительно повысить, удалив варианты половинного соответствия, применив показатель качества и фильтр массового расхода воздуха.
Поскольку четыре из пяти протоколов были способны вменять Х-сцепленные варианты, и поскольку качество и точность вменения Х-хромосомы ранее не проверялось, мы включили его в этот анализ.Х-хромосома имела лишь немного более низкое или более высокое качество вменения для всех прогонов вменения по сравнению с аутосомами, что указывает на то, что вменение Х-хромосомы может быть выполнено с уверенностью (таблицы 2, 3). Хотя здесь специально не анализируется, следует также отметить качество вменения при низком MAF: качество вменения для редких вариантов было неожиданным, поскольку для точного вменения редких вариантов требуются большие контрольные панели с правильными совокупностями (Kim et al., 2015; Zheng и другие., 2015; Фигура 1).
Самым большим ограничением для вменения в пятикомпонентной смешанной совокупности является отсутствие подходящей контрольной панели. Было показано, что вменение в популяции сан имеет самую низкую точность вменения (89%) по сравнению с другими африканскими популяциями (Huang et al., 2009), что может быть связано с отсутствием подходящих эталонных лиц. Поскольку основным наследственным компонентом в популяции SAC является KhoeSan (Daya et al., 2013), это может повлиять на точность и качество вменения в этой популяции.Однако это улучшилось благодаря добавлению лиц KhoeSan в контрольные панели AGR и 1000G.
В заключение, мы показали, что вменение популяции SAC возможно и дает качественные данные как по аутосомам, так и по Х-хромосоме. В то время как вменение SIS (AGR) имело лучшее качество и точность, внутренний протокол с использованием Impute2 и 1000G Phase 3 также давал вмененные данные высокого стандарта и имел наибольшее количество вмененных вариантов. Этот протокол может оказаться особенно полезным в случае метаанализа, когда нужно максимизировать перекрытие SNP между наборами данных.По мере роста числа применимых эталонных популяций и индивидуумов точность вменения будет улучшаться для африканских и смешанных популяций, но это остается золотым стандартом для последовательности Сэнгера, представляющего интерес варианта для подтверждения того, что вмененный вариант присутствует в популяции до проведения дальнейших исследований. исследовать.
Доступность данных
Сводная статистика для оценки качества и точности данных SAC будет доступна исследователям, которые соответствуют критериям доступа к конфиденциальным данным, после подачи заявки в Комитет по этике медицинских исследований Стелленбошского университета.Запросы можно отправлять по адресу: MM, E-mail: [email protected].
Авторские взносы
HS, SM, GT, CK и MM придумали идею для этого исследования. HS и SM выполнили контроль качества данных. SM провела поэтапную оценку, условное исчисление и оценку качества. HS выполнил оценку точности и написал первый черновик. Все авторы внесли свой вклад в написание и корректуру для утверждения окончательной рукописи.
Финансирование
Это исследование было частично профинансировано правительством ЮАР через Южноафриканский совет медицинских исследований.Авторы несут полную ответственность за содержание, которое не обязательно отражает официальную точку зрения Южноафриканского совета медицинских исследований. Эта работа также была поддержана Национальным исследовательским фондом Южной Африки (грант № 93460) EH и грантом Стратегического партнерства в области инноваций в области здравоохранения Южноафриканского совета медицинских исследований и Министерства науки и технологий / Южноафриканской инициативы по биоинформатике туберкулеза (SATBBI, GW) в GT.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотели бы поблагодарить участников исследования за их вклад и участие.
Дополнительные материалы
Дополнительные материалы к этой статье можно найти в Интернете по адресу: https://www.frontiersin.org/articles/10.3389/fgene.2019.00034/full#supplementary-material
Аббревиатура
1000G, эталонная панель 1000 Genomes Phase 3; AGR, African Genome Resource; AGVP, проект по изменению африканского генома; CAAPA, Консорциум по борьбе с астмой среди популяций африканского происхождения в Северной и Южной Америке; HRC, Консорциум эталонных гаплотипов; MEGA, мультиэтнический набор генотипов; MIS, Мичиганский сервер вменения; PBWT, позиционное преобразование Барроуза-Уиллера; SAC — Южноафриканская цветная; SIS, сервер вменения Sanger.
Сноски
- https://imputation.sanger.ac.uk/
- http://www.well.ox.ac.uk/$/sim$cfreeman/software/gwas/gtool.html
Список литературы
Андерсон, К. А., Петтерссон, Ф. Х., Барретт, Дж. К., Чжуанг, Дж. Дж., Рагусси, Дж., Кардон, Л. Р. и др. (2008). Оценка влияния вменения на мощность, охват и экономическую эффективность полногеномных платформ SNP. Am. J. Hum. Genet. 83, 112–119. DOI: 10.1016 / j.ajhg.2008.06.008
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чанг, К.С., Чоу, К.С., Телльер, Л.С., Ваттикути, С., Перселл, С.М., и Ли, Дж. Дж. (2015). PLINK второго поколения: ответ на вызов более крупных и богатых наборов данных. GigaScience 4: 7. DOI: 10.1186 / s13742-015-0047-8
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чимуса, Э. Р., Зейтлен, Н., Дайя, М., Мёллер, М., ван Хелден, П. Д., Mulder, N.J. и др. (2014). Полногеномное ассоциативное исследование риска родословного ТБ у цветного населения Южной Африки. Гум. Мол. Genet. 1, 796–809. DOI: 10.1093 / hmg / ddt462
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Das, S., Forer, L., Schönherr, S., Sidore, C., Locke, A.E., Kwong, A., et al. (2016). Служба и методы вменения генотипов нового поколения. Нат. Genet. 48, 1284–1287. DOI: 10,1038 / нг. 3656
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Дайя, М., Мерве, Л., ван дер Галал, У., Мёллер, М., Сали, М., Чимуса, Э. Р. и др. (2013). Панель информативных маркеров родословной для сложного пятикомпонентного смешанного цветного населения Южной Африки. PLoS One 8: e82224. DOI: 10.1371 / journal.pone.0082224
PubMed Аннотация | CrossRef Полный текст | Google Scholar
de Wit, E., Delport, W., Rugamika, C.E., Meintjes, A., Möller, M., van Helden, P. D., et al. (2010). Полногеномный анализ структуры южноафриканского цветного населения западного мыса. Гум. Genet. 128, 145–153. DOI: 10.1007 / s00439-010-0836-1
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Deelen, P., Bonder, M. J., van der Velde, K. J., Westra, H.-J., Winder, E., Hendriksen, D., et al. (2014). Гармонизатор генотипа: автоматическое выравнивание цепей и преобразование формата для интеграции данных генотипа. BMC Res. Примечания 7: 901. DOI: 10.1186 / 1756-0500-7-901
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Гурдасани, Д., Carstensen, T., Tekola-Ayele, F., Pagani, L., Tachmazidou, I., Hatzikotoulas, K., et al. (2015). Проект изменения африканского генома формирует медицинскую генетику в Африке. Природа 517, 327–332. DOI: 10.1038 / природа13997
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хэнкок, Д. Б., Леви, Дж. Л., Гэддис, Н. К., Берут, Л. Дж., Сакконе, Н. Л., Пейдж, Г. П. и др. (2012). Оценка эффективности вменения генотипа с использованием 1000 геномов в афроамериканских исследованиях. PLoS One 7: e50610. DOI: 10.1371 / journal.pone.0050610
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хауи, Б. Н., Доннелли, П., и Маркини, Дж. А. (2009). гибкий и точный метод вменения генотипа для следующего поколения полногеномных ассоциативных исследований. PLoS Genet. 5: e1000529. DOI: 10.1371 / journal.pgen.1000529
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хуанг, Л., Ли, Ю., Синглтон, А.Б., Харди, Дж. А., Абекасис, Г., Розенберг, Н. А. и др. (2009). Точность вменения генотипа во всем мире. Am. J. Hum. Genet. 84, 235–250. DOI: 10.1016 / j.ajhg.2009.01.013
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Международный консорциум HapMap 3, Альтшулер, Д. М., Гиббс, Р. А., Пелтонен, Л., Альтшулер, Д. М., Гиббс, Р. А. и др. (2010). Объединение общих и редких генетических вариаций в различных человеческих популяциях. Природа 467, 52–58.DOI: 10.1038 / nature09298
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ким, Ю. Дж., Ли, Дж., Ким, Б.-Дж., Консорциум T2D-Genes и Парк, Т. (2015). Новая стратегия повышения качества вменения редких вариантов на основе данных секвенирования следующего поколения путем объединения данных SNP и чипа экзома. BMC Genomics 16: 1109. DOI: 10.1186 / s12864-015-2192-y
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ли Ю., Виллер К. Дж., Динг Дж., Шит, П., и Абекасис, Г. Р. (2010). MaCH: использование данных о последовательности и генотипе для оценки гаплотипов и ненаблюдаемых генотипов. Genet. Эпидемиол. 34, 816–834. DOI: 10.1002 / gepi.20533
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Малхотра А., Кобес С., Богардус К., Ноулер В. К., Байер Л. Дж. И Хэнсон Р. Л. (2014). Оценка точности вменения генотипа у американских индейцев. PLoS One 9: e102544. DOI: 10.1371 / journal.pone.0102544
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Матиас, Р. А., Тауб, М. А., Жинью, К. Р., Фу, В., Мушарофф, С., О’Коннор, Т. Д., и др. (2016). Континуум примесей в западном полушарии, выявленный геномом африканской диаспоры. Нат. Commun. 11: 12522. DOI: 10.1038 / ncomms12522
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Маккарти, С., Дас, С., Кречмар, В., Делано, О., Вуд, А. Р., Тьюмер, А., и другие. (2016). Контрольная панель из 64 976 гаплотипов для вменения генотипа. Нат. Genet. 48, 1279–1283. DOI: 10,1038 / нг.3643
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Нельсон, С.С., Стилп, А.М., Папаниколау, Дж. Дж., Тейлор, К. Д., Роттер, Дж. И., Торнтон, Т. А., и др. (2016). Повышенная точность вменения в испаноязычных / латиноамериканских популяциях с более крупными и разнообразными контрольными панелями: приложения в исследовании здоровья латиноамериканского сообщества / исследовании латиносов (HCHS / SOL). Гум. Мол. Genet. 1, 3245–3254. DOI: 10.1093 / hmg / ddw174
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Перселл С., Нил Б., Тодд-Браун К., Томас Л., Феррейра М. А. Р., Бендер Д. и др. (2007). PLINK: набор инструментов для анализа ассоциации всего генома и популяционного анализа сцепления. Am. J. Hum. Genet. 81, 559–575. DOI: 10.1086 / 519795
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Рошьяра, Н.Р., Хорн, К., Кирстен, Х., Анерт, П., и Шольц, М. (2016). Сравнение эффективности современных методов вменения генотипов у разных национальностей. Sci. Реп. 4: 34386. DOI: 10.1038 / srep34386
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Шурц, Х., Киннер, К. Дж., Жинью, К. Р., Войчик, Г. Л., Хелден, П. Д., ван Тромп, Г. С. и др. (2018). Исследование ассоциации туберкулеза с разбивкой по половому признаку на весь геном с использованием многоэтнического набора генотипов. BIORXIV. 31: 405571. DOI: 10.1101 / 405571
CrossRef Полный текст | Google Scholar
Sudmant, P.H., Rausch, T., Gardner, E.J., Handsaker, R.E., Abyzov, A., Huddleston, J., et al. (2015). Интегрированная карта структурных вариаций в 2 504 геномах человека. Природа 1, 75–81. DOI: 10.1038 / природа15394
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Вергара, К., Паркер, М. М., Франко, Л., Чо, М. Х., Валенсия-Дуарте, А. В., Бити, Т.H., et al. (2018). Производительность вменения генотипа трех контрольных панелей с использованием лиц африканского происхождения. Гум. Genet. 137, 281–292. DOI: 10.1007 / s00439-018-1881-4
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Верма, С.С., де Андраде, М., Тромп, Г., Куйваниеми, Х., Пью, Э., Намджу-Халес, Б. и др. (2014). Шаги вменения и контроля качества для объединения нескольких наборов данных по всему геному. Фронт. Genet. 5: 370.